MySQL函数练习(文字说明、代码示例、执行结果截图)
? ? ? ? 之前的一个项目涉及到很多关于时间的操作,也用到了一些函数,最近整理了MySQL中各种函数的使用,图文结合,简单易懂,请各位看官往下看↓↓↓
目录
replace(str,replace_str,target_str)
date_add(日期,interval num 时间单位)
timestampdiff(unit,start_date,end_date)
字符串操作
-
length(str)
计算字符串长度,对于utf-8字符集来说,一个英文、数字、空格占1个字节;一个中文占3个字节
select length('123aa'), length(123456), length('你好 ');
-
left(str, len)
str是要处理的字符串,len是要返回的字符数
# 如果str的长度小于len,则返回整个str。若字符串字符数大于len,则从左边取len个字符。
select left('123', 5), left('你好hello', 4);
-
concat(str1,str2,...)
将多个字符串拼接
select concat('191', '-', '7760', '-', '6666'), concat('123', '你好');
-
upper(str)、lower(str)
upper(str):将字符中的所有字母变为大写
lower(str):将字符中的所有字母变成小写
select upper('abc123N你好'), lower('abc123N你好');
-
substr(str,start,len)
截取字符串,start为字符开始位置(包含),len为结束位置
# 从第2个字符开始,截取2位,MySQL中字符串起始位置为1,不像编程语言中从0开始
select substr('hello', 2, 2), substr('你好呀', 2, 1);
-
instr(str,sonStr)
返回子串第一次出现的索引(按字符数数),如果找不到,返回0
select instr('你好abc123练习MySQL练习', '练习'), instr('练习MySQL练习', 'hello');
-
trim(str)
去除字符串前后空格,中间的无法去除
select trim(' 12 你好 test '), length(trim(' 12 你好 test '));
-
左填充lpad(str,len,insertStr)
用指定的字符,实现对字符串左填充指定长度,len指填充完毕后字符串总长度,不是要填充的长度
select lpad('你好', 7, 'a1');
-
右填充rpad(str,len,insertStr)
用指定的字符,实现对字符串右填充指定长度
select rpad('你好', 7, 'a1');
-
replace(str,replace_str,target_str)
将str字符串中的replace_str子串替换为target_str
select replace('你好hello', '你好', 'hello-');
数学计算
-
round(x,保留位数)
四舍五入,负数的先去除负号再计算最后把负号再补回去
select round(3.14159265, 3), round(3.66, 0), round(-3.14159265, 3);
-
ceil(x)
向上取整,取大于等于该数的整数
select ceil(3.14159), ceil(3.99999), ceil(-3.14159);
-
floor(x)
向下取整,取小于等于该数的整数
select floor(3.14159), floor(3.99999), floor(-3.14159);
-
truncate(number,len)
截断函数,从小数点后面取len位,超过部分直接舍弃,为0则舍弃小数部分
select truncate(3.14159, 2), truncate(3.14159, 0), truncate(3.14159, -1);
# 12340000,len为负数时去掉小数部分,整数部分位数不变,-4表示整数后4位置零
select truncate(12345666.14159, -4);?
