用Python创建轻量级Excel到Markdown转换工具:简便、高效、自动化【第28篇—python:Excel到Markdown】
文章目录
用 Python 创建 Excel 转 Markdown 的 CLI 工具
在工作中,我们常常需要将 Excel 表格转换为 Markdown 格式,以便在文档、博客或其他支持 Markdown 的平台上分享。然而,一些 Markdown 编辑器对从 Excel 复制粘贴的内容支持并不理想,导致转换后的格式混乱。另外,如果需要频繁处理相同类型的文件,手动转换显得繁琐。因此,我决定创建一个 CLI 工具,用于自动化这一转换过程。
设计思路
为了确保工具的易用性和便携性,我决定使用 Python 编写这个 CLI 工具。由于我希望同事们也能方便地使用这个工具,我决定尽量减少对第三方库的依赖,使得工具更易于部署。
Excel 文件结构解析
在着手编写代码之前,我们需要了解 Excel 文件的结构。经过简单的研究,我们发现 Excel 文件实际上是一个 ZIP 压缩包,其中包含一系列 XML 文件。具体而言,我们主要关注 sharedStrings.xml 和 sheet1.xml 两个文件。前者包含表格中的字符串,后者包含表格的实际数据。
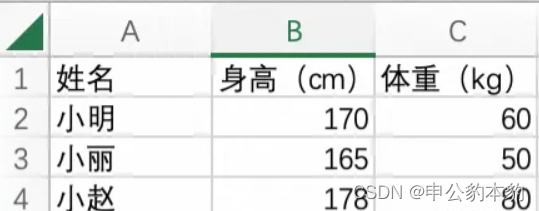
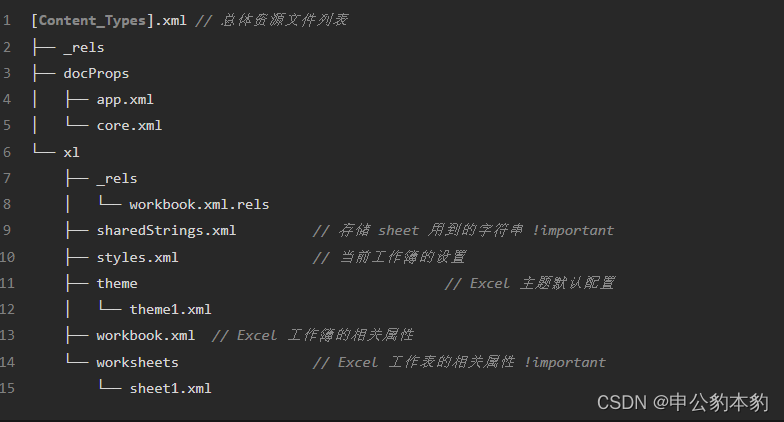
读取 Excel 文件
首先,我们需要解压 Excel 文件。Python 的标准库中提供了 zipfile 模块,可以方便地进行文件解压。解压后,我们可以读取 sharedStrings.xml 文件,将其中的共享字符串保存为数组,以便后续引用。
import xml.dom.minidom
import zipfile
import os
import shutil
output_path = 'data' # 解压 Excel 后的临时文件夹名称
file_path = input("请输入 Excel 文件路径:")
md_path = file_path.split('.')[0] + ".md" # 输出的 Markdown 文件名
# 解压 Excel 文件
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(output_path)
strings = []
# 读取共享字符串
shared_strings_path = os.path.join(output_path, "xl/sharedStrings.xml")
if os.path.exists(shared_strings_path):
with open(shared_strings_path, 'r') as data:
# 将 XML 文件转化为 DOM 结构
dom = xml.dom.minidom.parse(data)
# 找到所有 t 标签
for string in dom.getElementsByTagName('t'):
# 将 t 标签中的字符串值加到 strings 数组中
strings.append(string.childNodes[0].nodeValue)
# 其他代码...
解析表格数据
接下来,我们解析 sheet1.xml 文件,将表格数据保存为一个二维数组。注意,我们需要处理单元格中可能包含的字符串索引。
result = []
# 读取表格数据
sheet_path = os.path.join(output_path, "xl/worksheets/sheet1.xml")
if os.path.exists(sheet_path):
with open(sheet_path, 'r') as data:
dom = xml.dom.minidom.parse(data)
# 遍历每一个 row 标签
for row in dom.getElementsByTagName('row'):
row_data = []
# 遍历 row 标签中包含的每个 c 标签
for cell in row.getElementsByTagName('c'):
value = ''
# 如果该 c 标签的 t 属性值为 s,说明是字符串,需要到 strings 中获取其真实值
if cell.getAttribute('t') == 's':
shared_string_index = int(cell.getElementsByTagName('v')[0].childNodes[0].nodeValue)
value = strings[shared_string_index]
# 否则直接读取其值
else:
value = cell.getElementsByTagName('v')[0].childNodes[0].nodeValue
# 将这一格的数据添加到 row_data 中
row_data.append(value)
# 将这一行的数据添加到 result 中
result.append(row_data)
