C++ STL初识
文章目录
STL初始
基本概念
- STL 标准模板库
- STL从广义上分为容器 算法 迭代器
- 容器和算法之间通过迭代器进行无缝连接
- STL几乎所有的代码都采用了模板
STL六大组件
容器 算法 迭代器 仿函数 适配器 空间配置器
- 容器:各种数据结构,如vector list deque set map等,用来存放数据
- 算法:各种常用算法,如sort find copy for_each等
- 迭代器:扮演了容器和算法之间的胶合剂
- 仿函数:行为类似函数,可作为算法的某种策略
- 适配器:一种用来修饰容器或者仿函数或迭代器接口的东西
- 空间配置器:负责空间的配置和管理
STL的容器 算法 迭代器
容器:置物所为之
分为序列式容器和关联式容器
- 序列式容器:强调值的排序,序列式容器中的每个元素都有固定的位置
- 关联式容器:二叉树结构,各元素之间没有严格的物理上的顺序关系
算法:问题之解决也
algorithms
分为质变算法和非质变算法
- 质变算法:运算过程中更改区间内的元素
- 非质变元素:运算过程中不会更改区间内的元素
迭代器:容器和算法之间的胶合器
算法通过迭代器才可以访问容器的元素,每个容器都有自己专属的迭代器
迭代器支持赋值、解引用、比较、从左到右遍历
类似指针
迭代器种类:

迭代器失效:resize、reserve、assign、push_back、pop_back、insert、erase等函数可能会引起vector发生变化,导致迭代器失效
简单使用
*it就是<>里面的数据类型
可以使用 地址->访问 也可以 解引用.访问
void printV(int val){
cout<<val<<endl;
}
vector<int>v;
//插入数据
v.push_back(10);
v.push_back(20);
v.push_back(30);
//通过迭代器访问容器中的元素 迭代器类似指针用法 可以使用 地址->访问 也可以 解引用.访问
vector<int>::iterator itBegin = v.begin();//起始迭代器 指向容器第一个元素
vector<int>::iterator itEnd=v.end(); //结束迭代器 指向容器最后一个元素的下一个位置
while (itBegin!=itEnd){
cout<<*itBegin<<endl;
itBegin++;
}
for(vector<int>::iterator it = v.begin();it!=v.end();it++){
//===*it就是<>里面的数据类型===
cout<<*it<<endl;
}
//起始迭代器 结束迭代器 函数 回调函数
for_each(v.begin(),v.end(),printV);
二维
vector<vector<int>>v;
vector<int>v1;
vector<int>v2;
vector<int>v3;
for (int i = 0; i < 5; ++i)
{
v1.push_back(i + 1);
v2.push_back(i + 2);
v3.push_back(i + 3);
}
v.push_back(v1);
v.push_back(v2);
v.push_back(v3);
for (vector<vector<int>>::iterator it = v.begin(); it != v.end(); it++)
{
for (vector<int>::iterator i = (*it).begin(); i != (*it).end(); i++)
{
cout << *i << " ";
}
cout << endl;
}
STL常用容器
string容器
基本概念
本质
string是C++风格的字符串,本质是一个类
string和char*的区别
- char* 是一个指针
- string是一个类,类内部封装了char*,管理这个字符串,是一个char*型的容器
特点
string内部类封装了很多成员方法
- 查找find 拷贝copy 删除erase 替换replace 插入insert 等等
- string管理char*所分配的内存,不用担心复制越界和取值越界等,由类内部进行负责
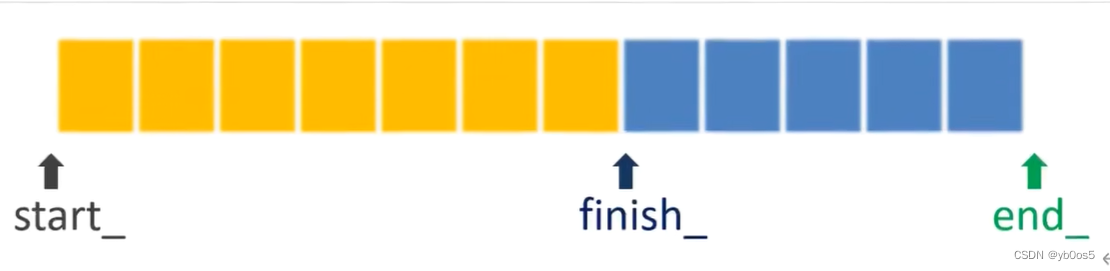
深追string
- string以字节为最小存储单元的动态容器
- 用于存放字符串(不存空字符0)
- 用于存放数据的内存空间(缓冲区)
- string内部三个指针
- char*start_; 动态分配内存块开始的地址
- char*end_; 动态分配内存块最后的地址
- char*finish_; 已使用空间的最后的地址
char cc[8]是什么? 本质上可以说为内存空间
1、可以存放7字符的字符串
2、可以存放8字符的字符数组
3、一块8字节的内存空间
构造函数
构造函数方法很多,没有最好的适合就好
- string() 创建一个空的字符串 如 string str
- stirng(const char*str) 使用字符串s的初始化
- string(const string&str) 一个string对象初始化另外一个string 拷贝构造函数
- string(int n;char c) 使用n个字符c初始化
- string(const char*s,size_t n) 使用前n个字符,即使超过n个字符也要继续
- 换句话说,将string对象初始化为s指向的地址后n个字节的内容
- string(const string&str,size_t pos=0,size_t n=npos) 从pos开始截取npos个字符 最大是到结尾 不会越界
- template string(T begin,T end) 使用迭代器构造
C++11新增的构造函数:
- string(string &&str)noexcept:将一个string对象初始化为string对象str,并可能修改str(移动构造函数)
- string(initializer_listli):初始化列表
string();
string(const char*s);
string(const string& str);
string(int n,char c); //n个字符c
赋值操作
给string字符串赋值
- string& operator=(const chat*s)
- string& operator=(const string&s)
- string& operator=(char c)
- string& assign(const chat*s)
