XSS漏洞:一道关于DOM型XSS的题目
目录
xss系列往期文章:
XSS漏洞:利用多次提交技巧实现存储型XSS攻击-CSDN博客
前面对于XSS的三种类型中的反射型XSS和存储型XSS都分别做了一些演示,那么在本篇文章中将会使用一道题目来进行DOM型XSS攻击进行一个演示
声明:本题中使用的案例和方法都是别的大佬总结好的,我只是在本篇中进行学习+练习

那么现在开始,故事的开始还是要从一段Javascript代码说起
<script>
const data = decodeURIComponent(location.hash.substr(1));;
const root = document.createElement('div');
root.innerHTML = data;
// 这里模拟了XSS过滤的过程,方法是移除所有属性,sanitizer
for (let el of root.querySelectorAll('*')) {
let attrs = [];
for (let attr of el.attributes) {
attrs.push(attr.name);
}
for (let name of attrs) {
el.removeAttribute(name);
}
}
document.body.appendChild(root);
</script>从上面的代码中可以看到这是个明显的DOM XSS,用户的输入会构成一个新div元素的子结点,但在插入body之前会被移除所有的属性。
那么我来试试看传入一个弹窗代码会发生什么事情:

很明显,传入的弹窗代码没有执行,在执行前属性被删除了。
那么我们现在如果想要进行DOM型XSS攻击就必须要解决这个问题,如果才能绕过这个限制来执行恶意的JS代码
解法1:SVG标签
想要理解第一个解法是如何实现的就必须要了解一下DOM树的构建
DOM树的构建
我们知道JS是通过DOM接口来操作文档的,而HTML文档也是用DOM树来表示。
所以在浏览器的渲染过程中,我们最关注的就是DOM树是如何构建的。
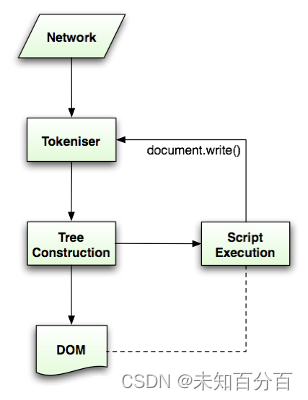
解析一份文档时,先由标记生成器做词法分析,将读入的字符转化为不同类型的Token,然后将Token传递给树构造器处理;接着标识识别器继续接收字符转换为Token,如此循环。
实际上对于很多其他语言,词法分析全部完成后才会进行语法分析(树构造器完成的内容),但由于HTML的特殊性,树构造器工作的时候有可能会修改文档的内容,因此这个过程需要循环处理。