-
mod(被除数,除数):取余
# 除数为负数时,仍为正数时的结果
select mod(10, 3), mod(10, 2), mod(10, 4), mod(10, -4);
-
pow(number,e):指数计算
select pow(3, 3), pow(-3, 3);
-
format():格式化数字
# 以千分位的形式显示,四舍五入保留2位小数
select format(16466.65646, 2);
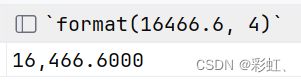
select format(16466.6, 4);
# 四舍五入取整
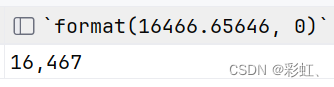
select format(16466.65646, 0);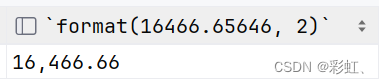
时间与日期
日期:年、月、日。 时间:时、分、秒。 %Y 四位的年份 %y 2位的年份 %m 月份(01,02,..11,12) %c 月份(1,2,3...11,12) %d 日(01,02,...) %H 小时(24小时) %h 小时(12小时) %i 分钟(00,01,...59) %s 秒(00,01,...59)
-
系统时间
select now(), curdate(), curtime();
-
获取日期和时间中的各个时间部分,参数均可以是字符串
select year(now()),
month(now()),
day(now()),
hour(now()),
minute(now()),
second(now());
-
weekofyear()
一年中的第几周,参数可以是字符串
select weekofyear(now());
select weekofyear('2024-01-11 11:22:31');
-
quarter()
第几季度,参数同样可以是字符串
select quarter(now());
-
str_to_date()
将时间字符串转换为标准的时间格式
select str_to_date('20240101', '%Y%m%d');
select str_to_date('2024,01,01', '%Y,%m,%d');
select str_to_date('2024/01/01', '%Y/%m/%d');
select str_to_date('2024_01_01', '%Y_%m_%d');执行返回的结果均是:

-
date_format():格式化日期时间
select date_format('2024/01/01', '%Y年%m月%d日');
select date_format('2024_01_01 15:22:31', '%Y年%m月%d日 %H时%i分%s秒');
# h为12小时制
select date_format('2024_01_01 15_22_31', '%Y-%m-%d %h:%i:%s'); ?
?

-
date_add(日期,interval num 时间单位)
时间往前偏移,num为负数时往前。date_sub则相反
# 最后一个参数为year就是偏移年,还有时、分、秒可选
select date_add(now(), interval -1 year);
select date_add(now(), interval 1 month);
select date_add(now(), interval 1 day);
select date_add(curdate(), interval 1 year);



-
last_day()
返回月末的日期,参数可以是时间、日期+时间
select last_day(now());
select last_day(curdate());返回结果均为date日期:
?
-
datediff()
返回两个时间相差天数
select datediff(now(), '2023-01-11 11:22:31');
select datediff(now(), '2023-01-11');
select datediff(curtime(), '2023-01-11');
select datediff(curtime(), '2023-01-11 11:22:31');
select datediff('2025-01-11 11:22:31', '2023-01-11 11:22:31');
select datediff('2025-01-11', '2023-01-11');
?




-
timestampdiff(unit,start_date,end_date)
返回两个时间差,单位可选年、月、日等
select timestampdiff(year, '2024-01-11 11:22:31', '2025-01-11 11:22:31');
# 计算岁数
select timestampdiff(year, '1999-09-09', curdate());
select timestampdiff(month, '2024-01-11 11:22:31', '2025-01-11 11:22:31');
select timestampdiff(day, '2024-01-11 11:22:31', '2025-01-11 11:22:31');
select timestampdiff(minute, '2024-01-11 11:22:31', '2025-01-11 11:22:31');
select timestampdiff(second, '2024-01-11 11:22:31', '2025-01-11 11:22:31');