- string& assign(const chat*s,int n) 返回s的前n个字符
- string& assign(const string&s)
- string& assign(const string&s,int pos,int n) 返回s的从第pos个字符开始的n个字符,最大是到字符串的结尾
- string& assign(int n,char c)
字符串拼接
- stirng& operator+=(char c)
- stirng& operator+=(char*str)
- string& operator+=(string &str)
- string& append(char*str)
- string& append(char*str,int n)在s后追加str的前n个字符
- string& append(string &str)
- string& append(string &str,int pos,int n)在s后追加str从第pos开始的n个字符,最大是到字符串的结尾 pos截取的开始位置 n截取的字符个数
大小和容量
size()
capacity()
swap():如果数据量很小,交换的时内容;如果数据类比较大,交换的时地址
查找操作
查不到返回string::npos,是string定义的一个静态常量
- int find(const char c,int pos = 0)const 查找字符c第一次出现的位置 从pos开始查找
- int find(const string&str,int pos = 0)const 查找str第一次出现的位置 从pos开始查找
- int find(const char*str,int pos = 0)const 查找str第一次出现的位置 从pos开始查找
- int find(const char*str,int pos,int n)const 查找str第一次出现的位置 查找区间为[pos,pos+n)
- int rfind(const char c,int pos = npos)const 查找字符c最后一次出现的位置 从pos开始查找
- int rfind(const string&str,int pos = npos)const 查找str最后一次出现的位置 从pos开始查找
- int rfind(const char*str,int pos = npos)const 查找str最后一次出现的位置 从pos开始查找
- int rfind(const char*str,int pos,int n)const 查找str最后一次出现的位置 查找区间为[pos,pos+n)
替换操作
replace成员函数可以对string对象中的字串进行替换,返回对象自身的引用
replace(int pos,int n,string s,[int pos],[int n]);
- string& repalce(int pos,int n,const string&str) 把原字符串从pos到pos+n的位置替换为str
- string& repalce(int pos,int n,const char*str) 把原字符串从pos到pos+n的位置替换为str
字符串比较
按照字符的ASCII码值进行对比
返回 = 0 > 1 < -1
- int comparce(const string &str)const
- int comparce(const char*s)const
- ==判断两个字符串是否相等
- 可以使用 > < >= <= 直接进行对比
主要是用于指定字符串的子串进行比较大小
s1.compare(1,3,s2,1,3); //s1从下标1开始数3个字符的字串与s2从下标1开始数3个字符的字串比较
字符存取
两种方法
- char &operator[](int n)
- char &at(int n)
插入字符串
insert 成员函数可以在 string 对象中插入另一个字符串,返回值为对象自身的引用
- string&insert(int pos,const char*s)
- string&insert(int pos,const string&s)
- string&insert(int pos,int n,const char c)
string s("limit");
s.insert(2,"123");//li123mit 在1-2之间插入
s.insert(1,5,'x');//lxxxxxi123mit 在0-1之间插入5个x
s.insert(3,"hello",1,3);// 在2-3之间插入hello 1到1之后的3个 子串
删除子串
erase删除string对象的子串,返回对象自身的引用
- string&erase(int pos,int n=npos) 从pos开始删除n个元素 删除区间[pos,pos+n)
string s("real dog");
s.erase(0,4);// dog 删除从下标0开始 4个字符
s.erase(2);// d 删除从下标2开始到结尾的全部字符
// 删除字符串中的steel
// 删除字符串中的steel
std::string s("sdjaldsteeldsakdssteel"),moom("steel");
while (s.find(moom)!=std::string::npos){
s.erase(s.find(moom),moom.length());
}
std::cout<<s<<std::endl;
截取子串
substr成员函数可以用于求子串,函数原型:
string substr(int n=0,int m=string::npos) const;
string s1 = s.substr(0, 2);//从s的索引为0的位置截取2个长度的字符串
string s2 = s.substr(2, 3);//从s的索引为2的位置截取3个长度的字符串
string s3 = s.substr(2);//如果只提供一个索引位置信息,那么截取s索引为2到字符串尾部
string s4 = s.substr();//如果不提供任何信息,那么等价于s3=s
string s5 = s.substr(7);//按理s的索引最多到6,但是组成字符串默认最后一位为空字符,所以索引可以到7
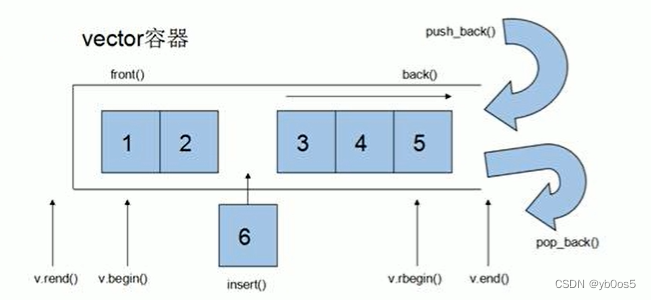
vector容器
基本概念
vector和数组非常相似,也称为单端数组
vector和普通数组的区别
- 数组是静态空间
- vector可以动态扩展(动态扩展并不是在原有的空间扩展空间,而是找一块更大空间,将原数据拷贝到新的大数组中然后再插入新增的数据)