在树构建过程中,遇到不同的Token有不同的处理方式。
具体的判断是在HTMLTreeBuilder::ProcessToken(AtomicHTMLToken* token)中进行的。
AtomicHTMLToken是代表Token的数据结构,包含了确定Token类型的字段,确定Token名字的字段等等。Token类型共有7种
kStartTag代表开标签kEndTag代表闭标签kCharacter代表标签内的文本。
所以一个<script>alert(1)</script>会被解析成3个不同种类的Token,分别是kStartTag、kCharacter和kEndTag。
在处理Token的过程中,还有一个InsertionMode的概念,用于判断和辅助处理一些异常情况。
在处理Token的时候,还会用到HTMLElementStack,一个栈的结构。
当解析器遇到开标签时,会创建相应元素并附加到其父节点,然后将token和元素构成的Item压入该栈。
遇到一个闭标签的时候,就会一直弹出栈直到遇到对应元素构成的item为止,这也是一个处理文档异常的办法。
下面举个例子来理解一下上面晦涩难懂的概念:
比如<div><p>1</div>会被浏览器正确识别成<div><p>1</p></div>正是借助了栈的能力,也就是浏览器的纠错能力,它会将未闭合的标签自动闭合
而当处理script的闭标签时,除了弹出相应item,还会暂停当前的DOM树构建,进入JS的执行环境。换句话说,在文档中的script标签会阻塞DOM的构造。
这里简单的理解就是在构建DOM时每当遇到js就会先暂停了去执行js代码,然后再回过头来进行DOM树的构建)
img标签没有执行成功原因
我们注释掉过滤的代码后使用单部调试的方法来看看我们传入的js代码经历了怎么的过程

首先我们可以测试一下不使用断点的情况下进行传入弹窗代码,发现是正常弹窗的

现在打断点后再次查看
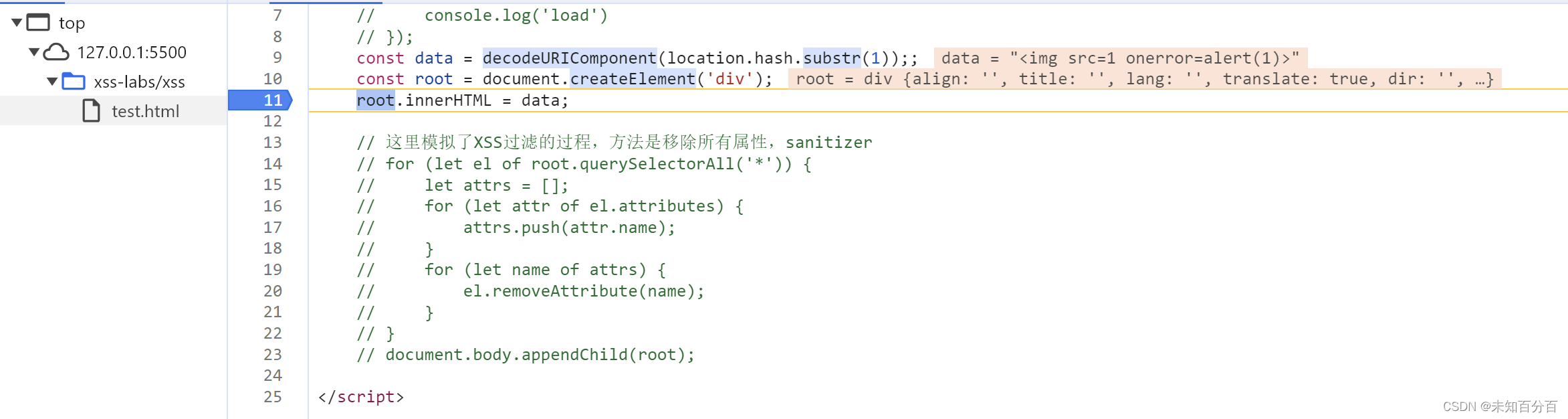

可以看到即使在代码已经传入到data中后,到了script标签的结尾位置还是没有进行弹窗,再往后面进行单步调试发现到最后一步alert(1)出现后的单步调试才进行弹窗
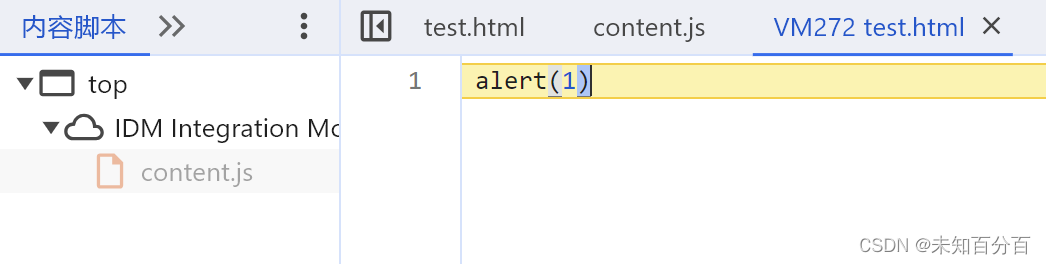
 ?那么这里就很明显的发现了一个问题,
?那么这里就很明显的发现了一个问题,alert(1)是在页面上script标签中的代码全部执行完毕以后才被调用的。这也验证了我们上面所说的DOM树的执行过程,为了进一步验证这一点我将下面的代码加入到源代码中,查看执行结果来验证:
window.addEventListener("DOMContentLoaded", (event) => {
console.log('DOMContentLoaded')
});
window.addEventListener("load", (event) => {
console.log('load')
});这里就是两个监听事件,然后分别将事件打印了出来,我可以在这里试着传入恶意代码来打印一个值,查看它的执行顺序会发现我们传入的值是第二个打印的,
 最后我也是通过断点调试的方式进行一下查看,发现在DOMCOntentLoaded打印完毕后,我们的js代码进行执行,执行完成后才打印的load,那么失败的原因也很明显了,由于js阻塞dom树,一直到js语句执行结束后,才可以引入img,此时img的属性已经被sanitizer清除了,自然也不可能执行事件代码了。
最后我也是通过断点调试的方式进行一下查看,发现在DOMCOntentLoaded打印完毕后,我们的js代码进行执行,执行完成后才打印的load,那么失败的原因也很明显了,由于js阻塞dom树,一直到js语句执行结束后,才可以引入img,此时img的属性已经被sanitizer清除了,自然也不可能执行事件代码了。
因此现在就要想办法在清除标签的属性前来执行代码
svg标签执行成功的原因
这里就要介绍一下别的大神想到这个payload了
<svg><svg src=1 onload-alert(1)></svg>
那么来试试看:
成功的弹窗了
上面我们使用了写了两次svg标签的方式来进行了弹窗居然就成功了,那么下面可以试试使用单点调试的方式看看执行的顺序:
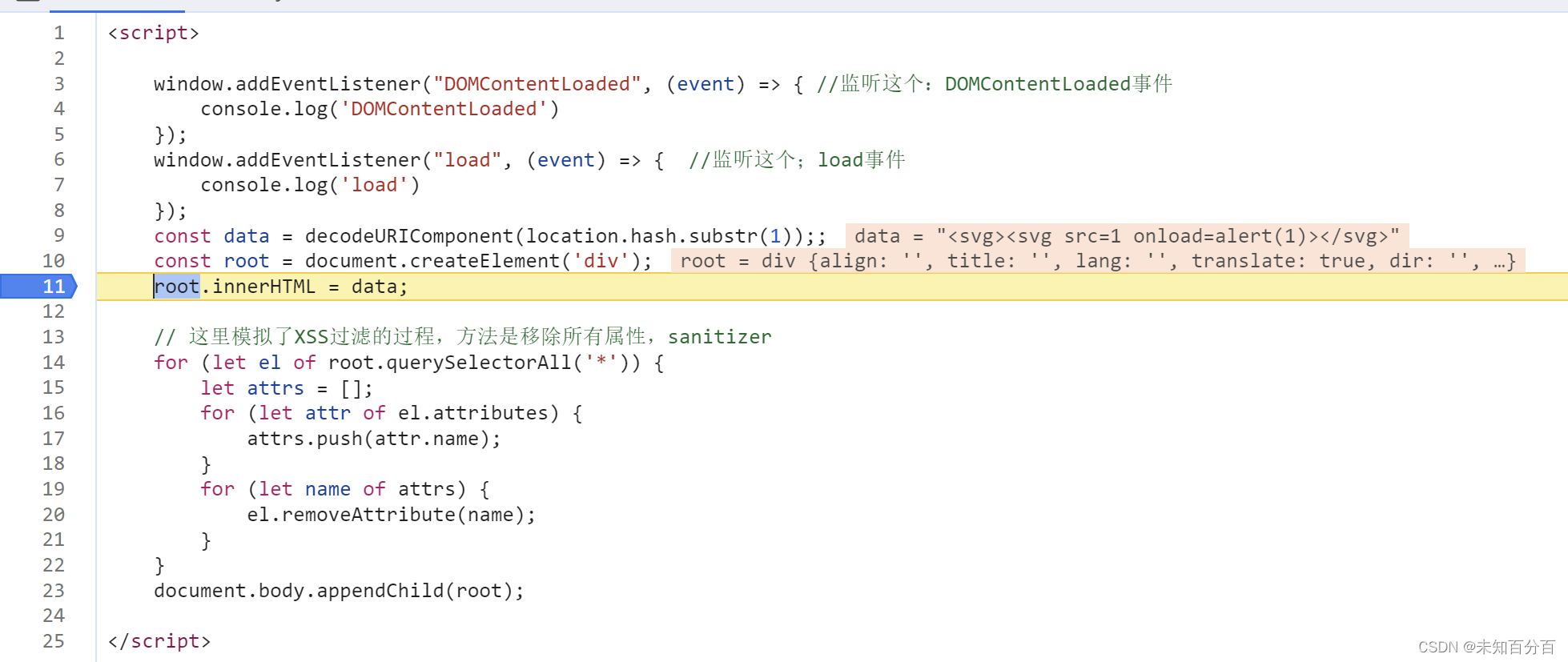
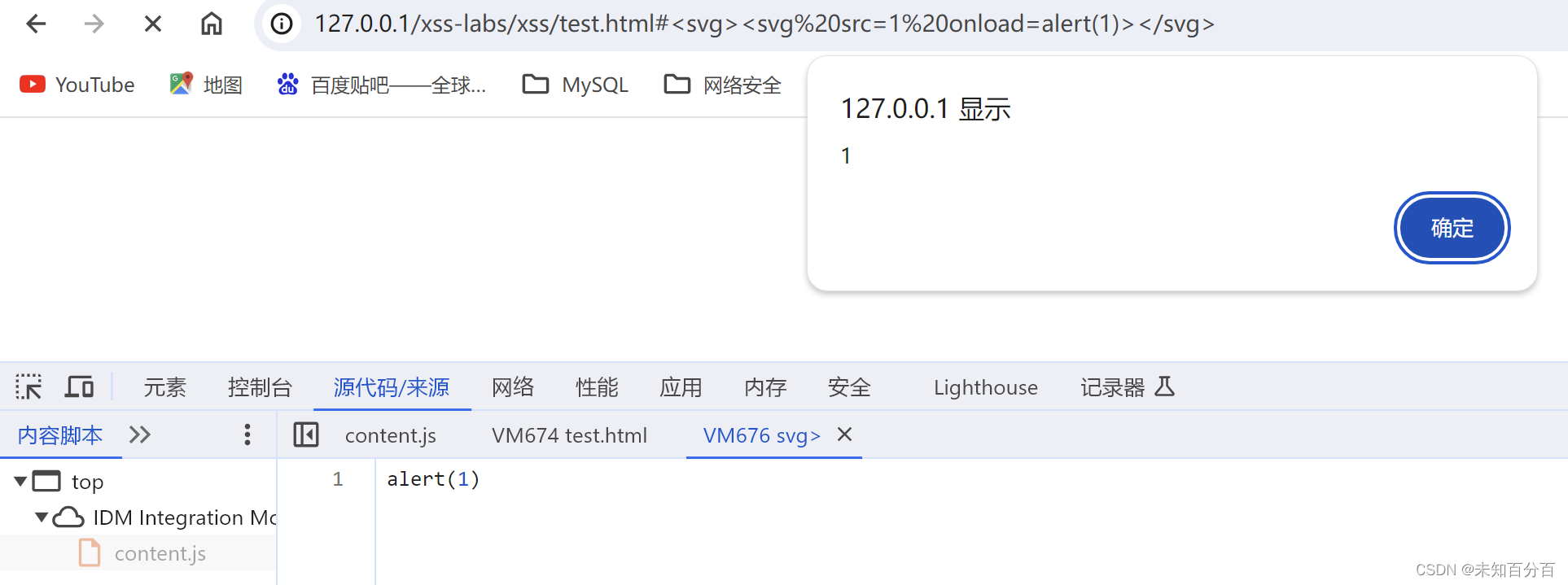
我们在点击了两次单步调试后就成功的弹窗了,说明这里在我们的svg标签执行删除操作前这个标签已经执行了
那么既然这里的两个svg是可以执行成功的,那么如果是一个svg呢?会不会执行成功
来尝试一下:

可以看到,一个svg标签是无法进行弹窗的
那为什么多了一个svg套嵌就可以提前执行呢?带着这个疑问,我们来看一下浏览器是怎么处理的。
void HTMLElementStack::PopAll() { //没有正确闭合时调用
root_node_ = nullptr;
head_element_ = nullptr;
body_element_ = nullptr;
stack_depth_ = 0;
