使用 PAI-Blade 加速 StableDiffusion Fine-Tuning
01
背景
Stable Diffusion 模型自从发布以来在互联网上发展迅猛,它可以根据用户输入的文本描述信息生成相关图片,用户也可以提供自己喜爱的风格的照片,来对模型进行微调。例如当我们输入 "A photo of sks dog in a bucket" ,StableDiffusion 模型会生成类似下面的图片:

02
PAI-Blade 加速 PyTorch 训练
PAI-Blade 使用编译优化技术提高 PyTorch 程序的执行效率,其代码已经开源在
Github: https://github.com/alibaba/BladeDISC.
PAI-Blade API
使用 PAI-Blade 对 PyTorch 程序进行加速非常简单,只需要在原有程序上插入两行代码即可:
# 1. import PAI-Blade Python package import torch_blade# 2. compile and accelerate 'model' performancemodel = torch.compile(backend='aot_disc')(model)for batch, label in data_loader(): output = model(**batch) loss = compute_loss(output, label) loss.backward() optimizer.step()
torch.compile(backend='aot_disc')(model) 使用 BladeDISC 作为 TorchDynamo 的编译器后端,加速 PyTorch 模型的的前向和反向计算,其中 model也可以是一段 PyTorch 实现的 Python 函数。
PAI-Blade 编译 Pipeline
TorchDynamo 将 PyTorch 程序记录到一个或多个 FX Graph 上,PAI-Blade 通过一系列 Pass 优化计算图的执行效率。
https://pytorch.org/docs/2.1/torch.compiler_deepdive.html
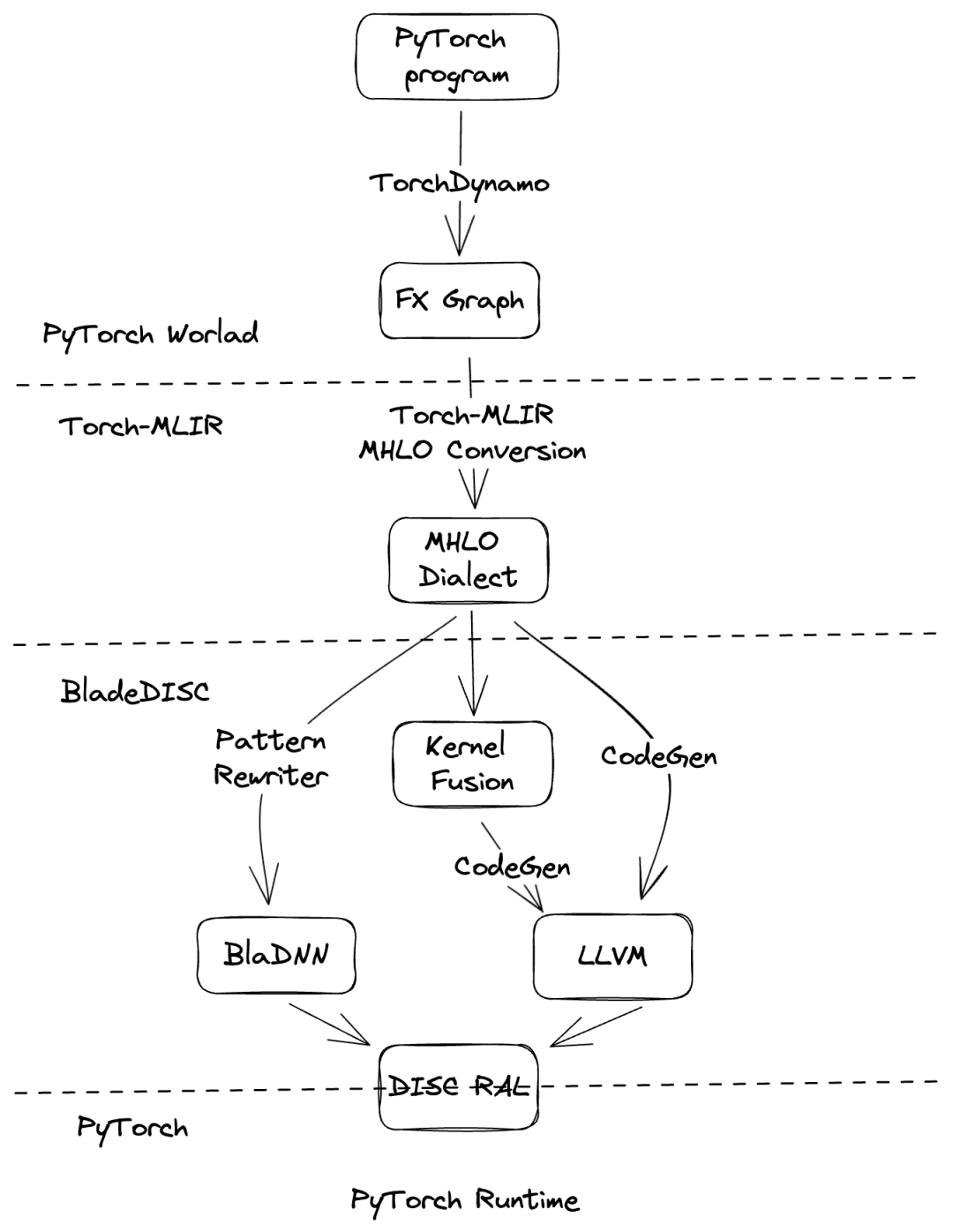
MHLO Conversion PAI-Blade 引入了 Torch-MLIR Project 将 PyTorch IR 转换为 MLIR 世界中的 MHLO Dialect,以便进一步使用 BladeDISC 编译器进行性能优化,同时 PAI-Blade 开发团队也将 MHLO 转换相关代码贡献给了社区。
https://github.com/llvm/torch-mlir