- vector的迭代器是支持随机访问的
vector类模板的声明
template <class T,class Alloc = allocator<T>>
class vector{
private:
T*start_;
T*finish_;
T*end_;
}
分配器:各种 STL 容器模板都接受一个可选的模板参数,该参数指定使用哪个分配器对象来管理内存如果省略该模板参数的值,将默认使用 allocator,用 new和 delete 分配和释放内存。
构造函数
函数原型
vector<T>v采用模板实现类实现 默认构造函数 无参构造vector <T>v(v.begin(),v.end());将v[begin(),end())区间中的元素拷贝给本身vector<T>v(n,elem)n个elem拷贝给本身vector<T>v(const vector&vec);拷贝构造函数
void printVector(vector<int>&v){
for (vector<int>::iterator begin = v.begin(); begin!=v.end() ; ++begin) {
cout<<(*begin)<<" ";
}
cout<<endl;
}
void test1(){
vector<int>v1;
for (int i = 0; i < 10; ++i) {
v1.push_back(i);
}
vector<int>v2(v1.begin(),v1.end());
vector<int>v3(10,20); //10个20
vector<int>v4(v3);//拷贝构造
printVector(v1);
printVector(v2);
printVector(v3);
printVector(v4);
}
赋值操作
函数原型
vector& operator=(const vector&vec);重载等号assgin(beg,end);开始的地址 到最后的地址的后一个assgin(n,elem);n个elem元素
void test2(){
vector<int>v1;
for (int i = 0; i < 10; ++i) {
v1.push_back(i);
}
printVector(v1);
vector<int>v2;v2=v1;
printVector(v2);
vector<int>v3;
//前闭后开
v3.assign(v1.begin(),v1.end());
printVector(v3);
//n个elem
vector<int>v4;
v4.assign(10,100);
printVector(v4);
}
容量和大小
empty()判断vector是否为空 true or falsecapacity()容器的容量size()容器的大小/个数resize(int num)重新指定容器长度为num,容器变长,默认值0填充 容器变短 删除超出的resize(int num,elem)重新指定容器长度为num,容器变长,elem填充 容器变短 删除超出的- resize不会改变容量
void test3(){
vector<int>v1;
for (int i = 0; i < 10; ++i) {
v1.push_back(i);
}
if (!v1.empty()){
printVector(v1);
cout<<"v1的容量:"<<v1.capacity()<<endl;
cout<<"v1的大小:"<<v1.size()<<endl;
}
v1.resize(5);
printVector(v1);
cout<<"v1的容量:"<<v1.capacity()<<endl;
cout<<"v1的大小:"<<v1.size()<<endl;
}
插入和删除操作
push_back(ele)尾部插入元素eleemplace_back(...)尾部插入元素ele,…构造函数 C++11pop_back()尾部删除元素insert(const_iterator pos,ele)迭代器指向位置pos插入元素insert(const_iterator pos,int n,ele)迭代器指向位置pos插入n个ele元素erase(const_iterator pos)删除迭代器指向的元素,返回下一个元素的位置erase(const_iterator start,const_iterator end)删除迭代器start和end之间的元素clear()清空容器中所有的元素
void test4(){
vector<int>v1;
for (int i = 0; i < 10; ++i) {
v1.push_back(i);
}
printVector(v1);
v1.insert(v1.begin(),5);//在最前面插入5
printVector(v1);
v1.insert(v1.begin(),2,6);//在最前面插入2个6
printVector(v1);
v1.erase(v1.begin(),v1.begin()+2);//删除前两个 前闭后开
printVector(v1);
}
数据存取操作
operator[](int i)at(int i)front()返回第一个元素back()返回最后一个元素
既可以通过迭代器遍历vector,也可以使用[] at遍历vector
void test5(){
vector<int>v1;
for (int i = 0; i < 10; ++i) {
v1.push_back(i);
}
cout<<v1.front()<<endl;
cout<<v1.back()<<endl;
cout<<v1.at(5)<<endl;
}
容器互换
函数原型:
swap(vec)将vec与本身的元素互换
void test6(){
vector<int>v1(10,1);
vector<int>v2(10,8);
v1.swap(v2);
printVector(v1);
printVector(v2);
}
实际用途:巧用swap收缩内存空间
void test6(){
vector<int>v1(10000,1);
cout<<"v1的容量:"<<v1.capacity()<<endl;
cout<<"v1的大小:"<<v1.size()<<endl;
v1.resize(5);
cout<<"v1的容量:"<<v1.capacity()<<endl;
cout<<"v1的大小:"<<v1.size()<<endl;
vector<int>(v1).swap(v1);
/*解释为什么可以收缩内存空间?