while (top_) {
Node& node = *TopNode();
auto* element = DynamicTo<Element>(node);
if (element) {
element->FinishParsingChildren();
if (auto* select = DynamicTo<HTMLSelectElement>(node))
select->SetBlocksFormSubmission(true);
}
top_ = top_->ReleaseNext();
}
}
void HTMLElementStack::PopCommon() {//正确闭合时调用
DCHECK(!TopStackItem()->HasTagName(html_names::kHTMLTag));
DCHECK(!TopStackItem()->HasTagName(html_names::kHeadTag) || !head_element_);
DCHECK(!TopStackItem()->HasTagName(html_names::kBodyTag) || !body_element_);
Top()->FinishParsingChildren();
top_ = top_->ReleaseNext();
stack_depth_--;
}当我们没有正确闭合标签的时候,如<svg><svg>,就可能调用到PopAll来清理;
而正确闭合的标签就可能调用到其他出栈函数并调用到PopCommon。
这两个函数有一个共同点,都会调用栈中元素的FinishParsingChildren函数。
这个函数用于处理子节点解析完毕以后的工作。
因此,我们可以查看svg标签对应的元素类的这个函数。
void SVGSVGElement::FinishParsingChildren() { //两个函数都会调用这个函数
SVGGraphicsElement::FinishParsingChildren();
// The outermost SVGSVGElement SVGLoad event is fired through
// LocalDOMWindow::dispatchWindowLoadEvent.
if (IsOutermostSVGSVGElement()) //是否是最外层的svg
return;
// finishParsingChildren() is called when the close tag is reached for an
