Python数据分析案例33——新闻文本主题多分类(Transformer, 组合模型) 模型保存
案例背景
对于海量的新闻,我们可能需要进行文本的分类。模型构建很重要,现在对于自然语言处理基本都是神经网络的方法了。
本次这里正好有一组质量特别高的新闻数据,涉及? '教育' '科技' '社会' '时政' '财经' '房产' '家居'
?七大主题,基本涵盖了所有的常见的新闻类型。每个主题取了1w条,总共7w条数据,也还符合深度学习的数据量。
正好我也构建了很多神经网络的序列模型,来验证一下哪些模型在这个数据集上表现较好。
数据展示
数据原本是压缩包文件,里面是七个主题文件夹,每个文件夹都是一个个txt新闻的文本。我用python提取出来,每个主题1w条,放入excel文件,如下:
他每条新闻都特别长,也没有奇怪的标点符号什么的,数据质量很高。
需要本案例数据和全部代码的同学可以参考:新闻数据
代码实现
文本预处理
还是先导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'
import jieba
构建停用词表和分词函数。(停用词文本也在上面的数据链接里面。)
?
stop_list = pd.read_csv("停用词.txt",index_col=False,quoting=3, #停用词
sep="\t",names=['stopword'], encoding='utf-8')
#Jieba分词函数
def txt_cut(juzi):
lis=[w for w in jieba.lcut(juzi) if w not in stop_list.values]
return " ".join(lis)读取本文,分词和标签,注意这里分词和去除停用词都是一起完成的。
df=pd.read_excel('文本.xlsx')
data=pd.DataFrame()
data['label']=df['种类']
data['cutword']=df['内容'].astype('str').apply(txt_cut)
data['cutword']=data['cutword'].str.replace('\n','')
data
画出柱状图查看数据量,每个主题的文本内容:
data['label'].value_counts().plot(kind='bar')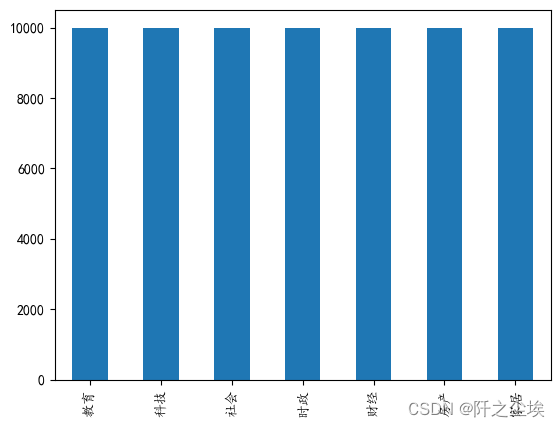
都是1w条。
数据准备完毕,下面开始用深度学习框架将文本变为向量。
文本向量化
导入Keras框架,构建文本词表
from os import listdir
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# 将文件分割成单字, 建立词索引字典
tok = Tokenizer(num_words=10000)
tok.fit_on_texts(data['cutword'].values)
print("样本数 : ", tok.document_count)?
查看词表前十个词:
print({k: tok.word_index[k] for k in list(tok.word_index)[:10]})![]()
查看X的长度分部:
X= tok.texts_to_sequences(data['cutword'].values)
#查看x的长度的分布
length=[]
for i in X:
length.append(len(i))
v_c=pd.Series(length).value_counts()
print(v_c[v_c>150])
v_c[v_c>150].plot(kind='bar',figsize=(12,5))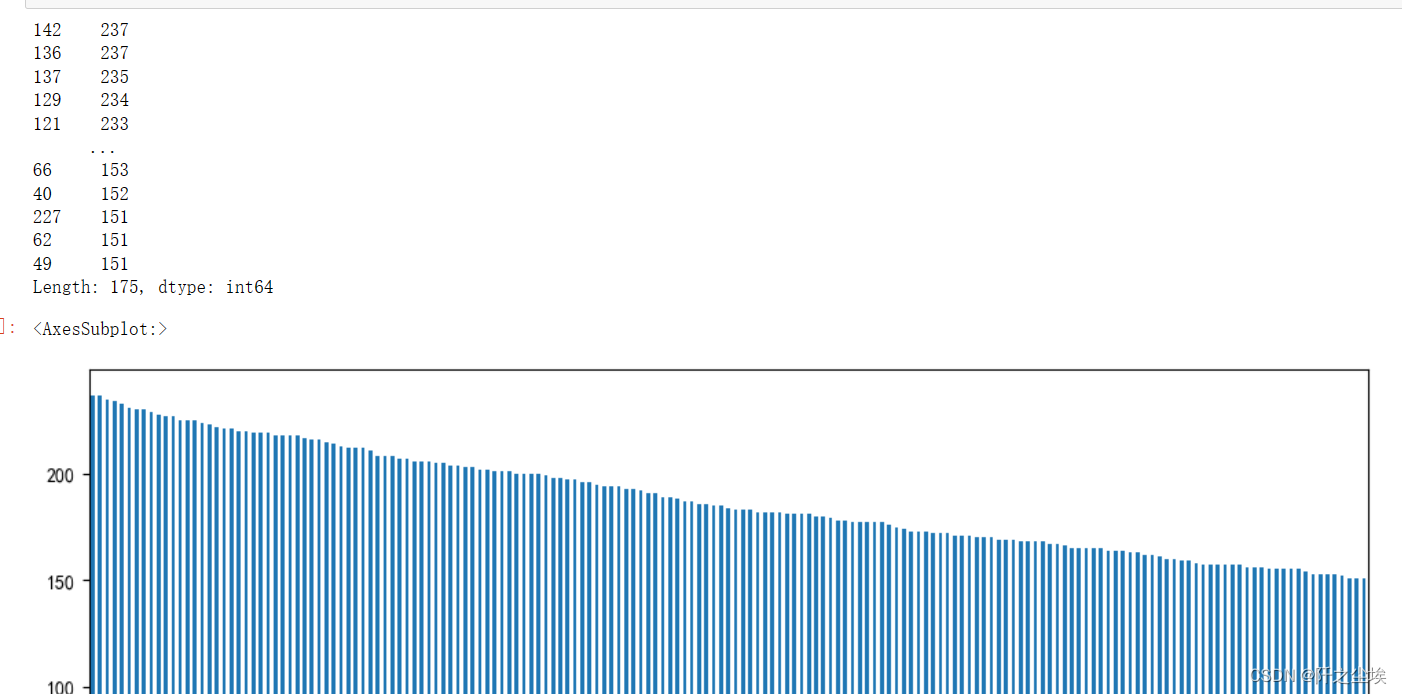
可以看到绝大部分X长度在140附近,我们选择将X长度统一为200,去多少补。
查看y的索引字典
lis=list(data['label'].unique())
dic1=dict([(key,value)for (value,key) in enumerate(lis)])
dic2=dict([(value,key) for (key,value) in dic3.items()])