* 首先 vector<int>(v1) 是一个匿名对象,当执行完毕后编译器会自动回收匿名对象的空间
* 匿名对象使用v1的所有的大小初始化大小和容量 所有匿名对象的大小和容量为5
* 然后 .swap(v1) v1和匿名对象容量进行交换
* 匿名-> 5 10000 v1->5 5 执行完毕后编译器会自动回收匿名对象的空间
* */
cout<<"v1的容量:"<<v1.capacity()<<endl;
cout<<"v1的大小:"<<v1.size()<<endl;
}
预留空间
减少vector在动态扩展容量时的扩展次数
reserve(int len)容器预留len个元素长度,预留位置不初始化,元素不可访问
void test7(){
vector<int>v;
//可以利用reserve预留空间
v.reserve(100000);
//统计开辟多少次内存
int num=0;
int *p = nullptr;
for (int i = 0; i < 100000; ++i) {
v.push_back(i);
if (p!=&v[0]){
p=&v[0];
num++;
}
}
cout<<"开辟"<<num<<"次内存空间"<<endl;
}
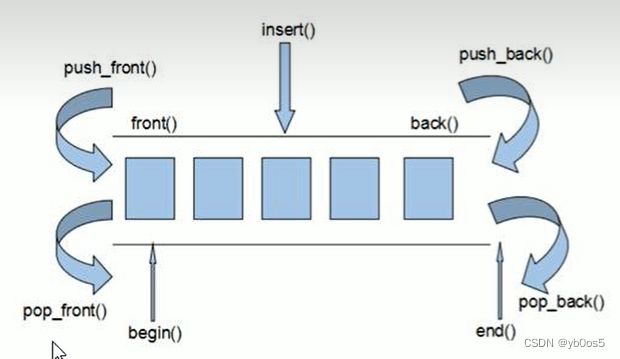
deque容器
基本概述
双端数组(双端队列),可以对头端进行插入删除操作
deque和vector区别
- vector对于头部的插入删除效率低,数据量越大,效率越低
- deque相对而言,对头部的插入删除速度比vector快
- vector访问元素时的速度会比deque访问的速度快,这和两者内部实现有关
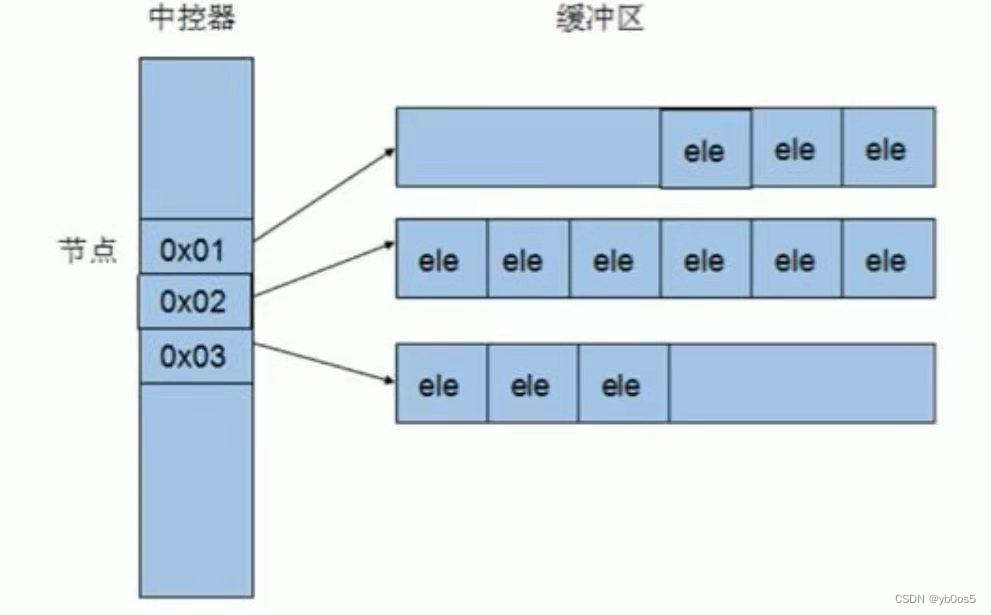
deque内部实现原理
一个连续的空间存储着地址,地址指向一个个的数组 所以说有的地方内存地址是不连续的 访问元素速度慢
deque内部有个中控器,维护每段缓冲区中的内容,缓冲区中存放这真实的数据
deque的迭代器也支持随机访问
构造函数
deque<T>depT默认构造deque<T>(beg,end)区间构造deque<T>(n,elem)n个elemdeque<T>(const deque<T>&deq)拷贝构造
deque<int> d;
for(int i=0;i<10;i++)
{
d.push_back(i);
}
//打印
for(deque<int>::const_iterator it = d.begin();it!=d.end();it++)
{
// *it = 100;//不允许修改 加上了 const_iterator 只读迭代器
cout<<*it<<endl;
}
赋值操作
deque&operator=(const deque&d)assign(beg,end)assgin(n,elem)n个elem
大小操作
和vector几乎一致
deque没有容量的概念,它可以无限扩展
empty()是否为空size()大小resize(num)重新指定大小resize(num,elem)如果是容器变长 elem填充新位置
插入和删除操作
两端操作
push_back(elem)push_front(elem)pop_back()pop_front()
中间操作
insert(const_iterator pos,ele)迭代器指向位置pos插入元素insert(const_iterator pos,int count,elem)迭代器指向位置pos插入count个elem元素insert(const_iterator pos,const_iterator begin,const_iterator end)迭代器指向位置pos插入[begin,end)里面的指向的元素 区间插入erase(const_iterator pos)删除迭代器指向的元素erase(const_iterator start,const_iterator end)删除迭代器start和end之间的元素 [begin,end)区间删除clear()清空容器中所有的元
deque数据获取
函数原型
operator[](index)at(index)back():最后一个元素front():第一个元素
排序
vector也支持sort 只要支持随机访问的迭代器容器才可以使用sort
sort(iterator begin,iterator end)从小到大 升序 默认
stack容器
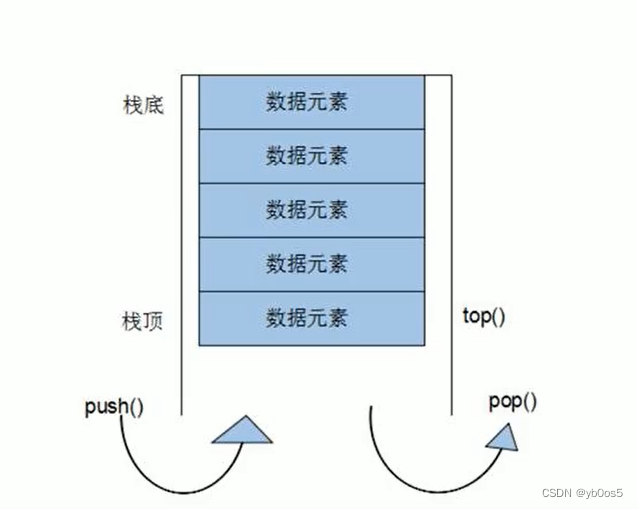
基本概念
- 先入后出 栈 只有一个出口
- 栈只有最顶端的元素才可以被访问,不可以被遍历
构造函数
stack<T>stkstack<T>stk(const stack<T>&stk)
赋值操作
stack &operator=(const stack &s)
入栈
push()
出栈
pop()
是否为空
empty()
大小
size()
栈顶元素
top()
queue容器
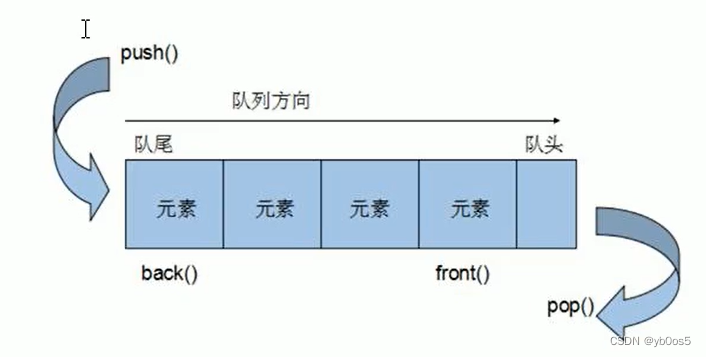
基本概念
先入先出 队列
队列只有队头和队尾才可以被访问,不可以被遍历
构造函数
queue<T>qqueue<T>q(const queue<T>&q1)
赋值操作
queue<T>&operator=(const queue<T>&que)
入队
push()
出队
pop()
是否为空
empty()
队首 队尾
front()back()
大小
size()
数组结构容器
存储的是连续的内存数据
优点:
- 对于容器的遍历速度相对快,支持随机访问
- 占用空间相对小
缺点:
- 任意位置进行插入或删除元素花费大
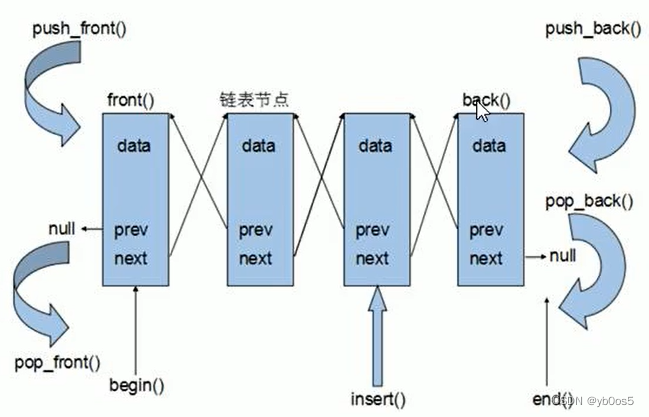
list容器
基本概念
将数据链式存储 链表
list存储非连续的存储结构
链表由一系列结点(数据域 指针域)组成
优点:
- 任意位置进行快速的插入或删除元素
- 链表动态分配内存,不会导致内存的浪费和溢出
缺点:
- 对于容器的遍历速度没有数组快
- 占用空间比数组大
- 时间空间消耗大
- 不能随机访问
