【遇见Transformer】Transformer代码、原理全方位解析,相信我,看这一篇就够了!
目录
前言
预备知识
在开始本章节之前可能需要学习以下知识:
什么是自然语言处理(NLP)什么是循环神经网络(RNN、LSTM【长短期记忆循环】、GRU【门控循环】)
什么是大模型(具有较大规模和复杂性的模型)
了解OpenAI、谷歌、等相关公司、企业
本章代码环境
操作系统:不限
python:3.8
框架:pytorch(torch==1.10.2)
是否需要GPU:无要求
关注我,不迷路 !
QQ:1757093754?
公众号:(搜“我叫人工智能”)

Transformer模型的结构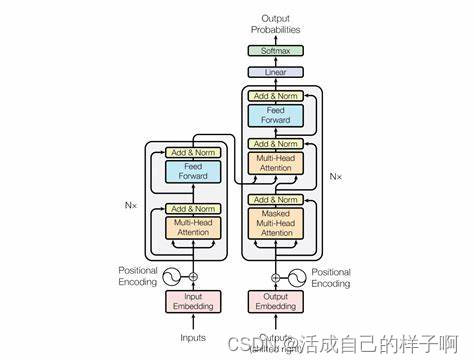
-
位置编码(Positional Encoding):
- Transformer没有明确的序列结构概念,因此需要通过添加位置编码来为模型提供输入序列中单词的相对位置信息。位置编码是可学习的或预定义的。
- Transformer中的位置编码的表示:(pos表示位置,i表示向量维度的索引)
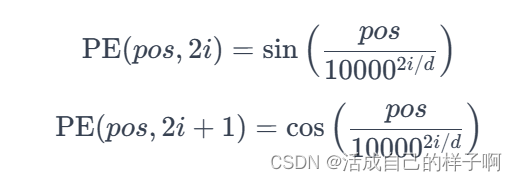
-
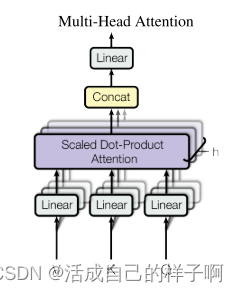
多头自注意力机制(Multi-Head Attention):
- 这是Transformer的核心机制之一。通过多个注意力头,模型能够在不同子空间中学习不同的关系。自注意力机制使模型能够对输入序列的不同位置分配不同的注意力权重。
- 多头自注意力机制机制的步骤:
- 输入变换(Input Transformation):对输入序列进行线性变换,分别产生多组投影矩阵,用于后续每个注意力头的计算。这个投影过程涉及三个权重矩阵:Query(查询): 将输入序列通过一个可学习的线性变换,得到Query矩阵。Key(键): 将输入序列通过另一个可学习的线性变换,得到Key矩阵。Value(值): 将输入序列通过第三个可学习的线性变换,得到Value矩阵。