BlaDNN Library 提供了高性能计算密集型算子库,PAI-Blade 会根据计算图上的一些典型 Pattern,自动的将一部分子图替换为等价的,有极致性能的 BlaDNN 算子。
Memory Intensive Kernel Fusion
算子融合是图层面编译优化最重要的收益来源,一个典型的 workload 上,可能会包含 element-wise 算子,动态 shape 的 broadcast/reshape/reduce 算子以及计算密集型算子,例如 GEMM 等。在 PyTorch 中,每一个算子都是一个独立的 kernel,而过多的 kernel 会导致 Tensor 在 Cache 中频繁的交换,导致显存带宽的浪费,而频繁的发射 kernel 也会造成一定的额外的开销。
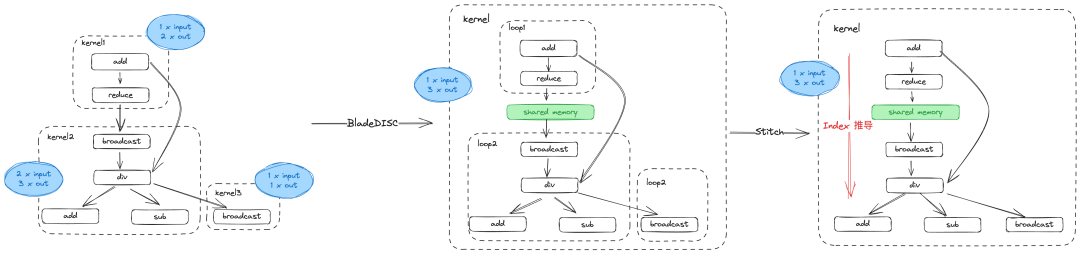
对于如上图的一个典型的访存类算子 workload ,类似 XLA 做法会将 schedule 相同的算子合并在一起,从而将 7 个 kernel 合并为 3 个 kernel。BladeDISC 会采用更为激进的 fusion 策略,从而进一步提高 workload 性能:
- 每个 fusion block 表示为独立的 ww 结构,使用 shared-memory 进行粘连,从而将 kernel 数量由 3 减少到 1
- 使用 AStitch 技术,将不同的 loop 结构黏贴在一起,通过 index 推导生成一个 loop 结构,同时引入了 index_cache, value_cache 消除冗余的 index 计算。
在上面 workload 中,BladeDISC 的 fusion 策略可以将 kernel 数量从 7 减少到 1,并且在 kernel 内部使用 index 推导和 cache 来减少冗余的计算,从而逼近硬件的理论峰值。
Inplace Mutation 优化
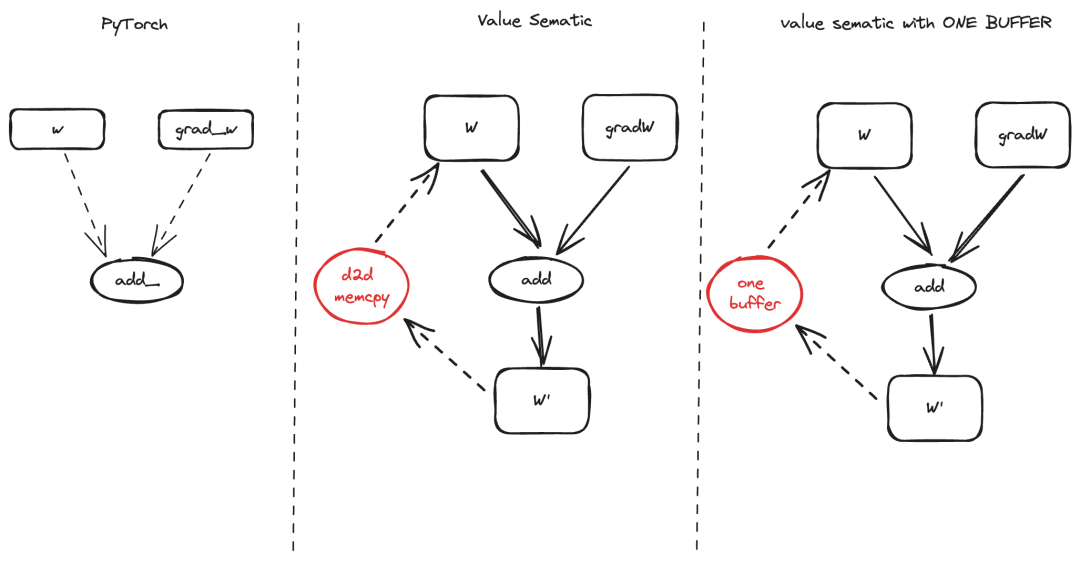
在 PyTorch Eager 模式下,通过 inplace 算子 (aten.add_) 可以实现对输入的 tensor (w) 进行更新,而不需要一个额外的输出 Tensor。但是在 MLIR 世界里,IR 必须是符合 SSA 形式的,所以没有办法直接表示 inplace 语义,通常的做法是增加一个 D2D memcpy 算子来将输出的 buffer (w') 覆盖输入 buffer (w)。但这样做会造成额外的一次显存拷贝。
BladeDISC 的做法是找到需要 inplace 更新的两个buffer,在 MHLO IR 上进行标记,将 w和 w' 标记为相同的 buffer,在生成 gpu.store指时,将输出直接写回 wbuffer,从而节省一次显存拷贝所造成的额外开销。