STL的list是双向循环链表,如下图片没有体现出循环
存储方式不是连续的内存空间,所以迭代器属于双向迭代器
构造函数
函数原型
list<T>lst;list<T>lst(beg,end);list<T>lst(n,elem)list(const list<M>&lst1)
赋值和交换
assign(beg,end)assgin(n.elem)list&operator=(const list &l)swap(list)
大小操作
size()empty()resize(num)resize(num,elem)
插入删除
push_back()push_front()pop_back()pop_front()insert(pos,elem)insert(pos,count,elem)insert(pos,beg,end)erese(pos)删除本位置数据,返回下一个位置的数据erese(beg,end)删除区间数据,返回下一个位置的数据remove(elem)删除所有的elemclear()
数据存取
front()首元素back()尾元素
迭代器只能++ --,但是不支持随机访问 即 迭代器=迭代器+1是错误的
反转和排序
reserve();反转链表sort();排序L1.sort()默认排序升序 内置函数-
不支持随机访问的迭代器的容器,不可以使用标准算法,内部提供对应一些算法
-
自定义的数据类型必须指定排序规则,否则编译器并不知道如何排序
-
L1.sort();//括号可以传函数或者仿函数 默认升序
//函数 降序
class Human{
public:
string name;
int age;
int height;
Human(){}
Human(string name,int age,int height){
this->name=name;
this->age=age;
this->height=height;
}
};
//指定排序规则
// age 升序排序,如果age相同 按照height降序排序
bool compareHuman(Human &h1,Human &h2){
if (h1.age==h2.age)
return h1.height>h2.height;//降序
return h1.age<h2.age; //小到大 升序
}
void printHuman(list<Human>&lst){
for (list<Human>::iterator it=lst.begin(); it!=lst.end();++it) {
cout<<(*it).name<<"--"<<it->age<<"-"<<(*it).height<<endl;
}
}
void test10(){
list<Human>lst;
Human h1("刘备",40,182);
Human h2("关羽",40,165);
Human h3("张飞",23,185);
Human h4("曹操",36,179);
Human h5("袁绍",81,177);
lst.push_front(h1);lst.push_back(h2);
lst.push_front(h3);lst.push_back(h4);
lst.push_front(h5);
lst.sort(compareHuman);
printHuman(lst);
}
set/multiset容器
基本概念
所有的元素在插入时自动排序 集合
set/multiset属于关联式容器,底层结构是用二叉树实现的
只需要包含头文件 set 即可
set/multiset区别
- set插入重复的值不会成功(但是也不会报错),multiset可以插入重复的值
- set插入数据同时会返回插入的结果,表示是否插入成功,返回值是pair对组 (插的位置 是否成功)
- multiset不会检测数据,因此可以重复数据
构造函数
set<T>s;set<T>s(const set<T>&s0);
大小和交换
size()empty()swap(set)
插入和删除
insert(elem)只能insert插入clear()erase(elem)传入值erase(pos)传入迭代器erase(beg,end)开始结束迭代
查找和统计
find(key)若存在返回元素所在位置的迭代器,不存在,返回set.end()count(key)返回key的个数,返回值是int类型 对于set只有0/1 对于multiset有其他的结果
容器排序
set默认从小到大排序,改变排序:使用仿函数=(重载函数调用)
#include<iostream>
#include<set>
using namespace std;
class myCompare
{
public:
bool operator()(int a, int b)const
{
return a > b;
}
};
int main()
{
//指定排序规则从大到小 插入之前就要指定排序的规则
set<int, myCompare> s;
s.insert(20);
s.insert(60);
s.insert(10);
s.insert(2);
for (set<int, myCompare>::iterator it = s.begin(); it != s.end(); it++)
{
cout << *it << " ";
}
return 0;
}
pair对组
创建方式
pair<type,type> p (value1,value2)pair<type,type> p = make_pair(value1,value2)
访问方法
void test13(){
// pair<string,int>p("du",18);
pair<string,int>p = make_pair("du",88);
cout<<p.first<<endl;
cout<<p.second<<endl;
}
map/multimap容器
基本概念
高性能
- 所有的元素都是pair对组
- pair中第一个元素是key(键值),第二个元素是value(实值)
- 所有元素的key键值自动排序
map/multimap属于关联式容器,底层结构是用二叉树实现的
只需要包含头文件 map 即可