- 多头并行计算(Parallel Computation):对于每个注意力头,计算注意力权重。这是通过将Query和Key进行点积运算,然后应用缩放操作(为了稳定训练,一般会除以特征维度的平方根),最后使用Softmax函数得到的注意力分布来完成的。将每个头的注意力权重与对应的Value矩阵相乘,得到每个位置的加权和。这个过程实际上就是每个头对输入序列进行关注的结果。
-
头的拼接(Concatenation of Heads):将多个注意力头的输出拼接在一起,形成一个更高维的输出向量。这样,模型能够同时捕捉多个不同方面的关系。
-
输出变换(Output Transformation):将拼接后的结果通过一个可学习的线性变换(通常是矩阵乘法和加法),生成最终的多头自注意力机制的输出。
-
残差连接(ADD)(Residual Connection):
- 在每个子层(如自注意力层和前馈神经网络层)之后都添加了残差连接,有助于缓解梯度消失问题,并使训练更加稳定。
- 残差连接存在的原因(NEW!!!):
- 梯度消失:在深度神经网络中,通过多个层传播的梯度可能会变得非常小,甚至趋近于零。这导致在训练较深的网络时,底层的权重更新几乎没有贡献,使得网络学习变得非常缓慢或停滞。残差连接通过提供跨层的捷径,允许梯度直接通过跳跃连接传播,从而减轻了梯度消失问题。
-
梯度爆炸:另一方面,梯度也可能因为某些原因变得非常大,导致权重更新过大,网络不稳定。残差连接通过提供一个额外的路径,使得梯度能够绕过较深层,从而有助于缓解梯度爆炸问题。
-
层归一化(Norm)(Layer Normalization):
- 在每个子层输出后应用层归一化,以规范化激活值,促进模型的稳定性。
- LayerNorm:

-
前馈神经网络(Feedforward Neural Network):