// element (e.g. </svg>) we send SVGLoad events here if we can, otherwise
// they'll be sent when any required loads finish
SendSVGLoadEventIfPossible(); //很明显我们使用的两个就会来到这里
}这里有一个非常明显的判断IsOutermostSVGSVGElement,如果是最外层的svg则直接返回。
注释也告诉我们了,最外层svg的load事件由LocalDOMWindow::dispatchWindowLoadEvent触发;而其他svg的load事件则在达到结束标记的时候触发。
所以我们跟进SendSVGLoadEventIfPossible进一步查看。
bool SVGElement::SendSVGLoadEventIfPossible() { //这个函数会执行load事件
if (!HaveLoadedRequiredResources())
return false;
if ((IsStructurallyExternal() || IsA<SVGSVGElement>(*this)) &&
HasLoadListener(this))
DispatchEvent(*Event::Create(event_type_names::kLoad));
return true;
}这个函数是继承自父类SVGElement的,可以看到代码中的DispatchEvent(*Event::Create(event_type_names::kLoad));确实触发了load事件,而前面的判断只要满足是svg元素以及对load事件编写了相关代码即可,也就是说在这里执行了我们写的onload=alert(1)的代码。
那么可以试着多传入几层svg标签来验证一下:
可以看到结果不出所料,最内层的svg先触发,然后再到下一层,而且是在DOM树构建完成以前就触发了相关事件;
?总结
img和其他payload的失败原因在于sanitizer执行的时间早于事件代码的执行时间,sanitizer将恶意代码清除了。
套嵌的svg之所以成功,是因为当页面为root.innerHtml赋值的时候浏览器进入DOM树构建过程;在这个过程中会触发非最外层svg标签的load事件,最终成功执行代码。
解法2:details标签
上面的代码还有第二种解法,就是使用details标签
这里直接展示大佬的pyload:
`<details open ontoggle=alert(1)>`来尝试一下:?