dic1,dic2
# 将序列数据填充成相同长度?
X= sequence.pad_sequences(X, maxlen=200)
Y=data['label'].map(dic1).values
print("X.shape: ", X.shape)
print("Y.shape: ", Y.shape)
#X=np.array(X)
#Y=np.array(Y)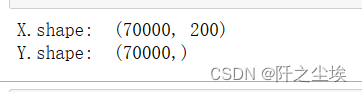
划分测试集和训练集
?
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, stratify=Y, random_state=0)
X_train.shape,X_test.shape,Y_train.shape, Y_test.shape
因为y套独热,所以我们保留原始的y方便后面评价指标计算
Y_test_original=Y_test.copy()
Y_train = to_categorical(Y_train)
Y_test = to_categorical(Y_test)
Y= to_categorical(Y)取出X和y其中的3个查看一下:
print(X_train[100:103])
print(Y_test[:3])
Y_test_original[:3]
没什么问题,准备开始训练网络了。
开始构建神经网络!?
Keras里面没有现成的Transformer,所以导入包,构建Transformer,模块。
from tensorflow.keras import layers
import tensorflow as tf
from tensorflow import keras
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),layers.Dense(embed_dim),] )
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None):
if mask is not None:
mask = mask[:, tf.newaxis, :]
attention_output = self.attention(inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim, })
return configTransformer还需要位置编码,:
?
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding(input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(input_dim=sequence_length, output_dim=output_dim)
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
def get_config(self):
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,})
return config设定参数:
from keras.preprocessing import sequence
from keras.models import Sequential,Model
from keras.layers import Dense,Input, Dropout, Embedding, Flatten,MaxPooling1D,Conv1D,SimpleRNN,LSTM,GRU,Multiply,GlobalMaxPooling1D
from keras.layers import Bidirectional,Activation,BatchNormalization,GlobalAveragePooling1D,MultiHeadAttention
from keras.callbacks import EarlyStopping
from keras.layers.merge import concatenate
np.random.seed(0) # 指定随机数种子
#单词索引的最大个数10000,单句话最大长度200
top_words=10000
max_words=200 #序列长度
embed_dim=128 #嵌入维度
num_labels=7 #7分类构建模型,这里有十几种模型,如下:
def build_model(top_words=top_words,max_words=max_words,num_labels=num_labels,mode='LSTM',hidden_dim=[64]):
if mode=='RNN':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True))
model.add(Dropout(0.25))
model.add(SimpleRNN(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='MLP':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))#, mask_zero=True
model.add(Flatten())
model.add(Dropout(0.25))