搞集贸,截图太累了,不放了,自己实践去?(狗头)
-
多函数组合使用求时间
# 月初(方式一):2024-01-01
select concat(substr(now(), 1, 8), '01');
# 月初(方式二):2024-01-01
select date_add(curdate(), interval - day(curdate()) + 1 day);
# 本月天数,先取月末,再获取日:31
select day(last_day(curdate()));
# 年初:2024-01-01
select concat(year(curdate()), '-01-01');
# 上月末:2023-12-31
select last_day(date_add(curdate(), interval -1 month));聚合函数
后续用到的表和数据(方便练习,未严格按照数据库设计规范进行):
create table user
(
id int null,
user_name varchar(255) null,
user_sex varchar(255) null
);
INSERT INTO user (id, user_name, user_sex) VALUES (1, '张三', '男');
INSERT INTO user (id, user_name, user_sex) VALUES (2, '李四', '女');
INSERT INTO user (id, user_name, user_sex) VALUES (3, '王五', '男');
INSERT INTO user (id, user_name, user_sex) VALUES (4, '赵六', '男');create table stu_score
(
id int auto_increment
primary key,
name varchar(50) null,
subject varchar(50) null,
score int null,
stu_id int null
);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (2, '张三', '数学', 89, 1);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (3, '张三', '语文', 80, 1);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (4, '张三', '英语', 60, 1);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (5, '李四', '数学', 90, 2);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (6, '李四', '语文', 70, 2);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (7, '李四', '英语', 80, 2);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (8, '王五', '数学', 58, 3);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (9, '王五', '语文', 70, 3);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (10, '王五', '英语', 100, 3);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (11, '赵六', '数学', 88, 4);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (12, '赵六', '语文', 75, 4);
INSERT INTO stu_score (id, name, subject, score, stu_id) VALUES (13, '赵六', '英语', 48, 4);create table department_grade
(
id int auto_increment
primary key,
name varchar(100) null comment '部门名称',
year int null comment '年份',
label varchar(100) null comment '部门标识',
score double null comment '分数'
)
comment '部门评分表';
INSERT INTO department_grade (id, name, year, label, score) VALUES (14, '应用一部', 2023, '一', 81.22);
INSERT INTO department_grade (id, name, year, label, score) VALUES (15, '应用一部', 2023, '二', 82.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (16, '应用一部', 2023, '三', 75.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (17, '应用一部', 2023, '四', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (18, '销售一部', 2023, '一', 81.22);
