TPAMI: 基于强化学习的灵巧双手操作技能学习
最近,强化学习(RL)算法在许多需要决策领域的表现都优于人类专家。与传统的控制方法相比,RL可以在学习灵巧手操作方面完成一些具有挑战性的任务,但需要组合和泛化复杂的操作技能的能力才能在非结构化或接触丰富的环境中较好地执行。简言之,达到人类水平灵活性和双手协调能力的机器手仍然是现代机器人研究人员面临的挑战。
为了帮助解决上述问题,我们为RL算法开发了一个新的双手灵巧操作基准:一组名为Bi-DexHands的灵巧操作任务。我们遵循精细运动亚测试(FMS)的原则设计了数十项任务,为观察和评估特定技能提供了机会;接着测试了各种无模型RL算法的基线,以展示基线算法在这些任务中的能力。我们测试的算法除了标准RL算法,还有多智能体RL(MARL)、离线RL、多任务RL和元RL算法。

A.Bi-DexHands任务总览;B.一些成功和失败的例子;C.提供的多模态观测
Bi-DexHands具有以下特性:
? 高效率:
在IsaacGym模拟器的基础上,Bi-DexHands支持同时运行数千个环境。在一个NVIDIA RTX 3090 GPU上,Bi-DexHands可以通过并行运行2048个环境达到30000多平均FPS。
? 全面的RL基准:
我们为通用RL、MARL、Offline RL、Multi-task/Meta-RL从业者提供了第一个双手动操作任务环境,以及SOTA的连续控制无模型RL方法的综合基准。
? 异构智能体协作:
Bi-DexHands中的智能体(即关节、手指、手…)是真正的异构;这与常见的多智能体环境(如SMAC)不同,在SMAC中,智能体可以简单地共享参数来解决任务。
? 任务泛化:
我们从YCB和SAPIEN数据集中引入了各种灵巧的操作任务(例如,移交、举起、投掷、放置、放下…)需要的大量目标物体,从而允许在任务泛化方面测试Multi-task/Meta-RL算法。
? 认知科学:
我们提供了不同年龄段人类的灵巧任务和运动技能之间的潜在关系。这有助于研究人员研究机器人的技能学习和发展,特别是与人类相比。
02
通向人类水平的双灵巧手操作任务
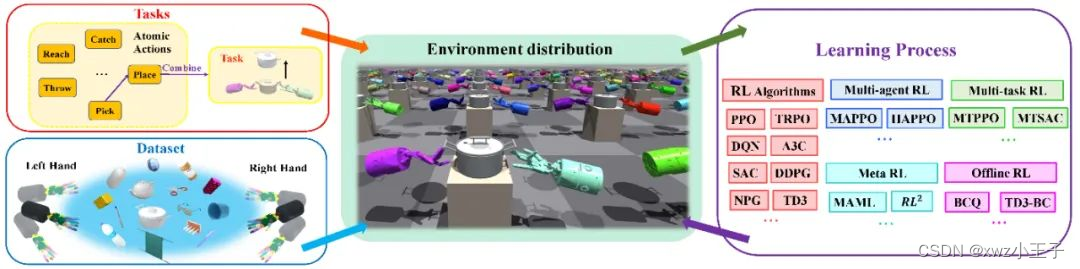
系统设计
Bi-DexHands的核心是建立一个学习框架,让两个灵巧手能够像人类一样掌握各种技能,如伸手、扔东西、接球、捡东西以及放置。具体来说,Bi-DexHands由三个组件组成:数据集、任务和学习算法,如下图所示。同时,与不同年龄段儿童的行为相对应的各种任务使其有可能像人类一样学习灵活性。结合数据集和任务,我们可以为强化学习算法生成特定的训练环境或场景。最终,我们的实验表明,强化学习能够帮助机器人在这些具有挑战性的任务中取得一些显著的成果,而且在未来的工作中还有一些改进的空间和以及挑战更困难的任务。
Bi-DexHands的框架,一个用于学习双手灵巧操作的模拟平台
基于认知科学设计任务
婴儿的行为经历了多阶段的发展,如社交、沟通和身体发育。特别是在双手灵巧操作中,婴儿的一些常见行为与年龄之间存在一定的关系。我们根据认知科学相关文献,研究了婴儿年龄与技能发育之间的关系,结果如下图所示。
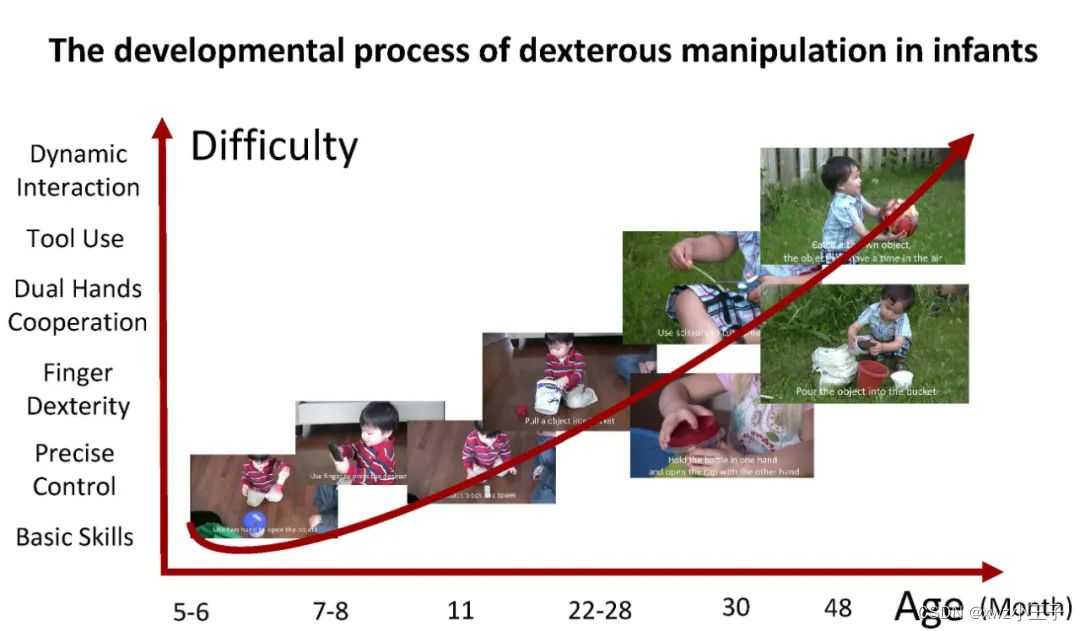
婴儿灵巧操作的发育过程