model.add(Dense(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='LSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(LSTM(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='GRU':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(GRU(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN': #一维卷积
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(hidden_dim[0], activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN+LSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='BiLSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Bidirectional(LSTM(64)))
model.add(Dense(hidden_dim[0], activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation='softmax'))
#下面的网络采用Funcional API实现
elif mode=='TextCNN':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
## 词嵌入使用预训练的词向量
layer = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
## 词窗大小分别为3,4,5
cnn1 = Conv1D(32, 3, padding='same', strides = 1, activation='relu')(layer)
cnn1 = MaxPooling1D(pool_size=2)(cnn1)
cnn2 = Conv1D(32, 4, padding='same', strides = 1, activation='relu')(layer)
cnn2 = MaxPooling1D(pool_size=2)(cnn2)
cnn3 = Conv1D(32, 5, padding='same', strides = 1, activation='relu')(layer)
cnn3 = MaxPooling1D(pool_size=2)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
x = Flatten()(cnn)
x = Dense(hidden_dim[0], activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=inputs, outputs=output)
elif mode=='Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = MultiHeadAttention(1, key_dim=embed_dim)(x, x,x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.2)(x)
x = Dense(32, activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='MultiHeadAttention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = MultiHeadAttention(8, key_dim=embed_dim)(x, x,x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.2)(x)
x = Dense(32, activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Attention+BiLSTM':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
x = MultiHeadAttention(2, key_dim=embed_dim)(x, x,x)
x = Bidirectional(LSTM(hidden_dim[0]))(x)
x = Dense(64, activation='relu')(x)
x = Dropout(0.2)(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=inputs, outputs=output)
elif mode=='BiGRU+Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
x = Bidirectional(GRU(32,return_sequences=True))(x)
x = MultiHeadAttention(2, key_dim=embed_dim)(x,x,x)
x = Bidirectional(GRU(32))(x)