INSERT INTO department_grade (id, name, year, label, score) VALUES (19, '销售一部', 2023, '二', 82.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (20, '销售一部', 2023, '三', 75.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (21, '销售一部', 2023, '四', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (22, '应用一部', 2024, '一', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (23, '应用一部', 2024, '二', 88.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (24, '应用一部', 2024, '三', 79.99);
INSERT INTO department_grade (id, name, year, label, score) VALUES (25, '应用一部', 2024, '四', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (26, '销售一部', 2024, '一', 79.99);
INSERT INTO department_grade (id, name, year, label, score) VALUES (27, '销售一部', 2024, '二', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (28, '销售一部', 2024, '三', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (29, '销售一部', 2024, '四', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (30, '应用二部', 2023, '一', 81.22);
INSERT INTO department_grade (id, name, year, label, score) VALUES (31, '应用二部', 2023, '二', 82.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (32, '应用二部', 2023, '三', 75.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (33, '应用二部', 2023, '四', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (34, '销售二部', 2023, '一', 81.22);
INSERT INTO department_grade (id, name, year, label, score) VALUES (35, '销售二部', 2023, '二', 82.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (36, '销售二部', 2023, '三', 75.36);
INSERT INTO department_grade (id, name, year, label, score) VALUES (37, '销售二部', 2023, '四', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (38, '应用二部', 2024, '一', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (39, '应用二部', 2024, '二', 88.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (40, '应用二部', 2024, '三', 79.99);
INSERT INTO department_grade (id, name, year, label, score) VALUES (41, '应用二部', 2024, '四', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (42, '销售二部', 2024, '一', 79.99);
INSERT INTO department_grade (id, name, year, label, score) VALUES (43, '销售二部', 2024, '二', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (44, '销售二部', 2024, '三', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (45, '销售二部', 2024, '四', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (46, '海外业务部', 2023, '一', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (47, '海外业务部', 2023, '二', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (48, '海外业务部', 2023, '三', 88.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (49, '海外业务部', 2023, '四', 79.99);