优点:可以根据key快速找到value
map/multimap区别
- map不允许有重复的key值
- multimap允许有重复的key值
构造和赋值
map<T1,T2>mmap<T1,T2>m(const map<T1,T2>&mm)map&operator=(const map&m)
大小和交换
size()empty()空 true 非空falseswap(map)
插入和删除
insert(elem)- elem:
pair<T1,T2>(key,value) - elem:
make_pair(key,value)***不用写模板了 方便一点 - elem:
map<int,int>::value_type(key,value) map[key] =value- 不建议使用[]
- 因为如果map[index]不存在 它会自动创建一个 key为index value为0的pair
- 关键值 key 相同时,用下标[]插入会覆盖 value 值,用 insert 插入键值对则不覆盖(插入失败)
emplace_hint(const iterator pos,....):第一个位置时程序员提供的应该将该元素插入的位置,如果提供的位置正确 效率提高,如果提供的位置错误 效率降低。最终都会插入正确的位置
- elem:
clear()erase(pos)earse(beg,end)earse(key)
查找和统计
map<T1,T2>iterator it = find(key)有的话返回迭代器 没有返回end()int num = count(key)map 结果无非是0/1,multimap结果可能大于1
容器排序
#include<iostream>
#include<map>
using namespace std;
//利用仿函数 从大到小排序
//将operator()设置为常函数
class compare
{
public:
bool operator()(int a, int b)const
{
return a > b;
}
};
int main()
{
map<int, int,compare>m;
m.insert(make_pair(5, 50));
m.insert(pair<int,int>(50, 150));
m.insert(make_pair(1, 54));
m.insert(make_pair(5, 30));
m.insert(make_pair(8, 80));
for (map<int,int,compare>::iterator it = m.begin(); it !=m.end(); it++)
{
cout << "1 " << it->first << " 2 " << it->second << endl;
}
return 0;
}
简单demo练习

class Staff{
public:
string name;
int salary;
Staff(){}
Staff(string name,int salary){
this->name = name;
this->salary=salary;
}
};
void createStaff(vector<Staff>&staffs){
string nameSeed = "ABCDEFGHIJ";
for (int i = 0; i < nameSeed.length(); ++i) {
string name = "员工";
name +=nameSeed[i];
Staff s(name,rand()%2001+3000);
staffs.push_back(s);
}
}
void setDepartment(vector<Staff>staffs,multimap<int,Staff> &s){
// char *departments[] = {"策划","美术","研发"};
int lens = staffs.size();
for (int i = 0; i < lens; ++i) {
int seed = rand()%3+1; //1-3
s.insert(make_pair(seed,staffs[i]));
}
}
void getStaffs(multimap<int,Staff> &s,string department){
int depart = -1;
if (department == "策划")
depart = 1;
else if(department=="美术")
depart = 2;
else if(department == "研发")
depart = 3;
else
return;
multimap<int,Staff>::iterator pos = s.find(depart);
int num = s.count(depart);
cout<<department<<"的员工信息:"<<endl;
for (int index=0;index<num ; pos++,++index) {
cout<<pos->second.name<<"-"<<pos->second.salary<<endl;
}
}
int main() {
vector<Staff>staffs;
createStaff(staffs);
multimap<int,Staff>s;
setDepartment(staffs,s);
getStaffs(s,"策划");
getStaffs(s,"美术");
getStaffs(s,"研发");
}
insert和emplace插入元素的区别
class CGril{
public:
int gAge;
string gName;
CGril(){
cout<<"默认构造函数"<<endl;
}
CGril(string name,int age):gName(name),gAge(age){
cout<<"两个参数的构造函数"<<endl;
}
CGril(const CGril&gril){
cout<<this<<endl;
cout<<"拷贝构造函数"<<endl;
}
};
int main() {
map<int,CGril>m;
/*!