x = Dropout(0.2)(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Transformer':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = TransformerEncoder(embed_dim, 32, 4)(x)
x = GlobalMaxPooling1D()(x)
x = Dropout(0.25)(x)
outputs = Dense(num_labels, activation='softmax')(x)
model = Model(inputs, outputs)
elif mode=='PositionalEmbedding+Transformer':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x= PositionalEmbedding(sequence_length=max_words, input_dim=top_words, output_dim=embed_dim)(inputs)
x = TransformerEncoder(embed_dim, 32, 4)(x)
x = GlobalMaxPooling1D()(x)
x = Dropout(0.5)(x)
outputs = Dense(num_labels, activation='softmax')(x)
model = Model(inputs, outputs)
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model?这里构建了:“['MLP', 'CNN', 'RNN', 'LSTM', 'GRU', 'CNN+LSTM', 'BiLSTM', 'TextCNN', 'Attention', 'MultiHeadAttention', 'Attention+BiLSTM', 'BiGRU+Attention', 'Transformer', 'PositionalEmbedding+Transformer']”? ?14种模型,大家还可以任意组合自己想要的模型。
定义评价函数和画损失图函数:
#定义损失和精度的图,和混淆矩阵指标等等
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
def plot_loss(history):
# 显示训练和验证损失图表
plt.subplots(1,2,figsize=(10,3))
plt.subplot(121)
loss = history.history["loss"]
epochs = range(1, len(loss)+1)
val_loss = history.history["val_loss"]
plt.plot(epochs, loss, "bo", label="Training Loss")
plt.plot(epochs, val_loss, "r", label="Validation Loss")
plt.title("Training and Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.subplot(122)
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "b-", label="Training Acc")
plt.plot(epochs, val_acc, "r--", label="Validation Acc")
plt.title("Training and Validation Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()
def plot_confusion_matrix(model,X_test,Y_test_original):
#预测概率
prob=model.predict(X_test)
#预测类别
pred=np.argmax(prob,axis=1)
#数据透视表,混淆矩阵
pred=pd.Series(pred).map(dic2)
Y_test_original=pd.Series(Y_test_original).map(dic2)
table = pd.crosstab(Y_test_original, pred, rownames=['Actual'], colnames=['Predicted'])
#print(table)
sns.heatmap(table,cmap='Blues',fmt='.20g', annot=True)
plt.tight_layout()
plt.show()
#计算混淆矩阵的各项指标
print(classification_report(Y_test_original, pred))
#科恩Kappa指标
print('科恩Kappa'+str(cohen_kappa_score(Y_test_original, pred)))
def evaluation(y_test, y_predict):
accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']
s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']
precision=s['precision']
recall=s['recall']
f1_score=s['f1-score']
#kappa=cohen_kappa_score(y_test, y_predict)