INSERT INTO department_grade (id, name, year, label, score) VALUES (50, '海外业务部', 2024, '一', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (51, '海外业务部', 2024, '二', 79.99);
INSERT INTO department_grade (id, name, year, label, score) VALUES (52, '海外业务部', 2024, '三', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (53, '海外业务部', 2024, '四', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (54, '研究院', 2023, '一', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (55, '研究院', 2023, '二', 79.99);
INSERT INTO department_grade (id, name, year, label, score) VALUES (56, '研究院', 2023, '三', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (57, '研究院', 2023, '四', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (58, '研究院', 2024, '一', 82.45);
INSERT INTO department_grade (id, name, year, label, score) VALUES (59, '研究院', 2024, '二', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (60, '研究院', 2024, '三', 91.55);
INSERT INTO department_grade (id, name, year, label, score) VALUES (61, '研究院', 2024, '四', 88.55);-
sum():求和
# 查询成绩表中每个同学所有科目的总分
select name,
sum(score)
from stu_score
group by name;?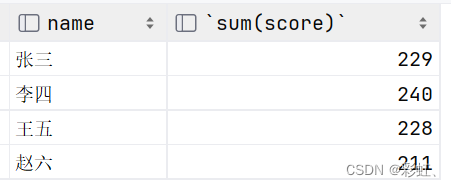
-
max()最大值,min()最小值,avg()平均值
# 求各科最大分数、最小分数、平均分
select subject,
max(score),
min(score),
avg(score)
from stu_score
group by subject;
流程控制
-
if(expr,v1,v2)
如果expr条件成立,返回v1,否则返回v2
select u.user_name,
user_sex,
s.subject,
s.score,
if(s.score < 60, '不及格', '及格') as '是否及格'
from stu_score s
left join user u on s.stu_id = u.id;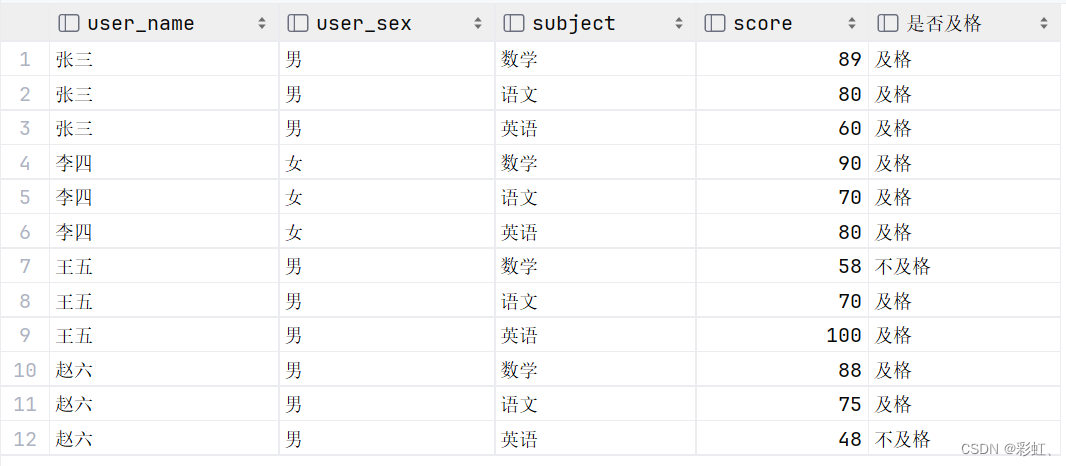
-
ifnull(expr1,expr2)
如果expr1为null则返回expr2
select ifnull('hello', '你好'), ifnull(null, 'hello');
-
case ... when
用法一: case 要判断的字段或表达式 when 常量1 then 要显示的值1或语句1 when 常量2 then 要显示的值2或语句2 ... else 要显示的值n或语句n end |
select u.user_name,
user_sex,
s.subject,
s.score,
case s.score
when 90 then '优秀线'
when 60 then '及格线'
else ''
end as '界限'
from stu_score s
left join user u on s.stu_id = u.id;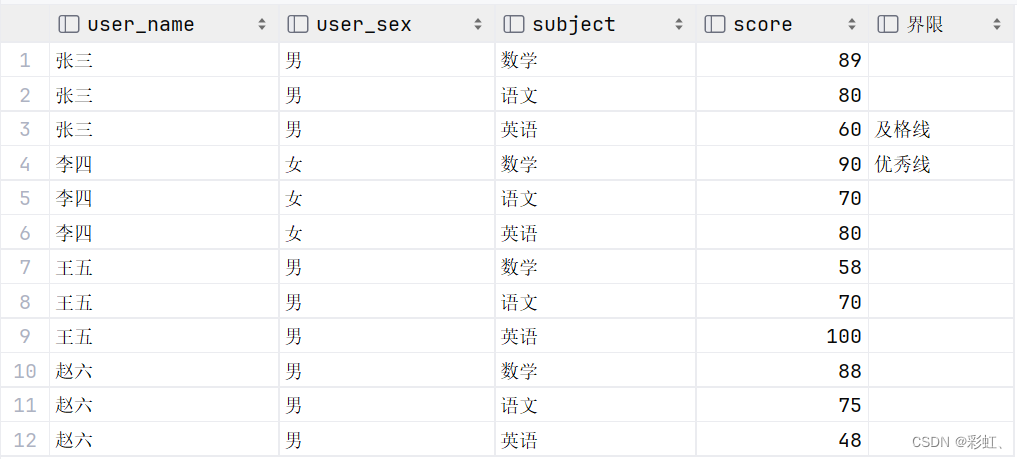
用法二: case when 条件1 then 要显示的值1或语句1 when 条件2 then 要显示的值2或语句2 ... else 要显示的值n或语句n end |
# 注意case后面无字段
select u.user_name,
user_sex,
s.subject,
s.score,
case
when s.score >= 90 then '优秀'
when s.score >= 70 then '良好'
when s.score >= 60 then '及格'
else '不及格'
end as '分数等级'
from stu_score s
left join user u on s.stu_id = u.id;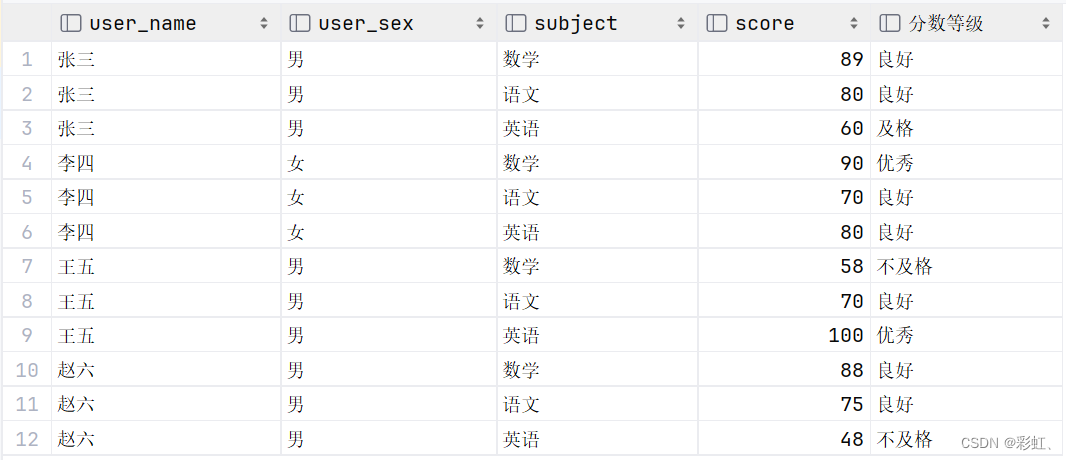
和聚合函数联合使用?