为了深入了解潜在的关系,我们进行了深入的分析,并根据精细运动亚测试(FMS)建立了婴儿年龄和任务之间的映射。随着宝宝年龄的增长,完成设计任务的难度也随之增加,因为随着身体的发育,宝宝可以完成越来越多的高难度行为。因此,评估经过训练的智能体的表现也非常重要,因为我们可以通过类比婴儿的双手灵巧操作来大致指出智能体的智力水平。我们的任务与FMS的对应关系概述如下表所示。

Bi-DexHands的任务名称和相对应年龄的人类操作技能
跨任务泛化性能力研究
我们的多任务/元强化学习任务的设计类似于Meta-World,分为ML1、MT1、ML4、MT4、ML20和MT20,是由我们精心设计的上述单个任务组合而成的。因此,MT1 和 ML1、MT4 和 ML4、MT20 和 ML20 在使用的单个任务上面都是相同的,区别在于:1)ML类别仅使用一部分任务作为元训练集,另一部分用于元测试集,而MT类别都是一起训练的。2)从观察的角度来看,多任务强化学习增加了一个一维向量来表示任务ID,而元强化学习屏蔽了与目标相关的观察,这需要元强化学习算法自行学习出需要的知识。下图可视化了我们的多任务和元类别的详细设计。

我们的多任务强化学习和元强化学习的评估方案可视化
视觉输入
视觉输入对于强化学习在现实世界中应用至关重要,在大部分场景中,直接获取操作物体的状态是非常难的。Bi-DexHands 提供了多个可供选择的选项,可以使用 RGB 图像、RGBD 图像和点云作为输入来训练强化学习策略。我们使用一个或多个相机用于捕获RGB和RGBD图像,然后将其转换为点云。为了确保手和物体的最佳观察效果,相机的位姿和朝向都针对每项任务进行了精心设计。在视觉输入的情况下,Bi-DexHands也支持教师-学生方法。这类方法使用易于训练的输入(例如6D姿态)训练策略作为教师,来收集具有较难训练的输入的示教数据(例如点云),并使用模仿学习来训练基于示教的学生策略。
