支持向量机(SVM):高效分类的强大工具
前言
支持向量机(Support Vector Machine,简称SVM)是一种强大的机器学习算法,广泛用于分类和回归问题。
其独特的优势在于能够有效地处理高维数据,并在复杂的数据集中实现准确的分类。
其优秀的性能和在复杂数据集上的适用性使其成为许多领域的首选工具之一,例如模式识别、数据分类和回归分析等领域。
1. SVM的基本原理
1.1 核心思想
支持向量机的核心思想是在特征空间中找到一个超平面(Hyperplane),将不同类别的数据点分隔开,同时最大化分类边界。
在二维空间中,超平面是一条直线;在三维空间中,它是一个平面。对于高维数据,超平面是一个(n-1)维的子空间。
这个超平面的选择是通过最大化支持向量到超平面的距离(即间隔(Margin))来实现的。这个距离的最大化使得分类器更加健壮,对未知数据的泛化能力更强。
这个超平面被称为“决策边界(Decision Boundary)”,而距离该边界最近的样本点被称为“支持向量(Support Vectors)”。
1.2 支持向量
支持向量是距离超平面最近的数据点,它们对于定义超平面和分类决策起着关键作用。SVM通过优化支持向量与超平面的距离,实现对数据的高效分类。
1.3 最大化建模
SVM旨在最大化分类边界的间隔。
通过最大化间隔,支持向量机可以更好地适应未见过的数据,具有较强的泛化能力。较大的间隔可以降低模型在训练集上的错误率,并减小了过拟合的风险。
由于支持向量机主要依赖于支持向量,它对于一些噪声点的存在具有一定的鲁棒性。通过最大化间隔,支持向量机能够更好地抵抗噪声和异常点的干扰,提高模型的健壮性。
最大化间隔可以使得决策边界更加清晰,减少了分类的歧义性。这使得支持向量机在处理复杂数据集时,更容易解释和理解。
通过找到最大间隔超平面,SVM能更好地适应未知数据并提高分类准确性。
1.4 松弛变量
在支持向量机中,引入松弛变量(Slack Variable)是为了处理线性不可分的情况。
在实际情况下,数据很少会严格线性可分,而松弛变量则允许一些数据点位于错误的一侧,但是在一个可接受的范围内。通过引入松弛变量,支持向量机可以更好地处理噪声、异常点或部分重叠的数据,克服了数据线性不可分的情况。
松弛变量可以用来调整间隔的大小,以平衡间隔的最大化和错误分类的惩罚。一般来说,对于每个样本点,松弛变量的值越小,表示它离正确的一侧越近,而值越大表示它离错误的一侧越近。通过最小化松弛变量的总和,支持向量机可以找到一个最优的决策边界,以实现模型的最佳分类效果。
1.5 核函数
支持向量机通过使用核函数将数据映射到高维空间,从而解决非线性分类问题。常用的核函数包括多项式核和高斯核,它们允许支持向量机在更复杂的空间中找到适当的超平面,提高分类的准确性。
2. SVM与逻辑回归的区别和联系
2.1 区别
- 核心原理: SVM旨在找到一个能够最大化间隔的超平面;而逻辑回归则是通过一个sigmoid函数将线性模型的输出映射到0和1之间,用于概率估计和分类。
- 处理能力: SVM在高维空间中表现更好,通常更适合处理高维数据和小样本量;而逻辑回归在数据量较大时表现较好,适用于线性可分或近似线性可分的情况。
- 对异常值敏感度: SVM对于异常点的鲁棒性较好,因为它主要关注支持向量而不是整个数据集。而逻辑回归对异常点比较敏感,因为它使用了所有数据进行模型训练。
2.2 联系
- 都是常见的监督学习算法,用于分类问题。
- 可以使用核函数进行非线性分类。
- 都可以处理二分类和多分类问题。
3. SVM的应用领域
3.1 图像分类
在计算机视觉领域,SVM被广泛应用于图像分类任务。其在处理高维数据和复杂特征的能力使得它成为处理图像数据的理想选择。
SVM可用于图像分类,例如识别数字、人脸或其他物体。
3.2 文本分类
在自然语言处理中,SVM常用于文本分类任务,如垃圾邮件过滤和情感分析。
3.3 生物信息学
在生物信息学中,SVM用于基因分类、蛋白质分类等任务。其对于处理生物数据中的噪声和复杂关系具有很好的适应性。
3.4 金融领域
在金融领域,SVM可用于信用评级、欺诈检测等任务,帮助银行和金融机构识别潜在风险。其高维特征处理和对异常情况的敏感性使得它在金融数据分析中表现卓越。
3.5 医学诊断
在医学诊断中,SVM在医学图像分析中有广泛应用,如癌症检测和病理学分类。
4. SVM的优势与挑战
4.1 优势
4.1.1 非线性分类
SVM通过使用核技巧,可以轻松处理非线性问题。这使得它在实际应用中更加灵活,能够适应各种复杂的数据分布。
4.1.2 少量样本
由于SVM主要关注支持向量,它对于样本数量的要求相对较小。这使得在数据集规模较小的情况下,SVM仍能取得较好的性能,表现出强大的泛化能力。
4.1.3 高维数据处理
SVM在高维空间中表现出色,适用于处理特征数量多的数据,例如文本分类和图像识别。
4.1.4 泛化性能
SVM在训练集外的数据上表现出色,具有较强的泛化能力。
4.2 挑战
4.2.1 计算复杂性
在大规模数据集上训练SVM可能会面临计算复杂性的挑战。
4.2.2 参数选择
SVM的性能受到参数选择的影响,选择合适的参数对于模型性能至关重要。
5. SVM的工作原理
5.1 数据集导入
将已标记的数据集导入SVM模型,其中包含输入特征和相应的类别标签。