select subject,
max(score) as '最高分',
min(score) as '最低分',
avg(score) as '平均分',
sum(case when score >= 90 then 1 else 0 end) / count(*) as '优秀率',
sum(case when score >= 70 then 1 else 0 end) / count(*) as '良好率',
sum(case when score >= 60 then 1 else 0 end) / count(*) as '及格率'
from stu_score
group by subject;
?把 case when 替换成 if 同样可以达到一样的效果:
select subject,
max(score) as '最高分',
min(score) as '最低分',
avg(score) as '平均分',
sum(if(score >= 90, 1, 0)) / count(*) as '优秀率',
sum(if(score >= 70, 1, 0)) / count(*) as '良好率',
sum(if(score >= 60, 1, 0)) / count(*) as '及格率'
from stu_score
group by subject;
系统相关
# 查看MySQL系统版本号
select version();
# 当前用户的连接id
select connection_id();
# 查看用户的连接信息
show processlist;
# 查看当前使用的数据库
select database(), schema();
# 查看当前用户
select user(), current_user(), system_user();
# 查看当前数据库字符集
show variables like 'character_set%';
# 查看当前连接用户的字符集
select charset(user());
# 查看当前连接用户的字符串排列方式
select collation(user());
# md5加密字符串
select md5('111111');其他好东西
-
查看执行SQL的次数、第一次执行时间、最后一次执行时间
select DIGEST_TEXT,
COUNT_STAR,
FIRST_SEEN,
LAST_SEEN
from performance_schema.events_statements_summary_by_digest
order by COUNT_STAR desc;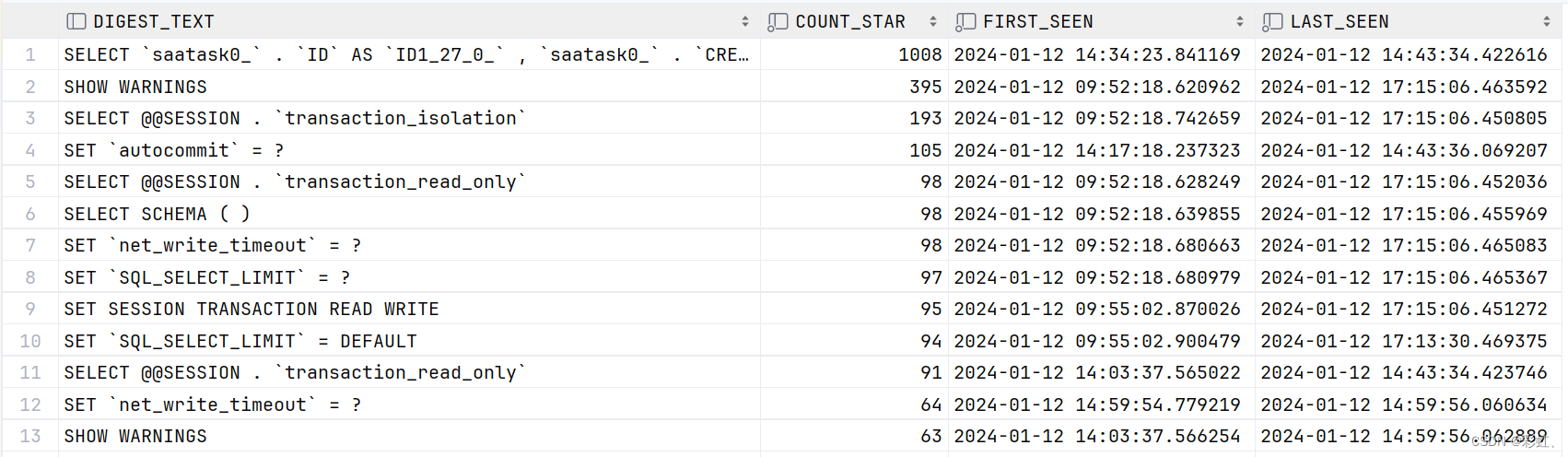
-
通过存储过程造数据
# 1.INSERT_DATA_TO_STU为存储过程名称,如果存在就删除
DROP PROCEDURE
IF EXISTS INSERT_DATA_TO_STU;
# 2.创建存储过程
CREATE PROCEDURE INSERT_DATA_TO_STU()
BEGIN
DECLARE n INT DEFAULT 1;
# 执行1000次插入语句
WHILE (n <= 1000)
DO
insert into 表名(字段1, 字段2...)
values (值1, 值2...);
SET n = n + 1;
END WHILE;
END;
# 3.调用存储过程
CALL INSERT_DATA_TO_STU();-
自定义排序
按照特定的部门顺序,再按年份倒序,指定季度顺序(直接季度倒序有问题,我也不知道为什么....)