* 调用两次拷贝构造函数:
* 1、CGril("西施",17) 调用含参数的构造函数
* 2、std::make_pair<int,CGril>(18,CGril("西施",17)); 将1构造好的对象拷贝给pair对
* 3、insert的时候,不是插入2创建好的,而是新拷贝一次insert
*/
m.insert(std::make_pair<int,CGril>(18,CGril("西施",17)));
//这样写和insert一样,调用两次拷贝构造函数
m.emplace(std::make_pair<int,CGril>(19,CGril("西施",17)));
/*!
* 调用一次拷贝构造函数,省去了匿名对象被拷贝赋值给pair对的操作
*/
m.emplace(17,CGril("西施",17));
/*!
* 若想要一次也不调用拷贝构造函数:
* 分段构造技术
*/
// m.emplace(10,"西施",17); //这个是错误的写法
m.emplace(std::piecewise_construct, std::forward_as_tuple(22), std::forward_as_tuple("貂蝉",18));
}
哈希表
概念
哈希表长(桶的个数):数组的长度
哈希函数
装填因子:元素总数/表长,值越大效率越低
unordered_map容器
封装了哈希表,查找、插入和删除元素时,只需要比较几次key的值
包含头文件:unordered_map
容器中的元素时pair对
unordered_map类模板的声明:
template <class K,class V,class _Hasher=hash<K>,class _Keyeq=equal_to<K>,class _Alloc=allocator<pair<const K,V>>>
class unordered_map:public _Hash<_Umap_traits<K,V,_Uhash_compare<K,_Hasher,_Keyeq>,_Alloc,false>>{
}
K:key pair.first
V:value pair.second
_Hasher:哈希函数 默认值为 std::hash<K>
_Keyeq:比较函数,用于判断两个key是否相等,默认值为 std::equal_to<K>
_Alloc:分配器,缺省用new和delete
template <class K,class V>
using nmap = std::unordered_map<K,V>
构造函数
umap():创建一个空的哈希容器umap(size_t bucket):创建一个空的哈希容器,指定桶的个数umap(initializer_list<pair<K,V>> il):使用统一初始化列表umap(initializer_list<pair<K,V>> il,size_t bucket):使用统一初始化列表umap(iterator first,iterator last):用迭代器创建umap容器umap(iterator first,iterator last,size_t bucket):用迭代器创建umap容器umap(const umap<K,V>&m):拷贝构造函数umap(umap<K,V>&&m):移动构造函数 C++11
特性操作
除了特性操作,其余操作都和map容器一致
哈希表扩容要将之前分配的内存全部释放掉,重新分配。代价是非常大的,实际开发中一般不会改变哈希表的桶的数量
size()
empty()
clear()
max_bucket_count() //返回容器底层最多可以使用多少桶 无实际意义
bucket_count() //返回容器桶的数量 空容器有8个桶
begin(size_t n)//返回第n个桶中第一个元素的迭代器
end(size_t n)//返回第n个桶中最后一个元素之后的迭代器
reserve() //设置至少为多少桶
load_factor() //当前容器的装填因子
max_load_factor()//返回容器的最大装填因子,达到该值后 容器扩充 缺省为1
max_load_factor(float z) //设置容器最大装填因子
rehash(size_t n)//将桶的数量调整为>=n。如果 n大于当前容器的桶数,该方法会将容器重新哈希;如果n的值小于当前容器的桶数,该方法可能没有任何作用
bucket_size(size_t n)//返回第n个桶中元素的个数
bucket(K &key)//返回值为key的元素对应的桶的编号
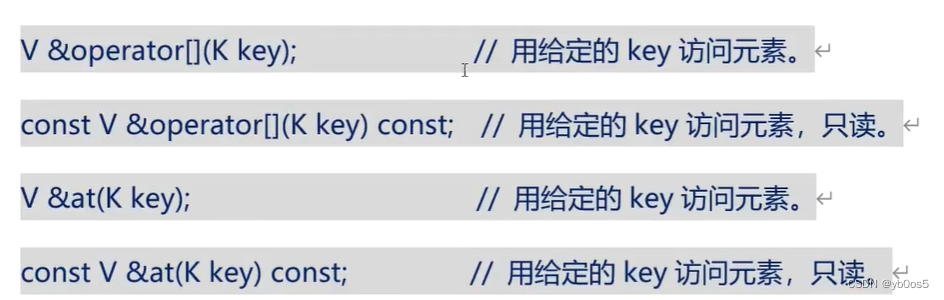
元素操作
赋值操作

交换操作
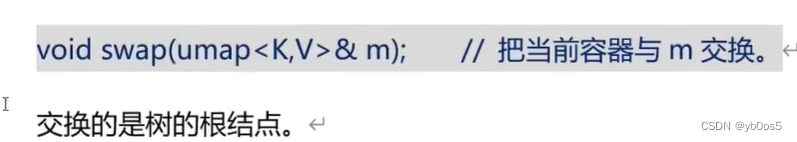
比较操作

查找操作

插入删除

STL其他容器
array静态数组
在栈上分配内存,数组长度必须为常量,创建后大小不可以改变
随机访问迭代器
部分场景下,比常规数组更方便(可以使用模板)



forward_list单链表
如果单链表可以满足业务要求,尽量使用单链表代替双链表
unordered_multimap
unordered_multiset && unordered_set
priority_queue优先队列
STL函数对象 (仿函数)
仿函数
基本概念
- 重载函数调用操作符类常称为函数对象
- 函数对象使用重载的()时,行为类似函数调用,也叫仿函数
使用方法
- 函数对象在使用是可以有参数,可以有返回值,像普通函数一样调用
- 函数对象超出普通函数的概念,函数对象可以有自己的状态
- 函数对象可以作为参数传递
class my
{
public:
void operator()(string name)
{
cout<<name;
}
}
//函数对象作为函数参数
void test(my&m,string n)
{
m(n);
}
谓词
概念
- 返回bool类型的仿函数
- operator()接受一个参数 一元谓词
- operator()接受两个参数 二元谓词
一元谓词
class Person
{
public:
bool operator()(int a)
{
return a>10;
}
}
二元谓词
class Person
{
public:
bool operator()(int a,int b)
return a>b;
}
}
sort(beg,end,Person())
内建函数对象
基本概念
STL内建了一些函数对象
分类
- 算术仿函数
- 关系仿函数
- 逻辑仿函数
用法
- 这些仿函数所产生的对象,用法和一般函数完全相同
- 使用内建函数对象,需要引入头文件
#include<functional>
算术仿函数
- 实现四则运算