可以看到这里确实可以弹窗
下面就分析一下这个pylaod可以执行成功的原因
事件触发流程
首先触发代码的点是在DispatchPendingEvent函数里
void HTMLDetailsElement::DispatchPendingEvent(
? ?const AttributeModificationReason reason) {
?if (reason == AttributeModificationReason::kByParser)
? ?GetDocument().SetToggleDuringParsing(true);
?DispatchEvent(*Event::Create(event_type_names::kToggle));
?if (reason == AttributeModificationReason::kByParser)
? ?GetDocument().SetToggleDuringParsing(false);
}而这个函数是在ParseAttribute被调用的
void HTMLDetailsElement::ParseAttribute(
? ?const AttributeModificationParams& params) {
?if (params.name == html_names::kOpenAttr) {
? ?bool old_value = is_open_;
? ?is_open_ = !params.new_value.IsNull();
? ?if (is_open_ == old_value)
? ? ?return;
?
? ?// Dispatch toggle event asynchronously.
? ? ?异步调度事件
? ?pending_event_ = PostCancellableTask( //回调函数
? ? ? ?*GetDocument().GetTaskRunner(TaskType::kDOMManipulation), FROM_HERE,
? ? ? ?WTF::Bind(&HTMLDetailsElement::DispatchPendingEvent,
? ? ? ? ? ? ? ? ?WrapPersistent(this), params.reason));
?
? ....
?
? ?return;
}
?HTMLElement::ParseAttribute(params);
}ParseAttribute正是在解析文档处理标签属性的时候被调用的。
注释也写到了,分发toggle事件的操作是异步的。
可以看到下面的代码是通过PostCancellableTask来进行回调触发的,并且传递了一个TaskRunner。
TaskHandle PostCancellableTask(base::SequencedTaskRunner& task_runner,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? const base::Location& location,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? base::OnceClosure task) {
?DCHECK(task_runner.RunsTasksInCurrentSequence());
?scoped_refptr<TaskHandle::Runner> runner =
? ? ?base::AdoptRef(new TaskHandle::Runner(std::move(task)));
?task_runner.PostTask(location,
? ? ? ? ? ? ? ? ? ? ? WTF::Bind(&TaskHandle::Runner::Run, runner->AsWeakPtr(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? TaskHandle(runner)));
?return TaskHandle(runner);
}跟进PostCancellableTask的代码则会发现,回调函数(被封装成task)正是通过传递的TaskRunner去派遣执行。
清楚调用流程以后,就可以思考,为什么无法触发这个事件呢?最大的可能性,就是在任务交给TaskRunner以后又被取消了。
因为是异步调用,而且PostCancellableTask这个函数名也暗示了这一点。
总结
所以我们可以得到结论,details标签的toggle事件是异步触发的,并且直接对details标签的移除不会清除原先通过属性设置的异步任务。
解法3:Dom-Clobbring
第三种解法就是Dom-Clobbring,也就是DOM劫持
由于非标准化的 DOM 行为,浏览器有时可能会向各种 DOM 元素添加 name & id 属性,作为对文档或全局对象的属性引用,但是,这会导致覆盖掉 document原有的属性或全局变量,或者劫持一些变量的内容,而且不同的浏览器还有不同的解析方式,所以本文的内容如果没有特别标注,均默认在 Chrome 80.0.3987.116 版本上进行。
Dom Clobbering 就是一种将 HTML 代码注入页面中以操纵 DOM 并最终更改页面上 JavaScript 行为的技术。 在无法直接 XSS 的情况下,我们就可以往 DOM Clobbering 这方向考虑了。
一个简单的例子来了解DOM劫持
我们构造下面的代码来查看一下这个结果:
<img id="x">
<img name="y">
<script>
console.log(x);
console.log(y);
console.log(document.x);
console.log(document.y);
console.log(window.x);
console.log(window.y);
</script>
可以看到使用这种方式只有document.x没有拿到id =x的标签,其余都拿到了id=x/name=y的标签
?那么是不是可以利用document和window的这样一个特点来搞事情呢?