# 方式一:field函数
select *
from department_grade
order by field(name, '应用一部', '应用二部', '销售一部', '销售二部', '研究院', '海外业务部'),
year desc,
field(label, '四', '三', '二', '一');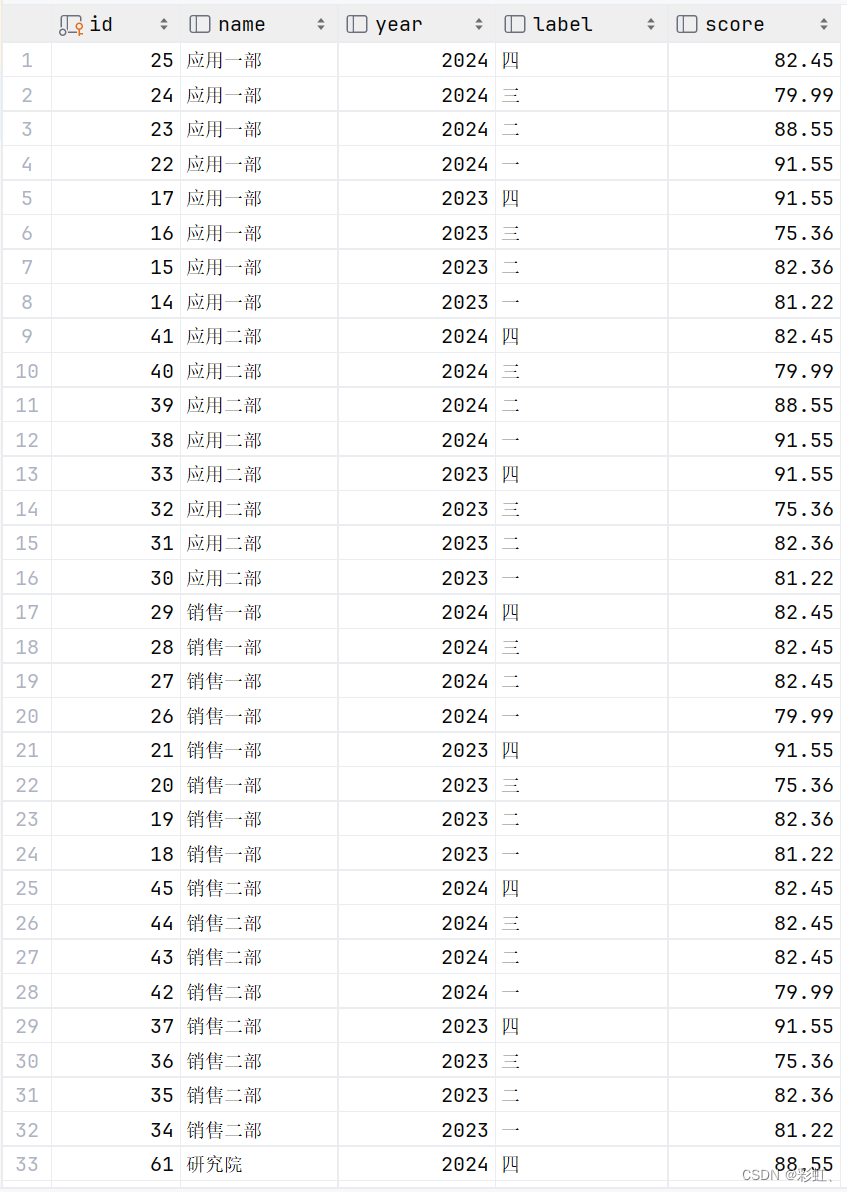
# 方式二:locate函数
select *
from department_grade
order by locate(name, '应用一部,应用二部, 销售一部, 销售二部, 研究院, 海外业务部'),
year desc,
locate(label, '四, 三, 二, 一');
# 方式三:instr函数
select *
from department_grade
order by instr('应用一部,应用二部, 销售一部, 销售二部, 研究院, 海外业务部', name),
year desc,
instr('四, 三, 二, 一', label);
# 这两个和方式一效果一样-
导出数据(csv形式,也可txt)
# 导出前先执行以下命令,查看require_secure_transport和secure_file_priv
show variables like '%secure%';
# 'into outfile'后面的路径只能是secure_file_priv对应的value,这个值可以更改,自行查找方法
select *
from stu_score
where subject = '语文'
# 导出的文件路径
into outfile 'D:\\Java\\GongJu\\MySql\\data\\Uploads\\test.csv'
# 未设置字符集时,导出的csv文件wps打开不乱码,用微软Excel打开会乱码,设置成gbk就没事
character
set gbk
# 逗号分割字段
fields terminated by ','