return accuracy,precision,recall,f1_score #, kappa定义训练函数:
#定义训练函数
df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score'])
def train_fuc(max_words=max_words,mode='BiLSTM+Attention',batch_size=64,epochs=10,hidden_dim=[64],show_loss=True,show_confusion_matrix=True):
#构建模型
model=build_model(max_words=max_words,mode=mode,hidden_dim=hidden_dim)
print(model.summary())
es = EarlyStopping(patience=5)
history=model.fit(X_train, Y_train,batch_size=batch_size,epochs=epochs,validation_split=0.2, verbose=1,callbacks=[es])
print('——————————-----------------——训练完毕—————-----------------------------———————')
# 评估模型
#loss, accuracy = model.evaluate(X_test, Y_test) ; print("测试数据集的准确度 = {:.4f}".format(accuracy))
prob=model.predict(X_test) ; pred=np.argmax(prob,axis=1)
score=list(evaluation(Y_test_original, pred))
df_eval.loc[mode,:]=score
if show_loss:
plot_loss(history)
if show_confusion_matrix:
plot_confusion_matrix(model=model,X_test=X_test,Y_test_original=Y_test_original)我首先命名了一个df_eval的数据框,用来存放模型预测的效果的评价指标。我们采用准确率,精确值,召回率,F1值四个分类问题常用的指标来进行评价。
我这个训练函数里面包括了很多东西,可以打印模型的信息,然后展示模型的训练,对模型训练过程的训练集和验证集的损失变化都画了图,然后对于预测结果的混淆矩阵和其热力图都进行了展示,还储存了评价指标。
下面初始化参数:
top_words=10000
max_words=200
batch_size=128
epochs=5
hidden_dim=[64]
show_confusion_matrix=True
show_loss=True开始训练,从MLP开始:
train_fuc(mode='MLP',batch_size=batch_size,epochs=epochs)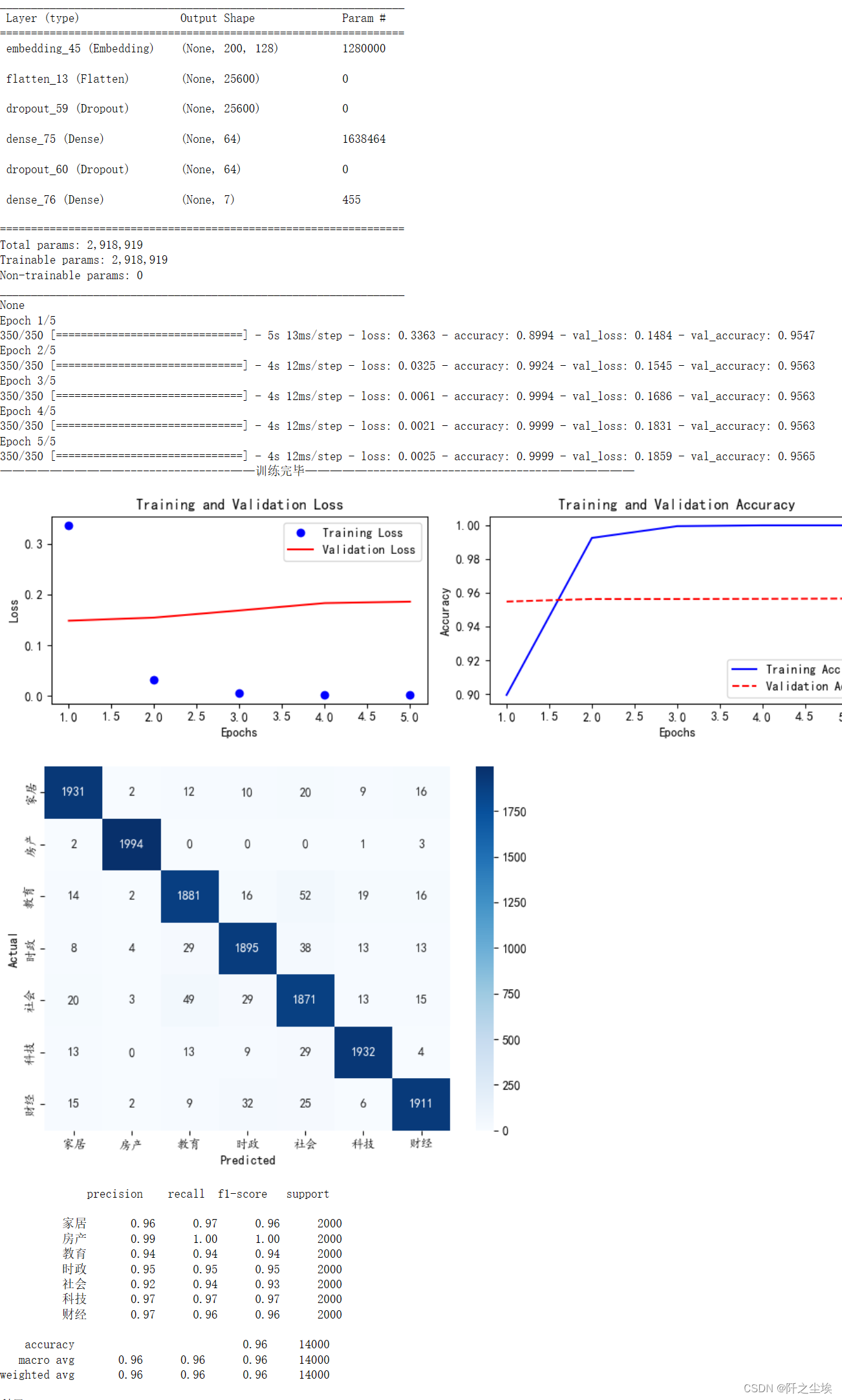
可以看到信息很全面,模型信息,训练过程,混淆矩阵,热力图,都有。
下面其他模型也是一样的:
train_fuc(mode='CNN',batch_size=batch_size,epochs=epochs)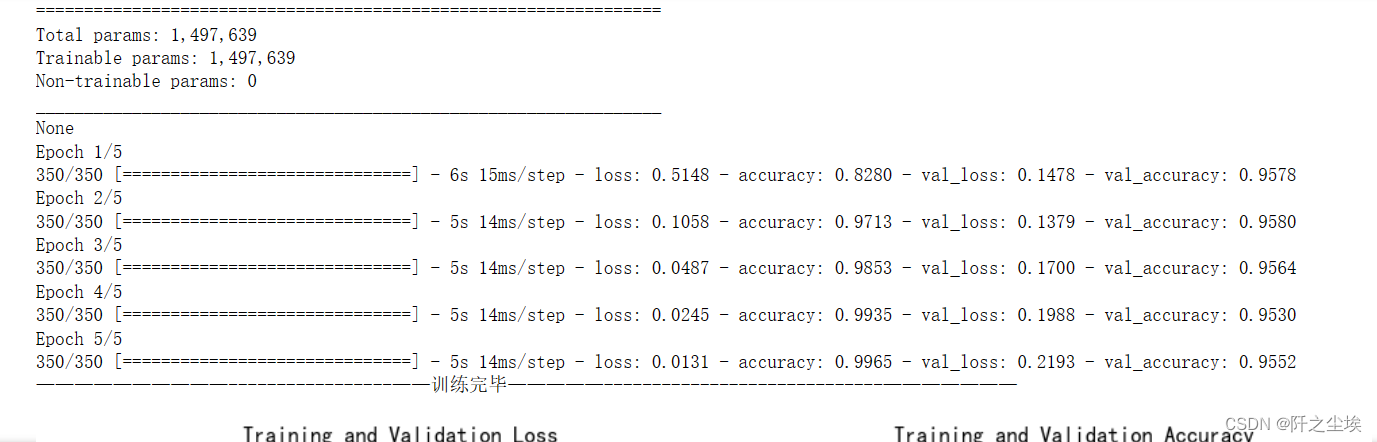
模型大概140多万的参数,可以看到准确率也是95%左右,很高。
下面对其他模型都进行训练,过程很多就不一一展示了,后面一起看评价指标的结果。
train_fuc(mode='RNN',batch_size=batch_size,epochs=8)
train_fuc(mode='LSTM',epochs=epochs)
train_fuc(mode='GRU',epochs=epochs)
train_fuc(mode='CNN+LSTM',epochs=epochs)
train_fuc(mode='BiLSTM',epochs=epochs)
train_fuc(mode='TextCNN',epochs=3)
train_fuc(mode='Attention',epochs=4)
train_fuc(mode='MultiHeadAttention',epochs=3)
train_fuc(mode='Attention+BiLSTM',epochs=8)
train_fuc(mode='BiGRU+Attention',epochs=4)
train_fuc(mode='Transformer',epochs=3)
train_fuc(mode='PositionalEmbedding+Transformer',batch_size=batch_size,epochs=3)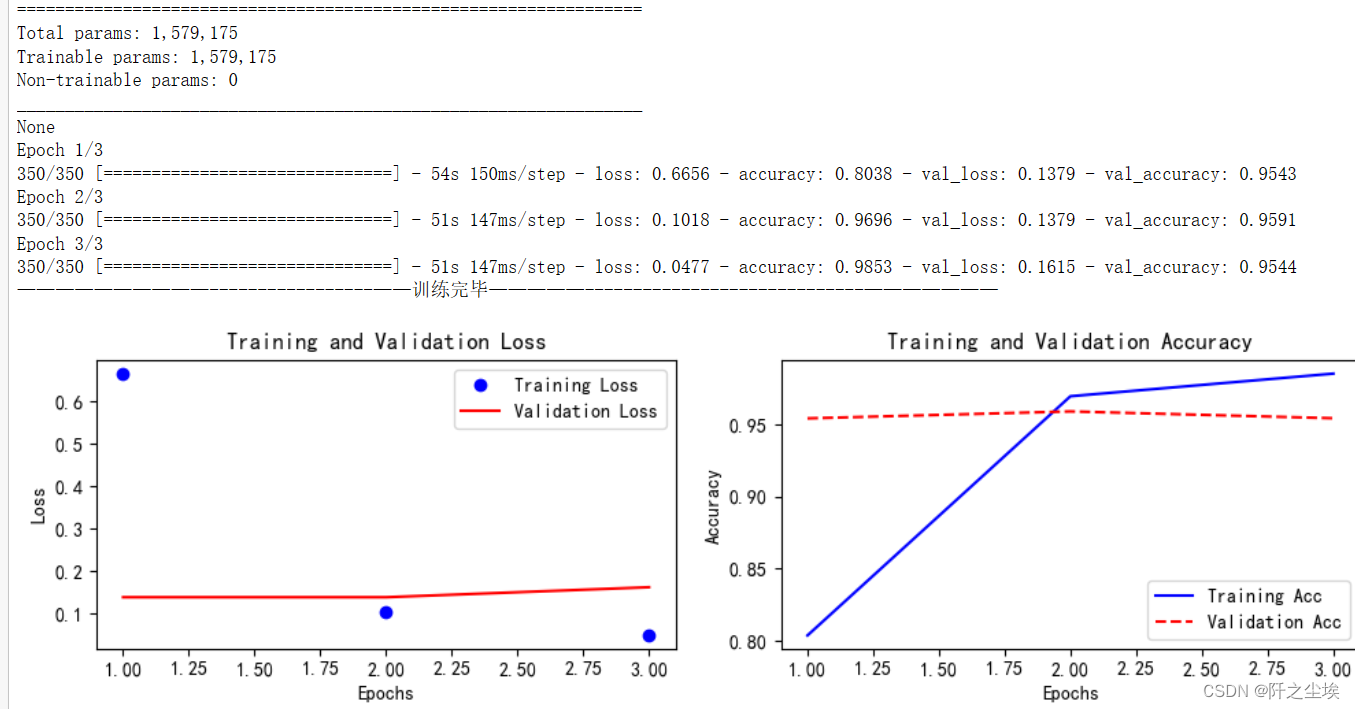
最后这张图是Transformer的,可以看到参数大概157.9w个参数。我只训练了三轮,因为他很容易过拟合。
模型评价
展示所有的评价指标:
?
df_eval.assign(s=df_eval.sum(axis=1))#['s'].idxmax()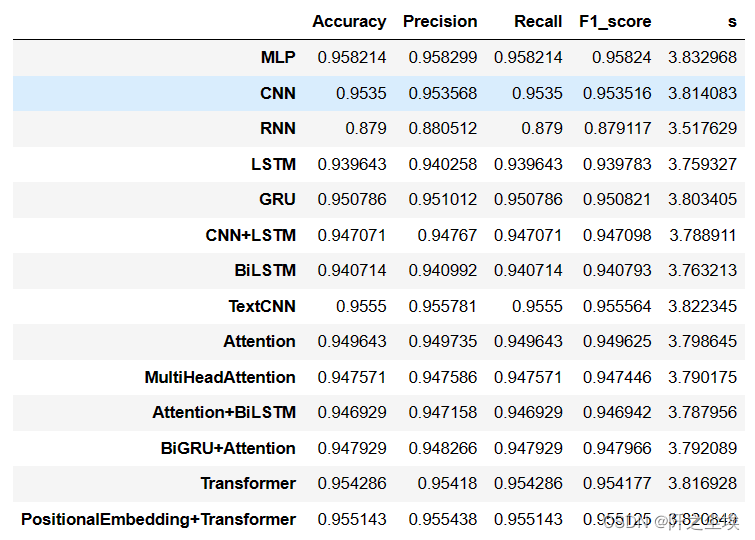
?可以看到,居然是MLP效果最好....我不理解,可能是我设计的结构这个很适合它。但是Transformer效果也不差,加了位置编码效果也变得好了一点。
画出对应的柱状图:
?