# 其他代码...
生成 Markdown 表格
最后,我们将表格数据转换为 Markdown 格式,并保存到 Markdown 文件中。
# 构建 Markdown 表格
# 生成第一行
markdown_table = "|"
markdown_table += "|".join(result[0]) + "|"
markdown_table += "\n"
# 生成分隔行(第二行)
markdown_table += "|"
markdown_table += "|".join(["-" for _ in result[0]]) + "|"
markdown_table += "\n"
# 生成后续的行
for row in result[1:]:
markdown_table += "|"
markdown_table += "|".join([value for value in row]) + "|"
markdown_table += "\n"
# 去除多余的换行符
markdown_table = markdown_table[:-1]
# 生成 Markdown 文件
with open(md_path, 'w') as md_file:
md_file.write(markdown_table)
# 其他代码...
完整代码
最终的完整代码如下:
import xml.dom.minidom
import zipfile
import os
import shutil
output_path = 'data' # 解压 Excel 后的临时文件夹名称
file_path = input("请输入 Excel 文件路径:")
md_path = file_path.split('.')[0] + ".md" # 输出的 Markdown 文件名
# 解压 Excel 文件
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(output_path)
strings = []
# 读取共享字符串
shared_strings_path = os.path.join(output_path, "xl/sharedStrings.xml")
if os.path.exists(shared_strings_path):
with open(shared_strings_path, 'r') as data:
# 将 XML 文件转化为 DOM 结构
dom = xml.dom.minidom.parse(data)
# 找到所有 t 标签
for string in dom.getElementsByTagName('t'):
# 将 t 标签中的字符串值加到 strings 数组中
strings.append(string.childNodes[0].nodeValue)
result = []
# 读取表格数据
sheet_path = os.path.join(output_path, "xl/worksheets/sheet1.xml")
if os.path.exists(sheet_path):
with open(sheet_path, 'r') as data:
dom = xml.dom.minidom.parse(data)
# 遍历每一个 row 标签
for row
in dom.getElementsByTagName('row'):
row_data = []
# 遍历 row 标签中包含的每个 c 标签
for cell in row.getElementsByTagName('c'):
value = ''
# 如果该 c 标签的 t 属性值为 s,说明是字符串,需要到 strings 中获取其真实值
if cell.getAttribute('t') == 's':
shared_string_index = int(cell.getElementsByTagName('v')[0].childNodes[0].nodeValue)
value = strings[shared_string_index]
# 否则直接读取其值
else:
value = cell.getElementsByTagName('v')[0].childNodes[0].nodeValue
# 将这一格的数据添加到 row_data 中
row_data.append(value)
# 将这一行的数据添加到 result 中
result.append(row_data)
# 删除临时文件夹
shutil.rmtree(output_path)
# 构建 Markdown 表格
# 生成第一行
markdown_table = "|"
markdown_table += "|".join(result[0]) + "|"
markdown_table += "\n"
# 生成分隔行(第二行)
markdown_table += "|"
markdown_table += "|".join(["-" for _ in result[0]]) + "|"
markdown_table += "\n"
# 生成后续的行
for row in result[1:]:
markdown_table += "|"
markdown_table += "|".join([value for value in row]) + "|"
markdown_table += "\n"
# 去除多余的换行符
markdown_table = markdown_table[:-1]
# 生成 Markdown 文件
with open(md_path, 'w') as md_file:
md_file.write(markdown_table)
当你运行这个 Python 脚本时,它会提示你输入 Excel 文件的路径,然后它将在同一目录下生成一个相应的 Markdown 文件。
接下来,我们可以进一步改进这个 CLI 工具,增加一些功能,例如:
1. 参数化文件路径:
将文件路径作为脚本的参数传递,而不是在运行时手动输入。
import sys
if len(sys.argv) < 2:
print("请提供 Excel 文件路径作为参数")
sys.exit(1)
file_path = sys.argv[1]
然后你可以通过命令行运行脚本:
python excel_to_markdown.py path/to/your/excel/file.xlsx
2. 处理不同的工作表:
当前脚本仅处理第一个工作表(sheet1.xml)。你可以扩展脚本以允许用户选择或处理所有工作表。
3. 改进 Markdown 表格生成:
目前的 Markdown 表格生成方法非常基础。你可以考虑使用更先进的库,如 tabulate 或 pandas,以提高表格生成的灵活性和美观性。
4. 错误处理:
添加更多的错误处理,以确保在解析文件时能够容错并给出有用的错误信息。
5. 打包为可执行文件:
你可以使用诸如 PyInstaller、cx_Freeze 或 py2exe 等工具,将脚本打包为可执行文件,使得用户无需安装 Python 解释器即可运行。
6. 增加日志:
在脚本中添加日志功能,以记录程序运行的关键步骤,便于调试和追踪问题。
7. 进一步优化性能:
如果处理大型 Excel 文件时性能成为问题,可以考虑优化代码以更有效地处理数据。
以上是一些可以考虑的改进和扩展点,具体取决于你的需求和使用场景。希望这个简单的工具对你有帮助,如果有任何问题或进一步的需求,请随时提出。
总结
通过这个简单的 Python CLI 工具,我们可以方便地将 Excel 文件转换为 Markdown 格式。该工具减少了对第三方库的依赖,使得代码更加轻量、易读。你可以根据需要扩展该工具,添加更多功能,以适应不同的使用场景。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!