03
Benchmark


PAI-Blade 在 A10 和 A100 上最大可获得 41.6 % 和 28.4% 的性能收益(batchsize=1)。
04
在 DSW 上使用 PAI-Blade
- 在 PAI 平台中创建 DSW 实例,并使用如下自定义 Docker 镜像,具体步骤可以参考文档
https://help.aliyun.com/zh/pai/user-guide/overview-5
pai-blade-registry.cn-hangzhou.cr.aliyuncs.com/pai-blade/aicompiler:latest-stablediffusion-torch-2.0.1-cu118- 创建 Jupyter Notebook,启动 fine-tuning 任务
!cd /opt/StableDiffusion && bash launch_dreambooth_train.sh在看到如下日志时,表示微调任务执行完成:

- 启动推理任务,并在 Jupyter Notebook 中查看生成的图片
!cd /opt/StableDiffusion && python inference.py && cp dog-bucket.png /mnt/workspace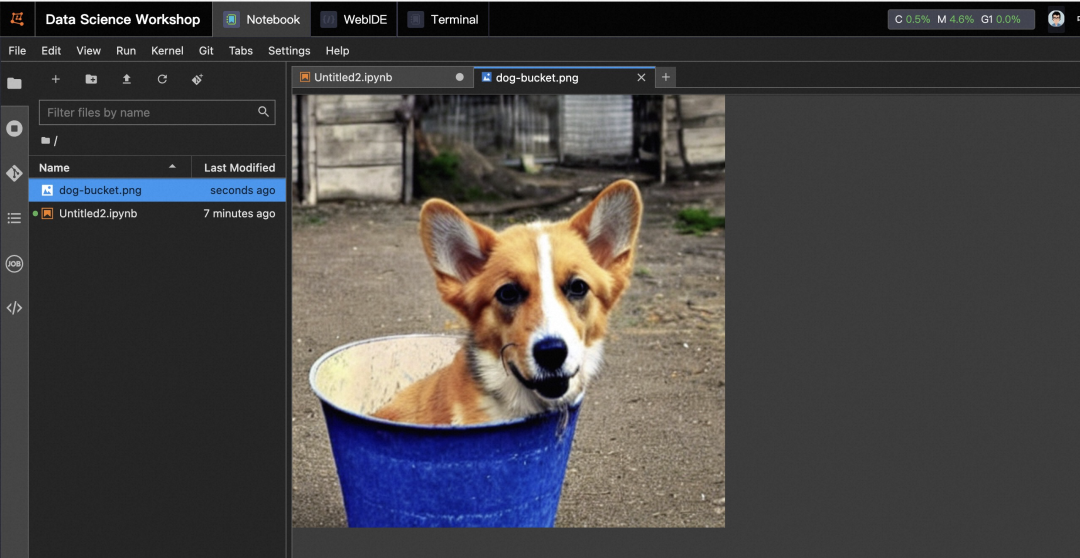
参考文档:
- BladeDISC:
https://github.com/alibaba/BladeDISC
- TorchDynamo:
https://pytorch.org/docs/2.1/torch.compiler_deepdive.html
- Torch-MLIR Project:
https://github.com/llvm/torch-mlir
- 文档:
https://help.aliyun.com/zh/pai/user-guide/overview-5
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Excel按月统计周数
- 性能测试-jemeter:安装 / 基础使用
- “让数据说话:AWS Big Data在企业中的价值”
- (第9天)SQLPlus 基础使用和进阶玩法
- Python调用js,Python执行js,pyexecjs2使用方法
- 如何加强FTP服务的安全性,解析不同的方法+上WAF
- 「Vue3面试系列」Vue 3.0中Treeshaking特性有哪些?举例说明一下?
- 【C++】特殊类 | 单例模式
- 一网打尽 this,对执行上下文说 Yes
- 软件测试中完整的Web请求流程