# 字段值的括起字符(双引号)
enclosed by '"'
# 换行
lines terminated by '\n';-
一个窗口函数(一些特殊业务场景非常好用)
row_number() over (partition by 列1,列2 order by 排序列) as rn
# 取每个部门、每年、第四季度的评分记录
select T.*
from (select name,
year,
score,
# rn为新的计数列,从1开始,给每条记录打一个序号
row_number() over (
# 按照部门名称、年份分区
partition by name,year
# 季度倒序
order by label desc
) as rn
from department_grade) as T
# 因为按季度倒序,所以rn为1的就是第四季度的,好像也不完全是按照四、三、二、一倒序打标记,但这里的rn为1的确实是第四季度的,嗯....我也不知道为什么....
where rn = 1;?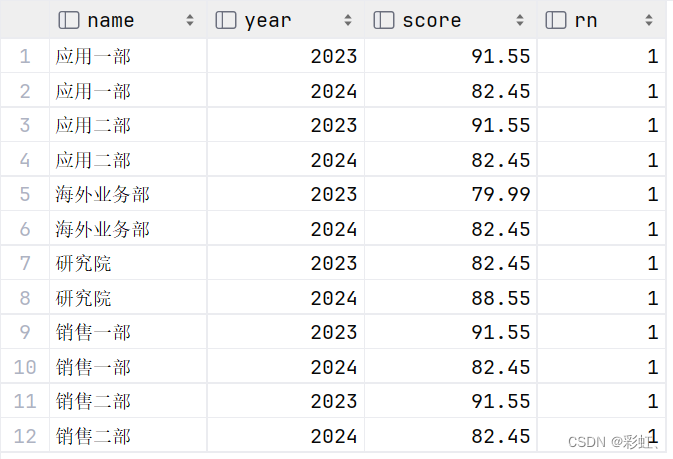
这是我之前的小组长教的,那时候还云里雾里的,后面分析了一波才清楚,一些场景下香得一批,注意这是8.0以上版本才有的,还用5点几的?原始人?
可能是旧项目? ?
?
本文是阅读了下面这位博主的文章后添加了一些自己的内容整理出来的,感谢大佬的分享。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- m3u8网络视频文件下载方法
- 【Python】Python AI 绘画
- 修改jenkins的目录(JENKINS_HOME)
- Python PDF转DOCX文档
- 关于低代码开发的一些看法
- AI全栈大模型工程师(二十)SKvs.LangChain
- Spring之IOC
- CentOS 8 上安装 Python 3.10.12
- WPS/Word插件-大珩助手免费功能更新-特殊字符
- 【精简】 Java递归获得指定包下全部类的全类名