多样化的灵巧手和机械臂
不单止Shadow Hand,有许多不同种类的灵巧手,如allegro hand, trifinger等。支持其他类型的灵巧手有助于推进社区研究的发展。因此,除了Shadow Hand之外,我们还在Bi-DexHands中提供了四种其他灵巧的多指手。此外,在灵巧的手底部使用机械臂驱动器不仅符合现实世界的设置,而且也是虚实迁移必须要做的一步,因为漂浮在半空的手的动力学很难与现实世界相匹配,因此会扩大sim2real gap。更多地,我们还提供各种机械臂和各种灵巧手的组合,这有很多好处。例如,研究人员可以根据自己实验室的情况选择自己想要的手,这为我们的平台带来了更广泛的适用性。同时,我们可以研究策略在不同的机械臂、不同的灵巧手上的适应性和泛化能力,这对未来的多任务学习和元学习研究提出了挑战。
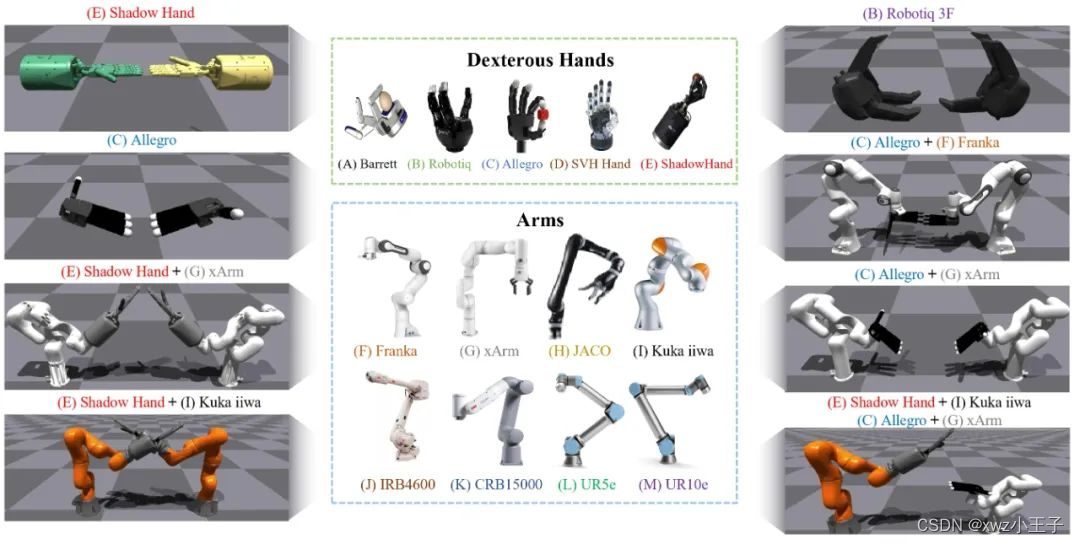
Bi-DexHands为灵巧手和机械臂提供了多种选择,使用户能够自定义他们的配置
03
实验结果
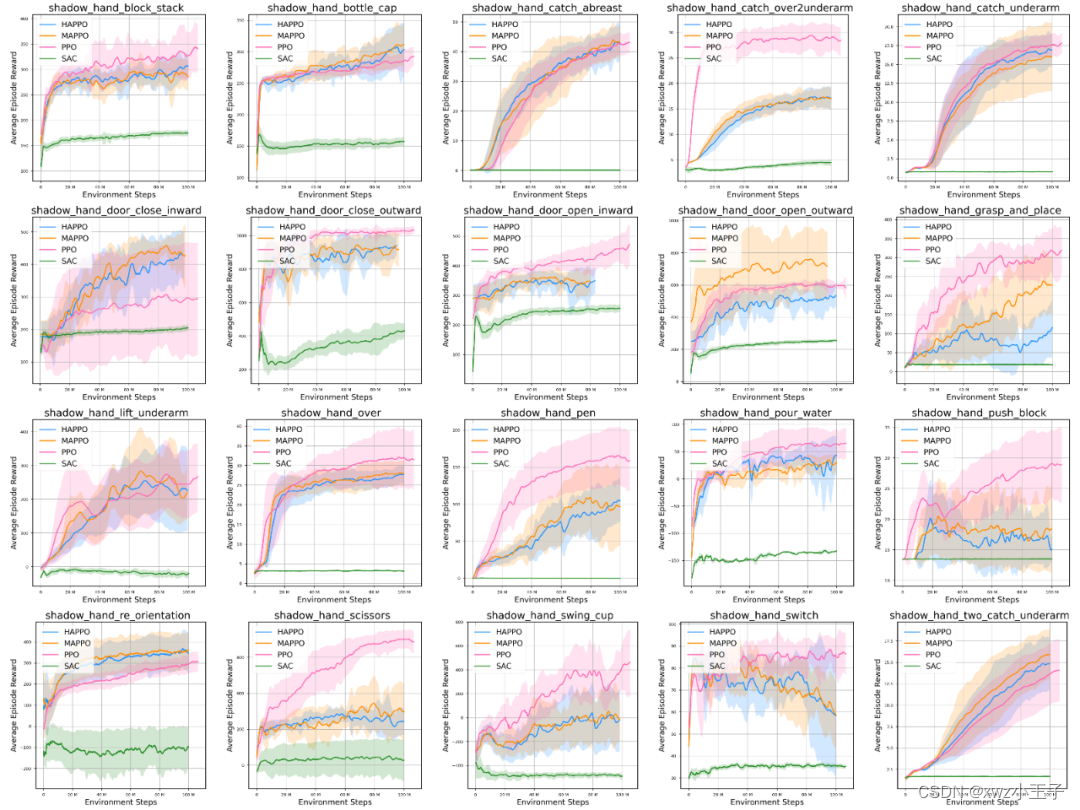
- RL/MARL 结果
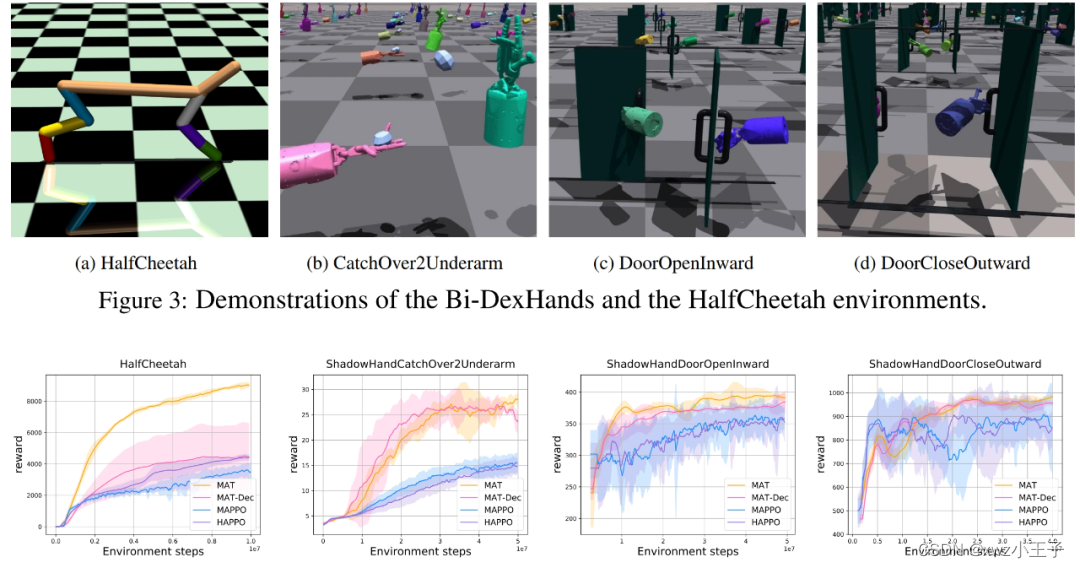
目前,我们评估了PPO、SAC、TRPO、MAPPO、HATPO和HAPPO算法在这20项任务中的性能。每个算法的性能如图所示。可以观察到,PPO算法在大多数任务上都表现良好。虽然有些任务需要双手配合,但PPO算法在大多数情况下仍然优于HAPPO、MAPPO算法。这可能是因为PPO算法能够使用所有观测来训练策略,而MARL只能使用部分观测。