下面再做一个测试:
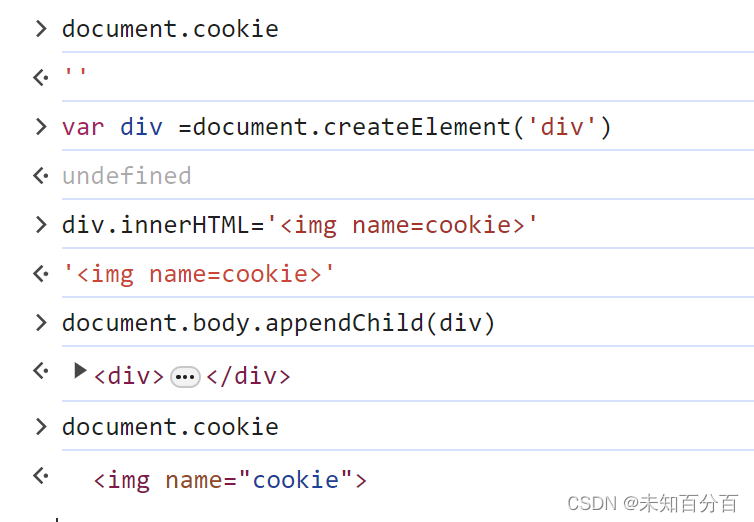
可以看到这里我们先查看了document.cookie中的值,是空的,后面创建了一个div,将<img name=cookie>插入到div标签中看,然后将div追加到document.body中,再次查看document.cookie就拿到了name=cookie的标签
再来举一个例子:
<form name="body">
<img id="appendChild">
</form>
<script>
var div = document.createElement('div');
document.body.appendChild(div);
</script> ?
?
可以看到我们通过多层覆盖掉了document.body.appendChild方法。
所以它就会报错说这不是一个函数,因为我们覆盖了这个元素将其替换为了img标签
外层form name=body ,内层img id =appendChild 然后再次创建一个div,将div插入到body中
但是却无法插入,因为我们上面将body作为form的name的值了,变成了img
(这里就把body标签劫持了,现在document.body.appendChild=img)
既然我们可以通过这种方式去创建或者覆盖 document 或者 window 对象的某些值,但是看起来我们举的例子只是利用标签创建或者覆盖最终得到的也是标签,是一个HTMLElment对象。
但是对于大多数情况来说,我们可能更需要将其转换为一个可控的字符串类型,以便我们进行操作。
toString
所以我们可以通过以下代码来进行 fuzz 得到可以通过toString方法将其转换成字符串类型的标签:
Object.getOwnPropertyNames(window)
.filter(p => p.match(/Element$/))
.map(p => window[p])
.filter(p => p && p.prototype && p.prototype.toString !== Object.prototype.toString)
我们可以得到两种标签对象:
HTMLAreaElement (<area>)& HTMLAnchorElement (<a>),
这两个标签对象我们都可以利用href属性来进行字符串转换。
<body>
<a id="test" href="http://xianoupeng.com">aaa</a>
</body>
<script>
alert(test)
</script>
?可以看到是成功弹窗的
但是如果我们需要的是x.y这种形式呢?两层结构我们应该怎么办呢?我们可以尝试上述的办法:
<div id=x>
<a id=y href='www.xianoupeng.com'></a>
</div>
<script>
alert(x.y);
</script>
这里无论第一个标签怎么组合,得到的结果都只是undefined。
但是我们可以通过另一种方法加入引入 name 属性就会有其他的效果。
<div id=x>
<a id=y href='www.xianoupeng.com'></a>
</div>
<script>
alert(x.y);
</script>注:两个id,里面的标签写一个name,可以使用列表.name的形式取出内部的标签
再者,我们也可以通过利用 HTML 标签之间存在的关系来构建层级关系。
var log=[];
var html = ["a","abbr","acronym","address","applet","area","article","aside","audio","b","base","basefont","bdi","bdo","bgsound","big","blink","blockquote","body","br","button","canvas","caption","center","cite","code","col","colgroup","command","content","data","datalist","dd","del","details","dfn","dialog","dir","div","dl","dt","element","em","embed","fieldset","figcaption","figure","font","footer","form","frame","frameset","h1","head","header","hgroup","hr","html","i","iframe","image","img","input","ins","isindex","kbd","keygen","label","legend","li","link","listing","main","map","mark","marquee","menu","menuitem","meta","meter","multicol","nav","nextid","nobr","noembed","noframes","noscript","object","ol","optgroup","option","output","p","param","picture","plaintext","pre","progress","q","rb","rp","rt","rtc","ruby","s","samp","script","section","select","shadow","slot","small","source","spacer","span","strike","strong","style","sub","summary","sup","svg","table","tbody","td","template","textarea","tfoot","th","thead","time","title","tr","track","tt","u","ul","var","video","wbr","xmp"], logs = [];
div=document.createElement('div');
for(var i=0;i<html.length;i++) {
for(var j=0;j<html.length;j++) {
? div.innerHTML='<'+html[i]+' id=element1>'+'<'+html[j]+' id=element2>';
? document.body.appendChild(div);
? if(window.element1 && element1.element2){
? ? ? log.push(html[i]+','+html[j]);
? }
? document.body.removeChild(div);
}
}
console.log(log.join('\n')); ?
?
以上代码测试了现在 HTML5 基本上所有的标签,使用两层的层级关系进行 fuzz ,注意这里只使用了id,并没有使用name,遇上文的HTMLCollection并不是一种方法。
我们可以得到的是以下关系:
form->button
form->fieldset
form->image
form->img
form->input
form->object
form->output
form->select
form->textarea如果我们想要构建x.y的形式,我们可以这么构建:
<form id=x><output id=y>I've been clobbered</output>
<script>
alert(x.y.value);
</script>
<!-- 注:这里id,id name,name name,id id,name都可以劫持 --> ?
?
三级的层级关系我们就需要用到以上两种技巧来构建了
<form id="x" name="y"><output id=z>I've been clobbered</output></form>
<form id="x"></form>
<script>
alert(x.y.z.value);
</script>
三层关系,父级id + name 子集的id这个也比较简单,先用一个HTMLCollection获取第二级,再在第一个表单中用output标签即可。
解决问题
那么现在我们已经对Dom劫持已经有了基本的了解了,下面就使用DOM劫持来解决一下最开始的问题吧:
payload:
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true > <img id=attributes><img id=attributes></form>
成功弹窗!!!
到此,三种解决方式都已经演示完毕了,XSS的三种类型也都演示完毕了,还有一些比较难的靶场并没有通关和练习,后面学习了之后再和大家分享(^▽^)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 网络安全产品之认识防毒墙
- 绩效沟通不到位,60%的企业都吃过亏
- 【QT+QGIS跨平台编译】之二:【zlib+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
- Java序列化
- TCP/UDP 的特点、区别及优缺点
- YOLOv7原创改进:一种新颖的跨通道交互的高效率通道注意力EMCA,ECA注意力改进版
- 软件测试必备的Linux知识(一)
- Vue3+TS TypeScript知识点
- 面试算法87:恢复IP地址
- GitHub项目推荐-incubator