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan','gold','r']
fig, ax = plt.subplots(2,2,figsize=(10,8),dpi=128)
for i,col in enumerate(df_eval.columns):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval[col]
m =np.arange(len(df_col))
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=10)
plt.xticks(rotation=40)
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()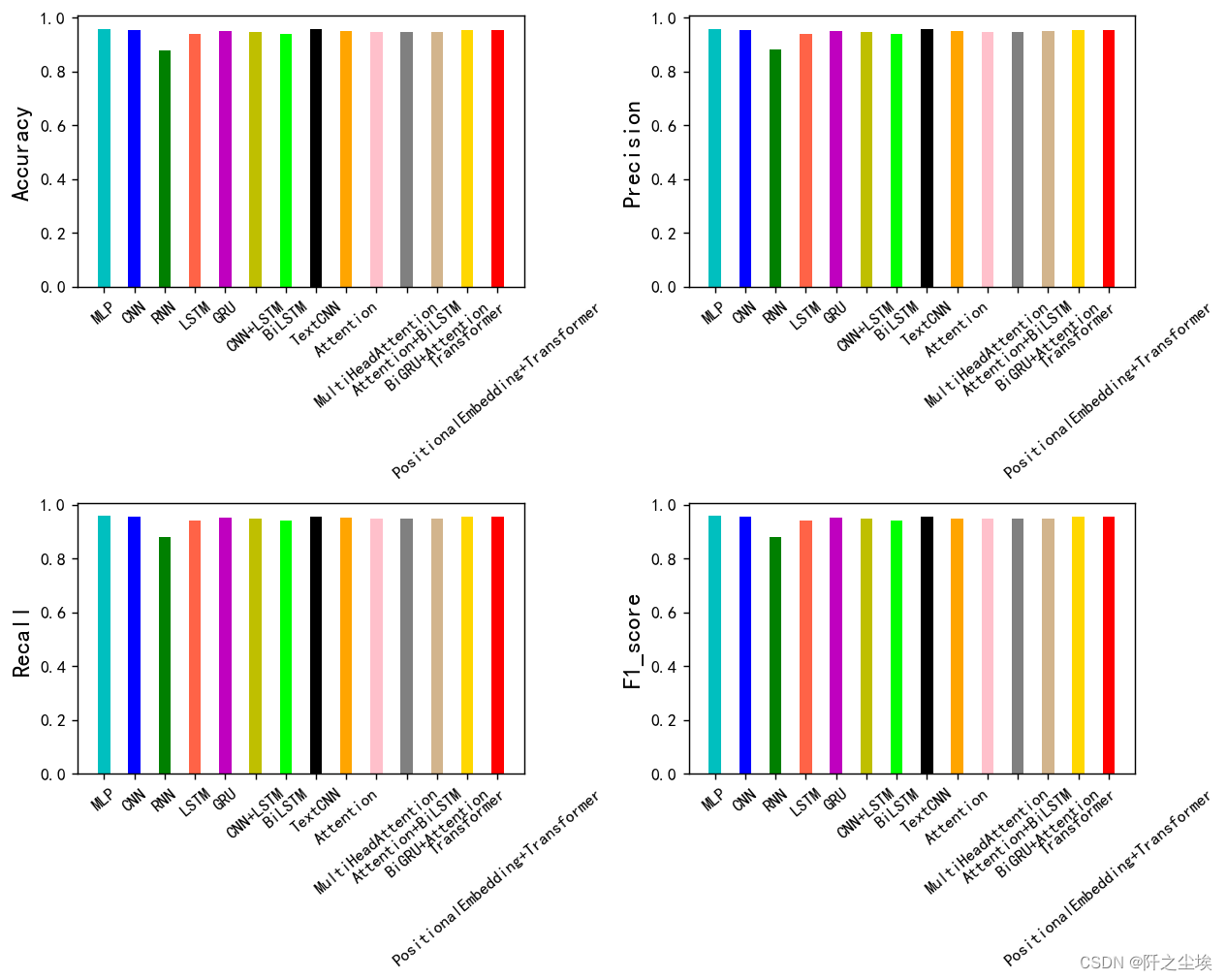
其实模型都差不多,准确率都是95%左右,就RNN离
谱一点。
新来的新闻预测种类
虽然在这个数据集上,Transformer没有吊打其他模型,但是能力来看,肯定是广受验证的Transformer还是最强的,我们选择使用它,单独拿出来在所有的数据集上进行训练,然后对新来的新闻进行预测看看效果。
拿出来训练
model=build_model(max_words=max_words,mode='PositionalEmbedding+Transformer',hidden_dim=hidden_dim)
history=model.fit(X,Y,batch_size=batch_size,epochs=3,verbose=0)找了一个最近很火的新闻,年收入100w的外卖小哥。复制了其新闻的文本:
new_txt='''近日,上海一骑手在短视频平台发布自己“送外卖三年赚了102万”,引发诸多关注,相关话题冲上微博高位热搜。据澎湃新闻报道,26岁的陈思,小学未毕业,二十多岁创业失败,负债来到上海,摸爬滚打3年,逆袭成为上海的“跑单王”之一。
1月15日,有自媒体发布消息称“据说这个外卖小哥被同行打了,帖子配图是陈思鼻子流血的照片,地上还有带血的餐巾纸。陈思表示,这是假消息,他流鼻血是因为之前上火引起,网传图片也不是发生在最近这两天,而是发生在2023年12月。“我没有被同行打,网上图片是因为之前上火了。”陈思说,这段时间自己在正常工作,希望大家不要传谣。
提供外卖小哥3年挣了102万据澎湃新闻报道,陈思是江西抚州人,之前在老家开饭店,为此向银行贷款80万元。据他所说,饭店开了5个月后亏损严重,只得放弃。背负着贷款,陈思决定来上海闯闯看,“当时满脑子就想着挣钱还债,迈出这一步去闯,不会比现在更差,只会更好。”2019年陈思刚来上海时,在饭店当厨师,月薪13000元。厨师干了快一年的时候,他发觉送外卖好像赚得更多,便也想尝试一下。于是,2020年,他加入了众包骑手的队伍,主业做厨师,副业送外卖,“那时比现在还辛苦,一天大概就睡3个小时。”后来,陈思索性辞掉了厨师的工作,专职送外卖。在他自己社交平台的账号视频中,他皮肤粗糙,手上有不少伤痕和冻疮,只看外表很难看出他是个只有二十五六的年轻人。
提供“这三年多,我赚了102万元。”陈思拿出手机展示了自己近期的收入,2023年8月,他在某外卖平台的收入达4万多元,同年9月收入25470元,10月收入19497元,11月收入25786元。澎湃新闻报道称,从相关业内人士和平台方获悉,陈思此前确实多次成为平台众包骑手中的月度“单王”,三年赚了102万元也得到确认。据封面新闻报道,业内人士也表示如果同时在多个平台接单,并且多次成为月度“单王”,三年赚102万元是可以做到的。如今,陈思已还清了开饭店所贷的80万元,因为在老家买房,还背着10万元房贷。陈思坦言,自己把赚钱放在第一位,但也希望大家不要模仿他这样的工作强度,量力而行。
“和努力、能力、运气都有关系”据九派新闻统计,在过往的20篇关于外卖“单王”的新闻报道中,有14篇写出了骑手明确的月薪。在2024年之前,外卖“单王”骑手中,月薪最高的是来自武汉的光谷“单王”陈浩。他在采访中表示,自己2022年年全年收入22万元,单月最高收入可达23567元。“单王”们的收入远超普通骑手。根据饿了么在2018年发布的《2018外卖骑手群体洞察报告》,4成的骑手收入在4000-6000元之间。收入超过1万元的骑手比例不足2%。在美团发布的《2018年外卖骑手群体研究报告》中,同样指出月收入在万元以上的骑手比例基本不足1%。
而在这种超额薪资的背后,所有的外卖“单王”都表现出了惊人的工作时长。在20篇新闻报道中,有10篇报道都明确提及了他们的工作时长。其中有5名单王在采访中都表示自己一天的工作时长超过16个小时。2017年的济南“单王”韩化龙还表示“一年365天,我能跑360天。”在接受潇湘晨报采访时,陈思表示,他没有任何社交和娱乐活动,每天就是上班和睡觉。“我是在两个不同的平台跑,平均每个月可以有3万,最高的一个月有6万,这跟很多因素有关,你的努力、能力、运气都有关系,而且我不挑活,有活就干,平台给我活我就干,平台没活给我干的话我就干别的平台。”陈思透露,他一天多的时候可以跑200多单,有时候180多单,有的距离远的或者点得多的平台会有补贴。