然而,在大多数任务中,难度越大、需要双手协作的PPO与HAPPO、MAPPO之间的性能差距越小,表明多智能体算法可以提高双手协作操作的性能。另一个发现是SAC算法不适用于几乎所有的任务。这可能是由于1)Off-policy算法在高采样效率方面的提升低于On-policy策略。2) SAC的策略熵给高维输入下的策略学习带来了不稳定性。
所有 20 个任务的学习曲线。阴影区域表示 10 次试验中分数的标准差
- 泛化能力
我们的泛化性评估的方法是1)找出当前多任务和元强化学习算法在我们设计的任务上进行泛化的能力。2) 探究是否对婴儿来说更难的任务对RL来说是否也更难。先前的RL/MARL结果已经证明了我们的单个任务是可解的。对于1),我们评估了MT1、ML1、MT4、ML4、MT20和ML20上的多任务PPO和ProMP算法。我们还提供了随机策略,并在单个任务中使用PPO算法的结果作为比较。每次测试的结果如下表所示。我们可以观察到,多任务PPO的性能并不好,与随机策略相比,ProMP的性能提升很小。这可能是因为在Bi-DexHands中,每个任务本身学习难度就非常大。因此,在交叉任务设置下,我们仍有很大的空间来提高双手灵巧手的泛化能力,这对社区来说是一个有意义的开放挑战。总的来说,随着任务所对应的人的年龄增加,RL的难度也随之增加,这证明了我们的任务设计是合理的,与人类灵巧操作的发展相关。
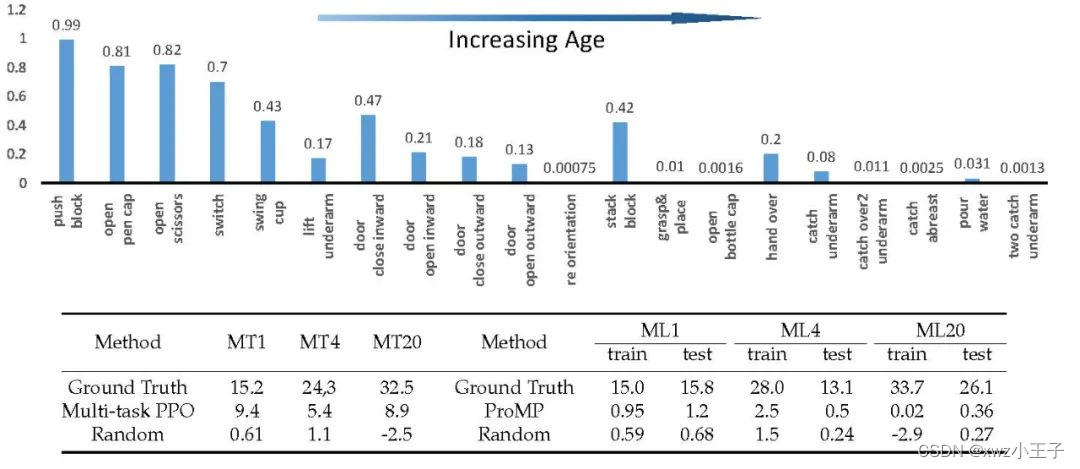
MT1、ML1、MT4、ML4、MT20 和 ML20 中所有任务在 10 个种子下的平均奖励,以及 MT20 方案下 MTPPO 算法的标准化奖励
- 使用视觉信息作为输入