- 其中
negate是一元运算符(取反),其他都是二元运算符
仿函数原型
template<class T> T plus<T>加template<class T> T minus<T>减template<class T> T multiplies<T>乘template<class T> T divides<T>除template<class T> T modulus<T>模template<class T> T negate<T>取反
关系仿函数
template<class T>T bool equal_to<T>等于template<class T>T bool not_equal_to<T>不等于template<class T>T bool greater<T>大于template<class T>T bool greater_equal<T>大于等于template<class T>T bool less<T>小于template<class T>T bool less_equal<T>小于等于
逻辑仿函数
template<class T> bool logical_and<T>template<class T> bool logical_or<T>template<class T> bool logical_not<T>
STL常用算法
概述
- 头文件
algorithmfunctionalnumeric组成 <algorithm>是所有STL头文件中最大的一个,范围涉及到比较、交换、遍历、排序、复制、修改等<numeric>体积小,只包括几个在序列上的简单的数学运算的模板<functional>定义一些模板类,以声明函数对象
for_each遍历
标准库的for_each:

自己实现简单的foreach
//T2既可以是普通函数也可以是类
template<class T1,class T2>
void foreach(const T1 first,const T1 end,T2 fun){
for (auto it = first; it!=end ; it++) {
// cout<<"向女神表白"<<*it<<"次"<<endl;
fun(*it);
}
}
template<typename T>
void fun(const T&s){
cout<<s<<",I love you!"<<endl;
}
template<typename T>
class CBB{
public:
void operator()(const T&s){
cout<<s<<",I love you!"<<endl;
}
};
int main() {
std::list<string>v({"西施","貂蝉","王昭君"});
foreach(v.begin(),v.end(),fun<string>);
foreach(v.begin(),v.end(),CBB<string>());
}
find_if

传入的函数/仿函数返回值为true,返回该迭代器;如果返回false,返回end

sort排序
仅支持随即访问迭代器

template<typename T>
bool compareAsc(const T&left,const T&right){//升序
return left>right;
}
template<typename T>
bool compareDesc(const T&left,const T&right){//降序
return left<right;
}
//仿函数
template<class T>
class _less{//升序
public:
bool operator()(const T&left,const T&right){
return left>right;
}
};
template<class T>
class _greater{//降序
public:
bool operator()(const T&left,const T&right){
return left<right;
}
};
template<class T1,class T2>
void bubbleSort(const T1 first,const T1 last,T2 compare){
while (true){
bool flag = false;
for (auto it = first; ;) {
auto left = it++;
auto right = it;
if (right==last)break;
//写死的这样是不满足需求的,我们可以传入函数/仿函数
//compare函数 返回true时交换left和right
if (compare(*left,*right)){
auto tmp = *left;
*left=*right;
*right=tmp;
flag = true;
}
/*if (*left>*right){
auto tmp = *left;
*left=*right;
*right=tmp;
flag = true;
}*/
}
if (!flag)break;
}
}
int main() {
// vector<int>v({5,6,9,1,2,3,4,6});
vector<string>v({"05","16","09","01","42","03","04","66"});
// bubbleSort(v.begin(),v.end(), compareDesc<string>);//普通函数
bubbleSort(v.begin(),v.end(), _less<string>());//仿函数 升序
bubbleSort(v.begin(),v.end(), _greater<string>());//仿函数 降序
for(auto i:v){
cout<<i<<" ";
}
}
要领
如果容器有成员函数,优先使用成员函数,如果没有才考虑使用STL的算法函数
STL过一遍就行,知道大概有什么东西
如果打算用STL算法,一定要搞清它的原理,关注它的效率
不要太看重这些算法函数
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- windows 设置ip命令bat脚本
- Gdi+ 展示gif
- 【已解决】vs2015下QtnetWork No Such File or Directory报错
- c语言do while循环语句
- 【C++】特殊类 | 单例模式
- 前端方法调用后端Controller获取列表数据
- 使用Matlab实现声音信号处理
- CNN实现对手写字体的迭代
- rime中州韵 default.custom.yaml 配置 保姆教程
- Python中的面向对象编程