前两年疫情的时候,有的不能送上楼或者送进小区,这种单子用时短,送得就快。在花费方面,“我每个月的花费大概在2000到2500元,800的房租,
其他花销就是吃饭,基本没有多余的花销。”陈思表示。有网友质疑他几分钟就要跑一单,陈思解释称,“我出去跑一圈,最多能带12单,对路线对商家的出餐速度都要熟悉。有时候一个顾客连续下单,连续4单都是我一个人送,这跟运气也有关系,但跟努力更有关系,努力大于一切。我知道很多人不相信我一个月可以赚到这么多钱,但没关系,这无所谓,反正我做到了就可以。'''自定义一个类别处理函数
def predict_newkind(new_txt,token=tok):
dic2={0: '教育', 1: '科技', 2: '社会', 3: '时政', 4: '财经', 5: '房产', 6: '家居'}
new_txt=txt_cut(new_txt)
new_text_seq = tok.texts_to_sequences([new_txt])
new_text_seq_padded = sequence.pad_sequences(new_text_seq, maxlen=200)
predictions = model.predict(new_text_seq_padded)
predicted_class = np.argmax(predictions, axis=1)
return dic2[predicted_class[0]]预测:
?
predict_newkind(new_txt)
确实没问题,这个是社会类的新闻。
再来一条chatgpt 的新闻放入看看:
new_txt='''1.科学家使用世界最强大的超级计算机的仅8%算力,成功训练出ChatGPT规模的模型。
2.Oak Ridge National Laboratory的研究团队在Frontier超级计算机上使用创新技术,仅用数千个AMD GPU训练了一个拥有万亿参数的语言模型。
3.通过分布式训练策略和各种并行技术,研究团队实现了在仅占用Frontier计算能力8%的情况下,训练1750亿参数和1万亿参数模型的百分之百弱扩展效率。
站长之家(ChinaZ.com)1月10日 消息:科学家们在世界上最强大的超级计算机上取得了巨大突破,仅使用其8%的计算能力,成功训练了一个与ChatGPT规模相当的模型。这项研究来自著名的Oak Ridge National Laboratory,他们在Frontier超级计算机上采用了创新技术,仅使用数千个AMD GPU就训练出了一个拥有万亿参数的语言模型。
通常,训练像OpenAI的ChatGPT这样规模的语言模型需要一个庞大的超级计算机。然而,Frontier团队采用了分布式训练策略,通过优化并行架构,仅使用Frontier计算能力的8%就成功完成了这一任务。具体而言,他们采用了随机数据并行和张量并行等技术,以降低节点之间的通信,同时处理内存限制。
这项研究的结果显示,在1750亿参数和1万亿参数模型的情况下,弱扩展效率达到了100%。此外,这个项目还取得了这两个模型的强扩展效率分别为89%和87%。
然而,训练拥有万亿参数的大型语言模型始终是一个具有挑战性的任务。研究人员指出,这个模型的体积至少为14TB,而Frontier中的一块MI250X GPU只有64GB。他们强调,需要进一步研究和开发方法来克服内存问题。
在面临大批次大小导致的损失发散问题时,研究人员提出,未来关于大规模系统训练时间的研究必须改善大批次训练,并采用更小的每副本批次大小。此外,研究人员呼吁在AMD GPU上进行更多工作,指出目前大多数大规模模型训练都是在支持Nvidia解决方案的平台上进行的。尽管研究人员为在非Nvidia平台上高效训练大型语言模型提供了“蓝图”,但他们认为有必要更深入地研究在AMD GPU上的高效训练性能。
Frontier在最近的Top500榜单中保持其作为最强大超级计算机的地位,超过了Intel推出的Aurora超级计算机。这项研究为未来训练巨大语言模型提供了宝贵的经验和方法,同时也突显了分布式训练和并行计算在实现这一目标上的关键作用。'''predict_newkind(new_txt)
一点问题都没有!!,还是不错的。
保存模型
这样下次就不用训练了,可以直接使用:
import pickle
from tensorflow.keras.models import save_model
# 保存Tokenizer
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
model.save('my_model.h5') # 保存模型到HDF5文件除了模型,还保存了词表,毕竟中文词映射为数字需要一个对照表的。
下次要用的话就不用训练了,直接载入就行:
?