我们研究了使用视觉信息而不是物体状态信息来完成具有挑战性的双手灵巧操作任务的可行性。结果如图所示。图中的PPO表示直接使用物体状态信息作为,PPO+PC表示PPO算法使用点云输入的训练结果,DAPG表示使用教师-学生方法在使用PPO算法提供的示教数据上进行训练的结果。据观察,使用点云输入的PPO性能较差,特别是在依赖物体信息的投掷和接球任务中。这表明直接使用点云而不是物体状态对于任务来说可能具有挑战性。然而,DAPG 的性能良好,其中大多数都达到了与直接使用物体状态信息的 PPO 相同的性能。这表明教师-学生方法是有效的。DAPG的方差远小于PPO。再加上 PPO 在点云输入时表现不佳,表明DAPG 算法训练的策略很可能只是记住灵巧手完成任务所需的动作,而较少使用视觉信息。因此,提高强化学习算法利用视觉观测信息的能力可能是一个很有前途的研究方向。
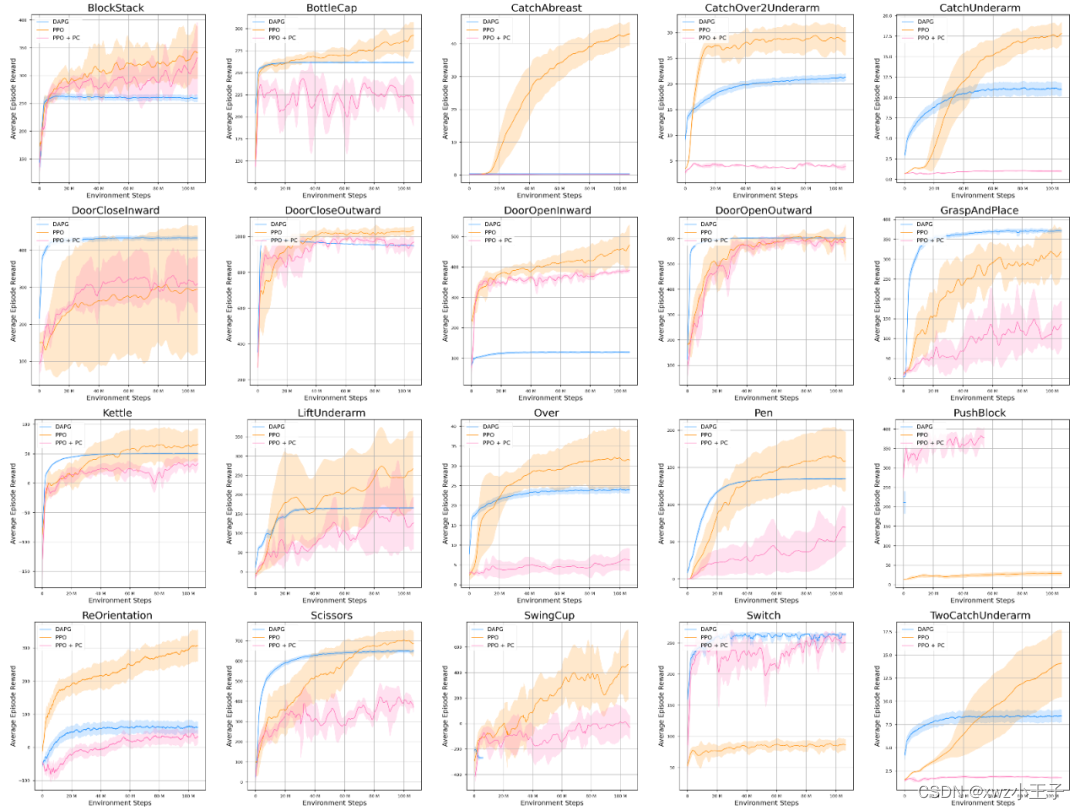
使用点云作为观测的所有 20 项任务的学习曲线。阴影区域表示 10 次试验中分数的标准差
04
总结
我们介绍了Bi-DexHands仿真环境,它由精心设计的任务和大量用于学习双手灵巧操作的物体组成。我们从认知科学角度研究了婴儿灵活性的运动发展过程,并根据研究结果为RL精心设计了20多项任务,希望机器人能像人类一样学习灵活性。在Isaac Gym模拟器的帮助下,它可以并行运行数千个环境,提高RL算法的采样效率。此外,所实现的RL/MARL/Offline RL算法在所需的简单操作技能的任务上实现了卓越的性能。与此同时,复杂的操作仍然具有挑战性。特别是,当需要训练智能体掌握多种操作技能时,Multi-task/Meta-RL的结果并不令人满意。有趣的是,我们发现在多任务环境下,RL表现出与人类智力发展相关的结果,即RL表现的趋势与人类年龄的发展相匹配。到目前为止,在双手灵巧操作中,强化学习可以达到48个月婴儿的水平。