- 在每个编码器和解码器层中,都有一个前馈神经网络。它对每个位置的向量进行独立的变换,包括一个隐藏层和一个激活函数。
- 这里的前馈神经网络通常使用的是基于全连接层的神经网络(Linear+Relu)
-
编码器(Encoder)和解码器(Decoder):
- Transformer模型分为编码器和解码器两个部分。编码器用于处理输入序列,解码器用于生成输出序列。每个部分都包含多个相同的层。
- 注意区分的是,编码器部分(Encoder)使用的是多头自注意力机制,而解码器部分(Decoder)使用的是多头掩码自注意力机制。
-
注意力掩码(Attention Masking):
- 在解码器的自注意力层中,为了防止信息泄漏,通常会使用注意力掩码来使模型只能关注到当前位置及其之前的位置。
Transformer模型的基本原理
注意力机制
1.Q、K相乘(通常情况下)得到S,求相似度
2.softmax归一化
3.S、V相乘得到注意力
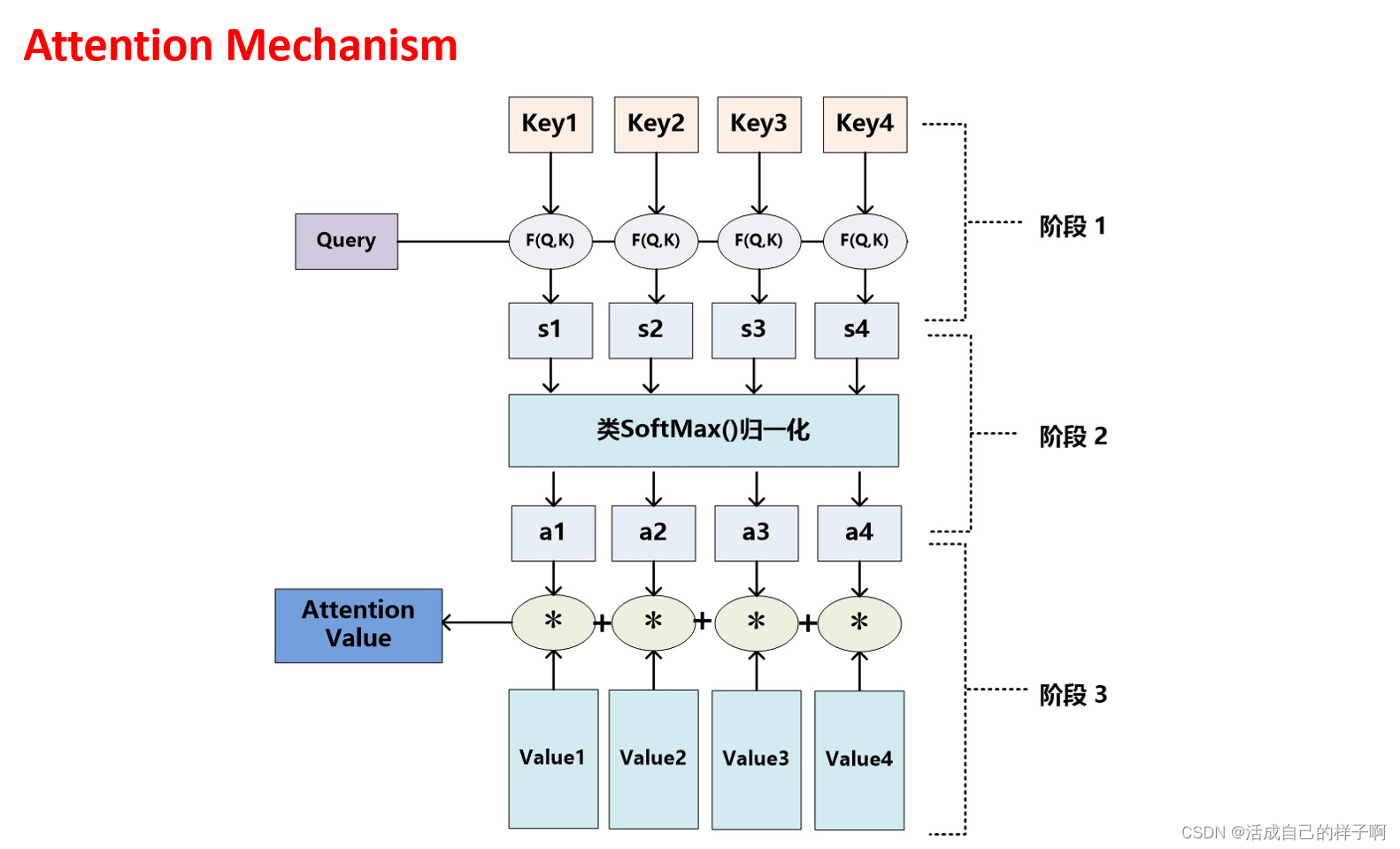
自注意力机制?
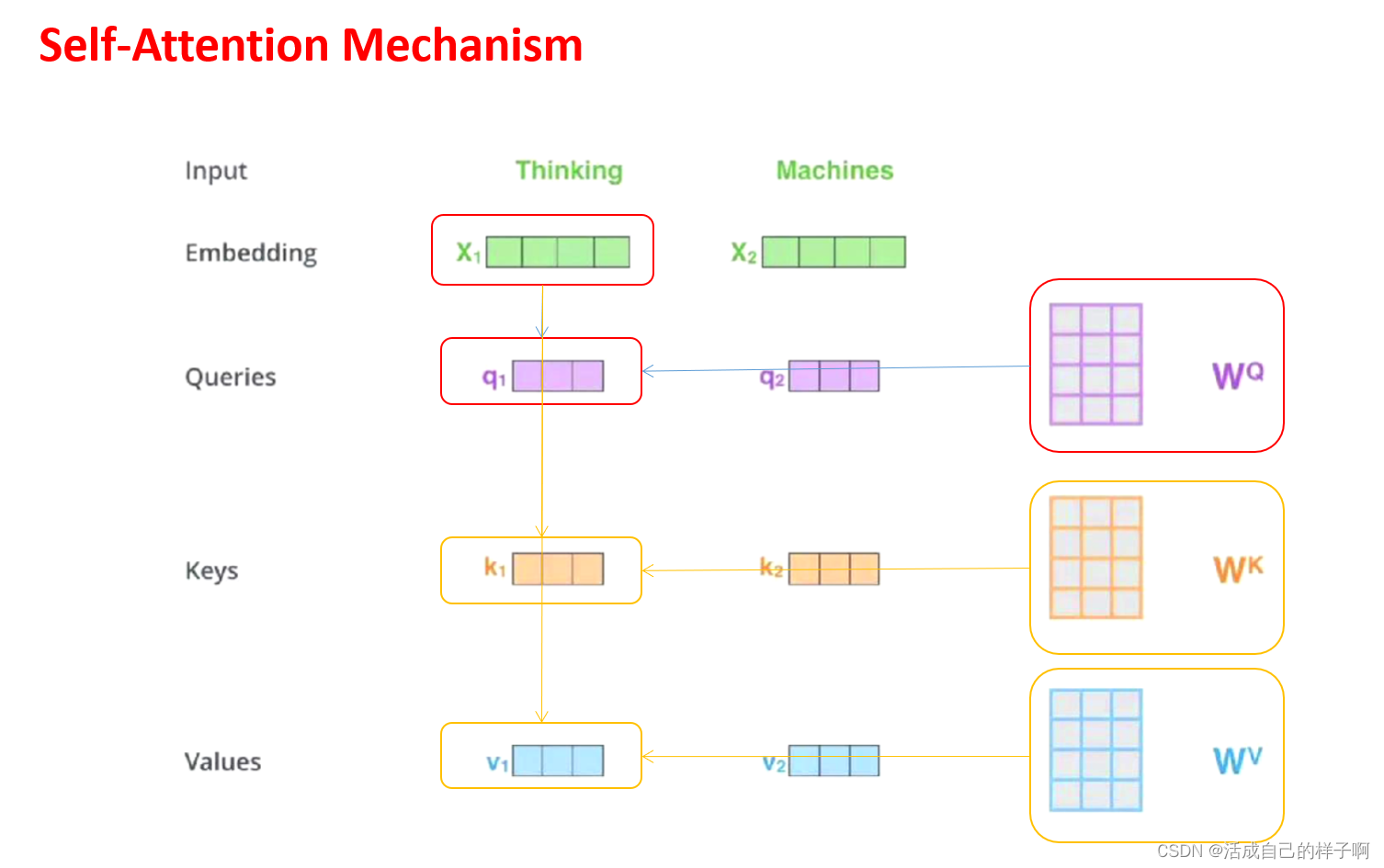

?两者的区别
-
注意力机制:
- Query 和 Key 来自不同的位置或序列。
- 适用于一般的关系建模任务,可以处理输入序列和上下文之间的关系。
-
自注意力机制:
- Query、Key 和 Value 来自同一个序列。
- 主要用于处理序列内部的关系,能够在序列内部不同位置之间建立关联。
多头注意力机制
Transformer模型的训练
显卡:8张 NVIDIA P100
训练时间:3.5天
数据集:WMT 2014 English-German dataset
Transformer模型的应用
-
机器翻译:
- 利用 Transformer 模型的编码器-解码器结构,机器翻译系统能够在不同语言之间进行高质量的翻译。Transformer 在机器翻译任务上的性能远超传统方法。