from tensorflow.keras.models import load_model
import pickle
with open('tokenizer.pickle', 'rb') as handle:
tok = pickle.load(handle)
model = load_model('my_model.h5', custom_objects={'PositionalEmbedding': PositionalEmbedding,'TransformerEncoder':TransformerEncoder})然后一样预测
new_text = '''11 月新增社融略同比多增,贷款同比少增,货币增速继续下滑。从需求端来看,政府部门融资较强,低基数下居民部门融资大体持平,但企业部门融资偏弱。在社融增速并不高的情况下,资金利率中枢上升,我们认为主要的原因是基础货币供应放缓。向前看,中国货币投放进入新阶段,信贷的作用下降,市场可能需要调整信贷预测的“基准”。
无论是融资总量还是资金市场利率,财政可能都是一个关键的因素。
11 月新增社融略同比多增,贷款同比少增,货币增速继续下滑。11 月新增社融2.45 万亿元,同比多增4556 亿元。
11 月新增人民币贷款1.09 万亿元、同比少增1368 亿元,M2 增速持从10 月的10.3%下降至10.0%,M1 增速继续下降至1.3%。
从需求端来看,政府部门融资较强,低基数下居民部门融资大体持平,企业部门融资偏弱。11 月政府债券净融资1.15 万亿元,占了全部新增社融的47%,同比多增4992 亿元,是支撑社融的主要动力:
11 月居民部门净融资并不算强。2022 年11 月,居民净融资为2628 亿元,同比大幅下降。在2022 年低基数的背景下,11 月居民部门净融资为2925 亿元,同比小幅增长297 亿元,其中新增居民中长期贷款2331 亿元,较去年同期多增228 亿元。居民短期贷款净增加594 亿元,相比去年同期多增69 亿元。
11 月企业部门融资偏弱,中长期贷款同比明显减少。11 月企业部门的融资为9960 亿元,同比增加155 亿元,但是主要依靠短期贷款及票据冲量,11 月企业短期贷款及表内外票据加总净融资4000 亿元,同比多增2501 亿元,这种短期融资的强势可能难以持续。11 月企业中长期贷款新增4460 亿元,同比少增2907 亿元,主要是由于去年政策性开发性金融工具带来的高基数。
在社融增速并不高的情况下,资金利率中枢上升,我们认为主要的原因是基础货币供应放缓。虽然社融增速从9.3%小幅上升至9.4%,但是较去年同期下降0.9 个百分点,总体融资并不强。总体融资需求不强也反映在票据利率当中:票据利率11 月全月平均值为1.23%,较10 月的1.32%有所下降。但从资金市场来看,DR007 的11 月中枢为1.97%、R007 的11 月中枢为2.36%,相对10 月基本持平、相比9 月继续上升,而同期公开市场操作利率为1.80%。我们认为,资金市场利率的走势,可能与基础货币的供应有关,而基础货币供应同时受到内外因素的影响。
内因来看,10 月-11 月,财政存款上升的1.04 万亿元,同比多增2688 亿元,起到暂时性起到回笼基础货币的作用。
外因来看,7-10 月以人民币币种计价的涉外收付款为逆差,7-10 月累计逆差相当于基础货币总量的2.4%。
向前看,中国货币投放进入新阶段,信贷的作用下降、财政的作用上升,市场可能需要调整信贷预测的“基准”。在《货币变局重塑市场格局》中我们提出,21 世纪初以来我国货币投放大致可以被分为三个阶段。第一个阶段是2003-2009 年,外汇占款的重要性逐步上升;第二个阶段是 2010-2017 年,信贷投放成为货币投放的主力渠道。2018 年至今,虽然信贷在货币投放中的力量仍然不低,但财政发挥的作用明显变强。由于过去支持信贷增长的金融周期已经进入下行阶段,房地产动能的减弱、地方债务的化解,都会拖累信贷增长。12 月10 日经济日报的社论指出1 ,“短期一味强求‘同比多增’,不但不符合经济发展规律,反而可能造成‘虚增’‘空转’,甚至透支中长期增长潜能。”无论是融资总量还是资金市场利率,财政可能都是一个关键的因素。从融资量来看,由于金融周期下行,信贷需求内生下行,更加需要财政发力托底融资需求,随着1 万亿元增发国债逐步落地,财政融资可能保持较快节奏,对社融形成支撑。从资金市场利率来看,财政支出加快会使得财政存款从国库加快回到资金市场当中,可能会降低资金市场利率。考虑到年末季节性资金需求较大,明年年初信贷投放可能加快、对流动性需求不低,我们不排除近期降准可能。
'''
predict_newkind(new_text)
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制代码可私信)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一向高调的万达,今年为何如此低调?2024最受欢迎的创业项目,2024新的创业机会
- 【双指针算法】-- 左右指针
- 前端构建工具对比 webpack、vite、esbuild等
- ERP学习笔记20240122
- uniapp scroll-view 点击左右方向按键自动滚动到设置位置
- 首款原创产品uniapp开发的一番赏潮玩小程序php源码现已上线!一番赏潮玩小程序玩法介绍
- “揭秘性能测试工具:优化软件性能的关键秘籍“
- Flutter实现windows应用版本升级功能
- 【Redis集群】docker实现3主3从扩缩容架构配置案例
- 为什么我要推荐大家使用Spring Cloud Alibaba?