???
Bi-DexHands为灵巧手领域赋能
Bi-DexHands为灵巧手领域提供了一个可复现的基准和具有高采样效率的强化学习训练环境。例如,下面两个项目是使用Bi-DexHands作为benchmark的工作:
- Eureka: Human-Level Reward Design via Coding Large Language Models

Eureka: Human-Level Reward Design via Coding Large Language Models
网站:https://eureka-research.github.io/
论文:https://arxiv.org/abs/2310.12931
- Multi-Agent Reinforcement Learning is a Sequence Modeling Problem
Multi-Agent Reinforcement Learning is a Sequence Modeling Problem
网站:https://sites.google.com/view/multi-agent-transformer
论文:https://arxiv.org/ abs /2205.14953
同时,Bi-DexHands也为灵巧手操作领域提供了一个易使用的代码库。例如,下面两个项目是使用Bi-DexHands构建机器人环境训练策略,并sim2real transfer到现实世界机器人上的项目:
- Dynamic Handover: Throw and Catch with Bimanual Hands
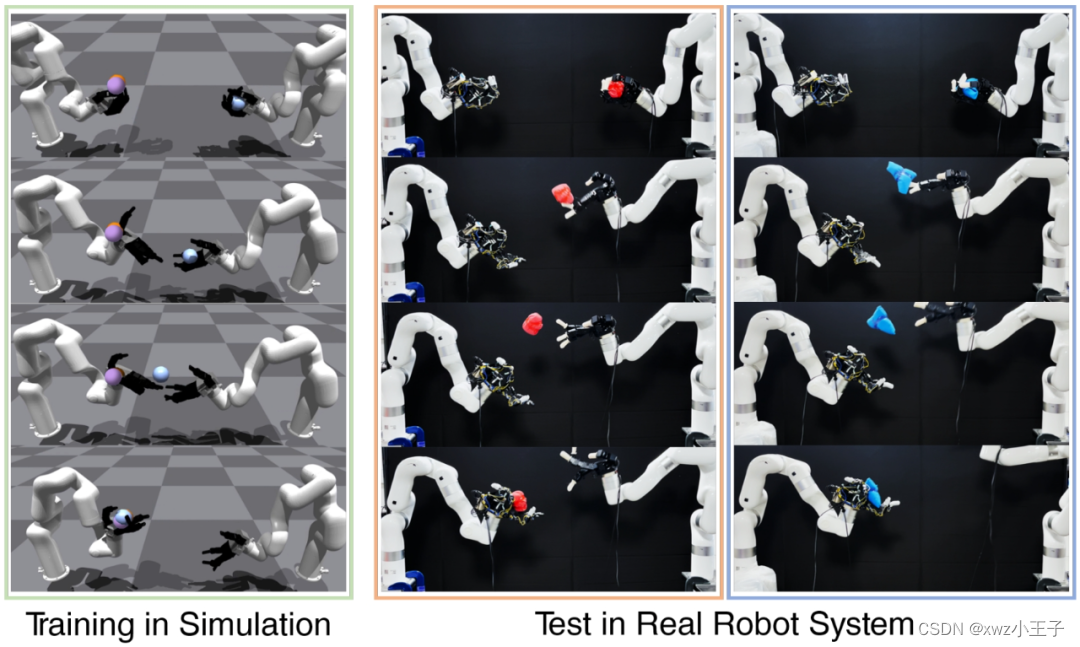
Dynamic Handover: Throw and Catch with Bimanual Hands
网站:https://binghao-huang.github.io/dynamic_handover/
论文:https://arxiv.org/abs/2309.05655
- Sequential Dexterity: Chaining Dexterous Policies for Long-Horizon Manipulation
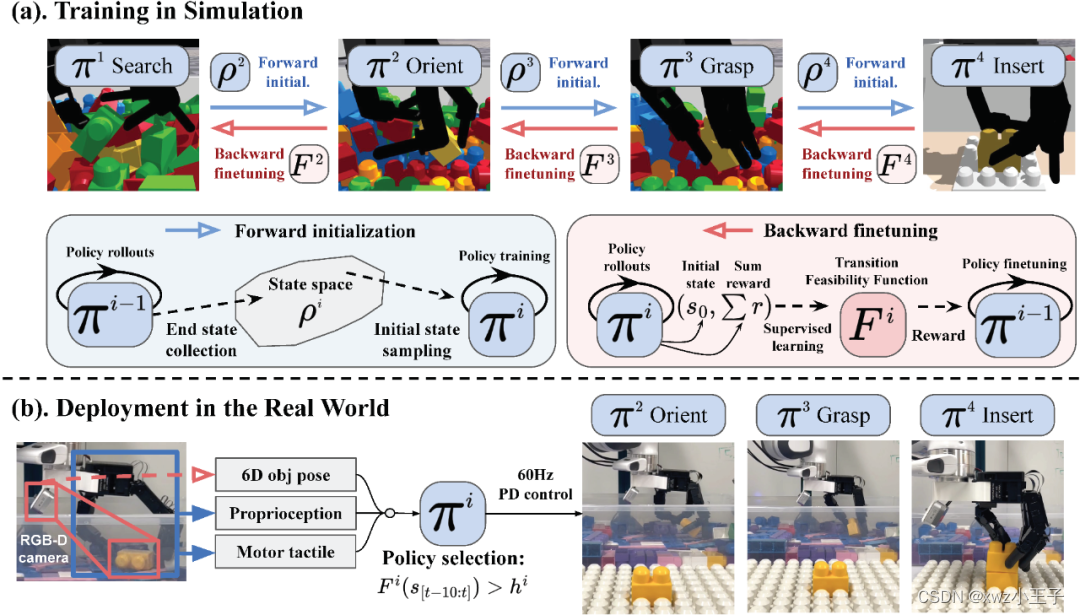
Sequential Dexterity: Chaining Dexterous Policies for Long-Horizon Manipulation
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 天天crud?试试这个低代码框架
- 《汇编语言》- 读书笔记 - 第8章 - 数据处理的两个基本问题(阶段总结)
- 网络体系结构小小知识点
- 案例086:基于微信小程序的影院选座系统
- 工地富维AI安全帽识别系统解决方案
- Fiddler -- https配置
- 生成超清分辨率视频,南洋理工开源Upscale-A-Video
- C++ 第十章 多态
- html form中的input有哪些类型?各是做什么处理使用的
- leetcode(平衡二叉树)