5.2 选择核函数
核函数用于将输入特征映射到高维空间,使数据更容易分割。常用的核函数包括线性核、多项式核和径向基函数(RBF)核。
5.3 训练模型
SVM通过调整决策边界,使得支持向量到决策边界的距离最大化。这个过程涉及到数学优化和拉格朗日乘子等概念。
5.4 预测新数据
训练完成后,SVM可以用于预测新的未标记数据的类别。
6. SVM实例:鸢尾花分类
我们将使用scikit-learn库中的鸢尾花数据集,其中包含了三种不同的鸢尾花(Setosa、Versicolor和Virginica),每种鸢尾花有四个特征(花萼长度、花萼宽度、花瓣长度和花瓣宽度)。
6.1 线性可分
首先,我们将鸢尾花数据集中的前两种鸢尾花(Setosa和Versicolor)作为正反例,使用线性核函数进行分类:
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 加载数据集
iris = datasets.load_iris()
# 取出前两种鸢尾花的两个特征
X = iris.data[:, :2]
y = iris.target
# 将0和1作为正反例进行分类
X = X[(y == 0) | (y == 1)]
y = y[(y == 0) | (y == 1)]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
# 构建SVM模型
svm = SVC(kernel='linear', C=1)
svm.fit(X_train, y_train)
# 绘制决策边界和支持向量
def plot_svc_decision_boundary(svm, ax=None):
if ax is None:
ax = plt.gca()
x_min, x_max = ax.get_xlim()
y_min, y_max = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
Z = svm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=0.1)
ax.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5)
ax.scatter(svm.support_vectors_[:, 0], svm.support_vectors_[:, 1], s=100, linewidth=1, facecolors='none')
plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='red')
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='blue')
plot_svc_decision_boundary(svm)
plt.show()
上述代码将鸢尾花数据集进行分类,只选择前两种鸢尾花的两个特征进行分类。这里我们使用了线性核函数,并设置松弛变量C的值为1。运行代码后,可以看到决策边界和支持向量:
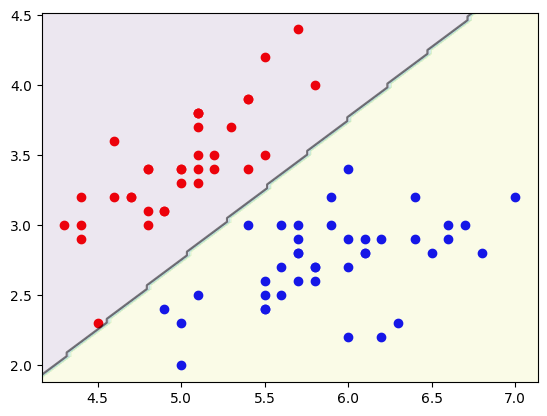
6.2 线性不可分
接下来,我们将鸢尾花数据集中的后两种鸢尾花(Versicolor和Virginica)作为正反例,使用多项式核函数进行分类:
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 加载数据集
iris = datasets.load_iris()
# 取出后两种鸢尾花的两个特征
X = iris.data[:, 2:]
y = iris.target
# 将1和2作为正反例进行分类
X = X[(y == 1) | (y == 2)]
y = y[(y == 1) | (y == 2)]
y[y==1] = 0
y[y==2] = 1
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
# 构建SVM模型
svm_poly3 = SVC(kernel='poly', degree=3, C=0.01)
svm_poly3.fit(X_train, y_train)
# 绘制决策边界和支持向量
def plot_svc_decision_boundary(svm, ax=None):
if ax is None:
ax = plt.gca()
x_min, x_max = ax.get_xlim()
y_min, y_max = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
Z = svm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=0.1)
ax.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5)
ax.scatter(svm.support_vectors_[:, 0], svm.support_vectors_[:, 1], s=100, linewidth=1, facecolors='none')
plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='red')
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='blue')
plot_svc_decision_boundary(svm_poly3)
plt.show()
上述代码使用多项式核函数进行分类,将鸢尾花数据集中后两种鸢尾花的两个特征作为输入特征,将类别标签设置为0和1。这里我们设置多项式核函数的阶数为3,松弛变量C的值为0.01。运行代码后,可以看到决策边界和支持向量:
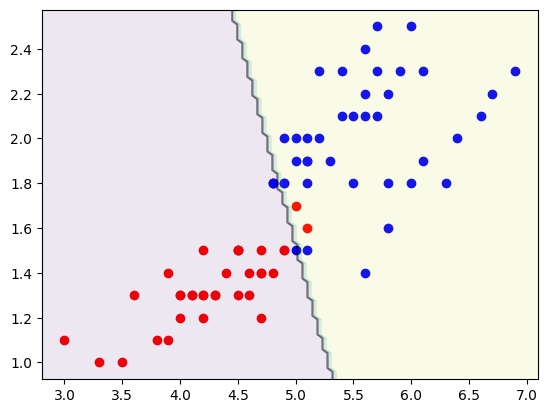
6.3 不同松弛变量的对比
最后,我们来看一下不同松弛变量的对比图:
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 加载数据集
iris = datasets.load_iris()
# 取出前两种鸢尾花的两个特征
X = iris.data[:, :2]
y = iris.target
# 将0和1作为正反例进行分类
X = X[(y == 0) | (y == 1)]
y = y[(y == 0) | (y == 1)]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
# 构建SVM模型
svm_c1 = SVC(kernel='linear', C=1)
svm_c1.fit(X_train, y_train)
svm_c01 = SVC(kernel='linear', C=0.1)
svm_c01.fit(X_train, y_train)
svm_c001 = SVC(kernel='linear', C=0.01)
svm_c001.fit(X_train, y_train)
# 绘制决策边界和支持向量
plt.figure(figsize=(10, 3))
plt.subplot(131)
plt.title("C=1")
plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='red')
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='blue')
plot_svc_decision_boundary(svm_c1)
plt.subplot(132)
plt.title("C=0.1")
plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='red')
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='blue')
plot_svc_decision_boundary(svm_c01)
plt.subplot(133)
plt.title("C=0.01")
plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='red')
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='blue')
plot_svc_decision_boundary(svm_c001)
plt.show()
上述代码将松弛变量C的值分别设置为1、0.1和0.01,绘制了三个不同的决策边界和支持向量:
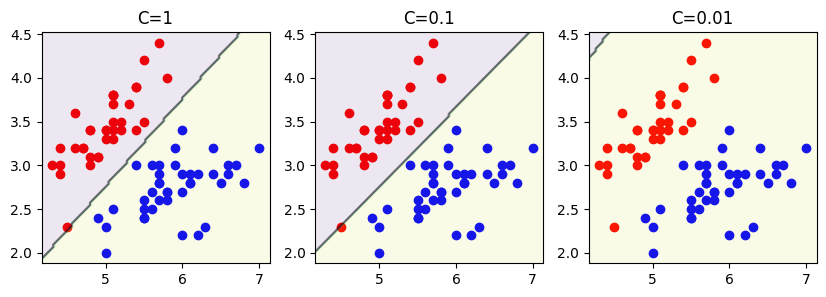
可以看到,松弛变量C的大小会影响决策边界和支持向量的位置。当C较大时,模型更关注分类的正确性,可能会产生过拟合的问题;而当C较小时,模型更关注间隔的大小,可能会产生欠拟合的问题。因此,在实际应用中,我们需要通过交叉验证等方法来选择一个合适的C值。
结语
支持向量机作为一种强大的分类器,在各个领域都展现出卓越的性能。其对于复杂数据的处理能力、在高维空间的有效分类以及对非线性问题的适应性,使得它成为机器学习领域不可或缺的工具之一。然而,使用SVM也需要仔细调整参数,特别是在面对大规模数据集时。在选择分类算法时,考虑到数据集的特性和问题的复杂性,支持向量机仍然是一个值得深入研究和应用的重要选择。
希望这篇博客对你有所帮助!如果你有任何问题或疑惑,欢迎在下方留言讨论。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 科学的摇篮 - 贝尔实验室
- (14)Linux 地址空间的理解
- Couldn’t communicate with a helper application
- 软件UI工程师的岗位职责(合集)
- Springboot使用参数解析器HandlerMethodArgumentResolver,解析请求头里的数据
- pyqt5 手动释放QPushButton的内存
- APP加固技术及其应用
- C语言算术操作符相关题目
- 第十一章 Spring Cloud Alibaba nacos配置中心
- ThinkPHP6 自定义Excel导出