-
语言建模和文本生成:
- Transformer 模型在语言建模任务中表现出色,能够学习并生成高质量的文本。这种能力被广泛应用于自动摘要、文本生成、对话系统等领域。
-
问答系统:
- Transformer 模型在问答任务中取得了显著的成功,包括阅读理解和开放域问答。模型能够从文本中提取信息并回答用户提出的问题。
-
图像处理:
- Transformer 模型也被成功应用于计算机视觉任务,例如图像分类、目标检测、图像生成等。Vision Transformer(ViT)是一种将 Transformer 应用于图像处理的变种。
-
语音识别:
- Transformer 模型在语音识别领域也有所应用,能够处理音频序列并提取关键信息。这对于自然语言处理和语音交互任务非常重要。
-
推荐系统:
- Transformer 模型在推荐系统中被用于学习用户和物品之间的关系,从而提高推荐的准确性。它可以处理序列数据和用户行为序列。
-
化学和生物信息学:
- Transformer 模型被用于分子生成、化合物性质预测等化学和生物信息学任务。它能够学习分子结构之间的复杂关系。
论文地址
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 算法基础十四
- MySQL、Oracle、PostgreSQL 数据库备份用的 Shell 脚本
- SpringBoot框架介绍&数据库操作&Mybatis注入&JDBC注入
- LeetCode-轮转数组的三种方法(189)
- EfficientNet
- flutter 播放SVGA动图
- Vue+scss实现全局字体大小切换
- 56.Spring事务:事务四大特性
- 设计模式之备忘录模式【行为型模式】
- 玩客云Armbian 23.8.1 Bullseye安装Prometheus&Grafana