for循环展开浅析
改几行代码,for循环耗时从3.2秒降到0.3秒!真正看懂的都是牛人!
测试程序
测试程序test.c非常简单,计算1000000000的阶乘:

为方便分析,函数calc()前面加上__attribute__((noinline)),禁止GCC把calc内联在main()中。此外,calc()中,fact类型是int,main()中调用calc(1000000000),会导致fact溢出,但不影响测试,不用管它。
编译一下,然后用time命令测量下运行耗时:

然后,把程序稍微改一下,命名为test_2.c:
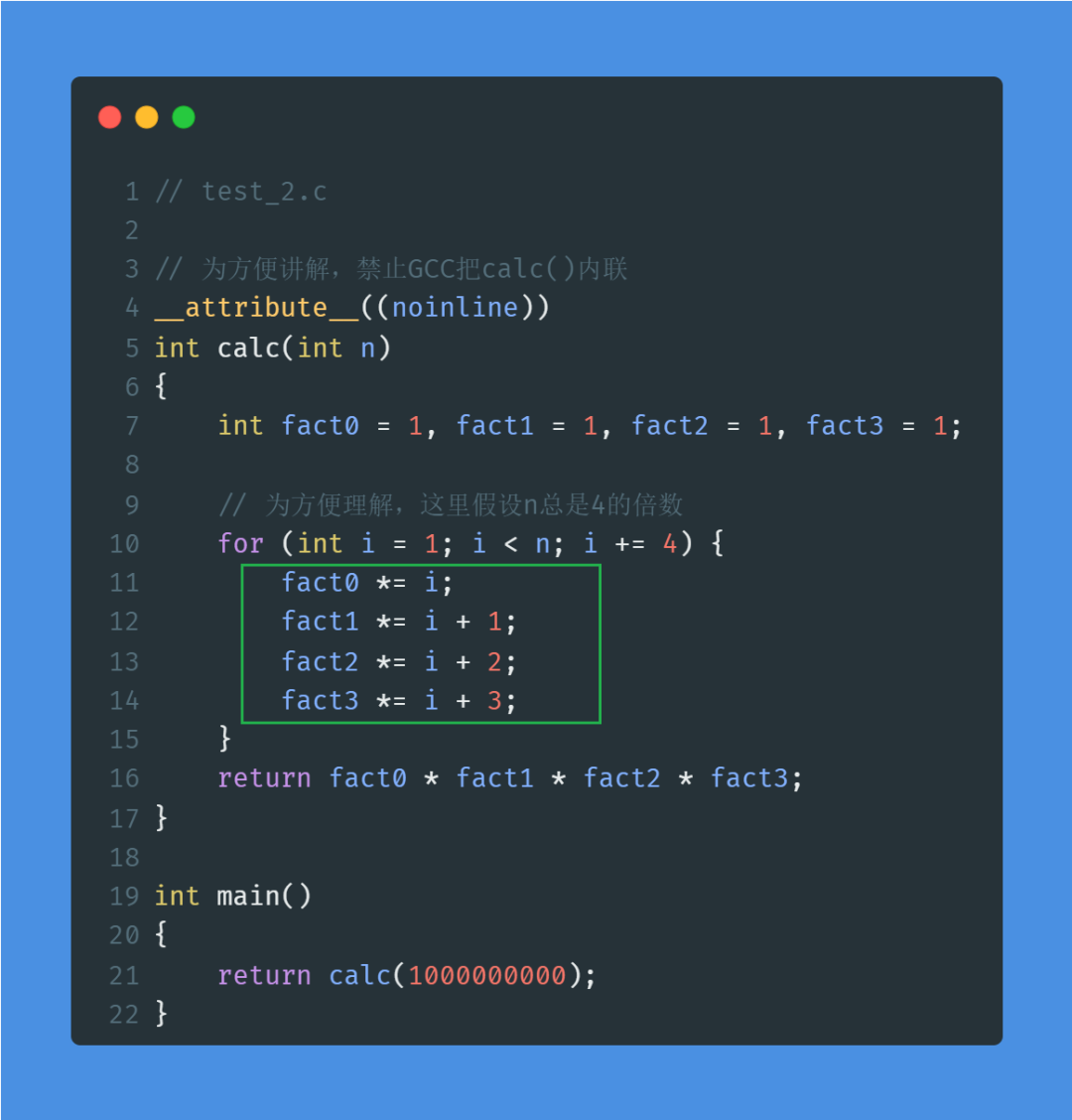
注意:这里为方便讲解,假设n总是4的倍数。如果要处理n不是4的倍数的情况,只需要在主循环体外,增加一个小的循环单独处理最后的n%4个数,也就是最多3个数即可,对整体性能影响几乎为0.
编译,并用time命令测量下运行耗时:
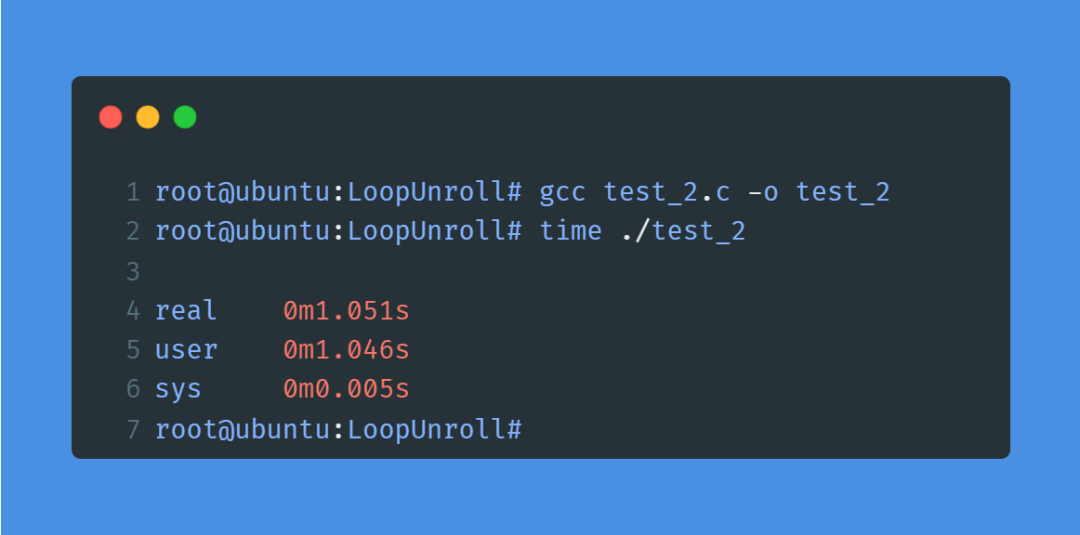
运行耗时从原来的3.29秒降到了1秒,性能提升了200%!你以为这就完了?
这还不是最终的结果,因为我们还有一个优化技巧还没加上,最终优化后的结果是0.3秒!文末会讲!先不着急,咱们一个一个来讲!
关于循环展开:你真的理解吗?
看到这里,有人会说,不就是循环展开嘛,很简单的,没什么好研究的,而且加了优化选项之后,编译器会自动进行循环展开的,没必要手动去展开,也就没有研究的价值了!
真的是这样吗?先尝试回答下面几个问题:
-
1. 循环展开为什么能提高程序性能,其背后的深层次原理是什么?
-
2. 循环随便怎么展开都一定可以提高性能吗?
-
3. 用了优化选项,编译器一定会帮我们自动进行循环展开优化吗?
第一个问题后面会详细讲解,我们先用实例回答下第2个和第3个问题。
先看第2个问题。
循环随便展开都能提高性能吗?
我们把test_2.c稍微改一下,命令为test_3.c:

仍然是循环展开,只不过把循环展开的方式稍微改了一下。再编译一下,用time命令测量下运行耗时:
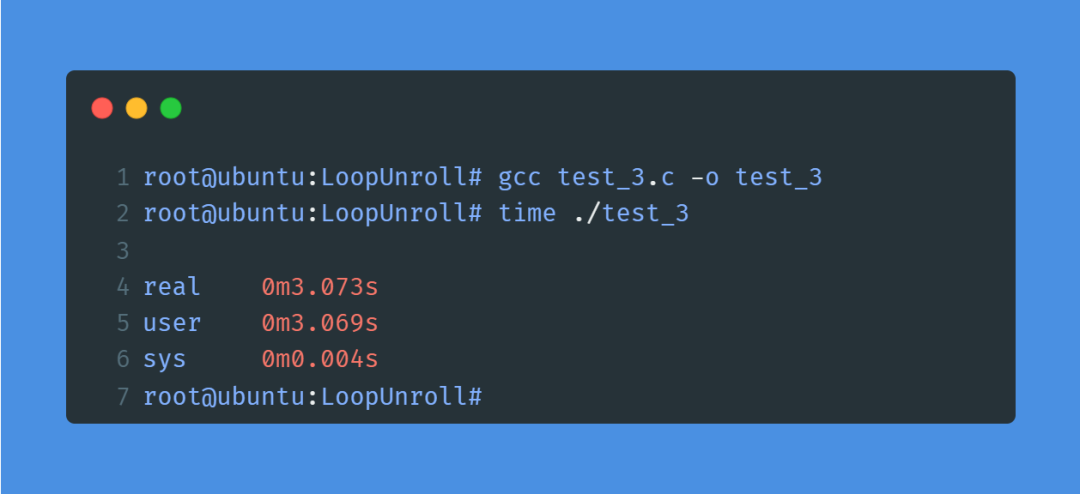
和test.c相比运行耗时只减少了0.2秒!为什么同样是循环展开,test_2.c只需要1.6秒,而test_3.c却要3秒,为什么性能差异这么大呢?别着急,后面细讲。
再看第三个问题,加了优化选项,编译器一定会帮我们自动进行循环展开优化吗?一试便知!
-O3,编译器一定会循环展开吗?
重新编译下test.c, test_2.c, 和test_3.c,只不过,这次我们加上-O3优化选项,然后分别用time命令再测量下运行时间。
先是test.c:

加了-O3优化后,程序耗时从原来的3.29秒降到了1.07秒,性能提升确实非常明显!是否好奇,-O3选项对test.c做了什么样的优化,能够把程序耗时降到三分之一?这个后面再讲。
现在,我们先试下test_2.c:
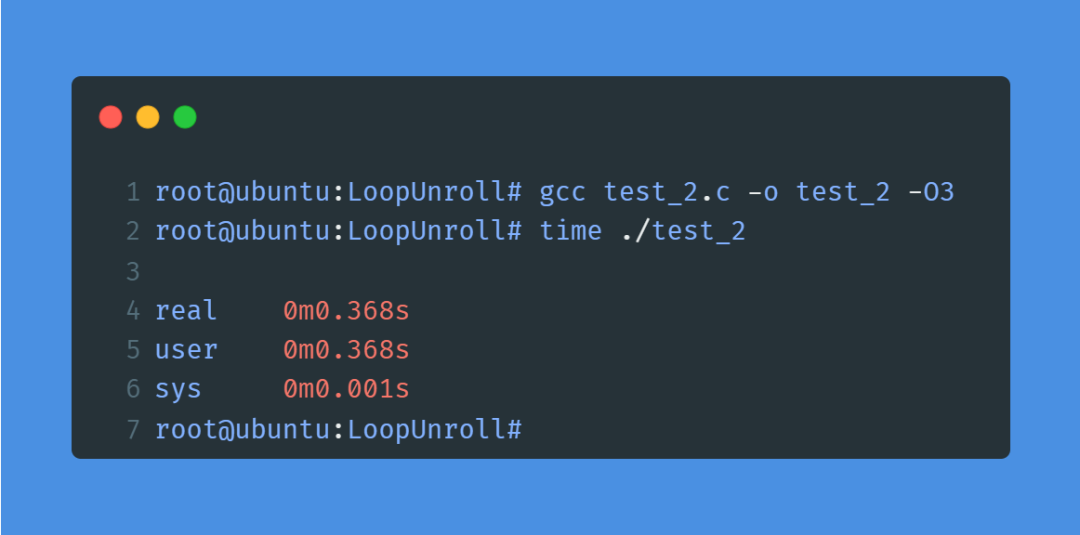
同样,加了-O3后,程序耗时从原来的1秒降到了0.368秒!此外,在同样加了-O3的情况下,使用了循环展开的test_2.c,程序耗时仍然是test.c的三分之一!可见,编译器确实优化了一些东西,但是,无论是否加-O3优化选项,进行手动循环展开的test.c仍然是性能最好的!
最后,再试下test_3.c:

看到了吧?同样加了-O3优化选项的前提下,性能仍然与test_2.c相差甚远!
小结一下我们现在得到的几组测试结果:

在解释这些性能差异的原因之前,必须要先补充一些CPU相关的基础知识,否则无法真正理解这背后的原因!所以,请务必认真看完!
这会涉及到CPU内部实现细节的知识,相对比较底层,而且对绝大多数程序员是透明的,因此很多人甚至都没听说过这些概念。不过,也不用担心,跟之前一样,我会尽量用通俗易懂的语言来解释这些概念。
test1.c
__attribute__((noinline)) int calc(int n) {
int fact = 1;
for (int i = 1; i < n; i++) {
fact *= i;
}
return fact;
}
int main() { return calc(1000000000); }test2.c
__attribute__((noinline)) int calc(int n) {
int fact0 = 1,fact1=1,fact2=1,fact3=1;
for (int i = 1; i < n; i += 4) {
fact0 *= i;
fact1 *= i + 1;
fact2 *= i + 2;
fact3 *= i + 3;
}
return fact0*fact1*fact2*fact3;
}
int main() { return calc(1000000000); }test3.c
__attribute__((noinline)) int calc(int n) {
int fact;
for (int i = 1; i < n; i += 4) {
fact *= i;
fact *= i + 1;
fact *= i + 2;
fact *= i + 3;
}
return fact;
}
int main() { return calc(1000000000); }背景知识:CPU内部架构
指令流水线(pipeline)
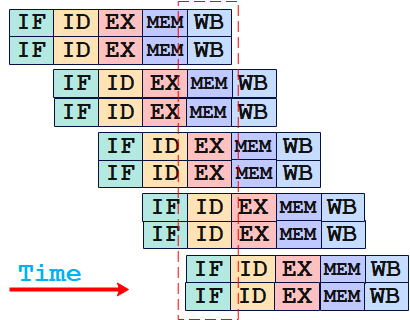
所谓流水线,是把指令的执行过程分成多个阶段,每个阶段使用CPU内部不同的硬件资源来完成。以经典的5级流水线为例,一条指令的执行被分为5个阶段:
-
??取指(IF):从内存中取出一条指令。
-
??译码(ID):对指令进行解码,确定该指令要执行的操作。
-
??执行(EX):执行该指令要执行的操作。
-
??访存(MEM):进行内存访问操作。
-
??写回(WB):把执行的结果写回寄存器或内存。
在时钟信号的驱动下,CPU依次来执行这些步骤,这就构成了指令流水线(pipeline)。如下图所示:

在CPU内部,执行每个阶段使用不同的硬件资源,从而可以让多条指令的执行时间相互重叠。当第一条指令完成取指,进入译码阶段时,第二条指令就可以进入取指阶段了。以此类推,在一个5级流水线中,理想情况下,可以有5条不同的指令的不同阶段在同时执行,因此每个时钟周期都会有一条指令完成执行,从而大大提高了CPU执行指令的吞吐率,从而提高CPU整体性能。这就叫做ILP - 指令级并行(Instruction Level Parallelism)。如下图所示:

通过把指令执行分为多个阶段,CPU每个时钟周期只处理一个阶段的工作,这样大大简化了CPU内部负责每个阶段的功能单元,每个时钟周期要做的事情少了,提高时钟频率也变得简单了。
前面说过,有了流水线技术,理想情况下,每个时钟周期,CPU可以完成一条指令的执行。那有没有什么方法,可以让CPU在每个时钟周期,完成多条指令的执行呢,这岂不是会大大提高CPU整体性能吗?
当然有!这就是Superscalar技术!(除此之外还有VLIW,不是本文重点,不再展开讨论。)
超标量(Superscalar)
Superscalar,通过在CPU内部实现多条指令流水线,可以真正实现多条命令并行执行,也被称为多发射数据通路技术。以双发射流水线为例,每个时钟周期,CPU可以同时读取两条指令,然后同时对这两条指令进行译码,同时执行,然后同时写回。如下图所示:
目前为止,这一切看起来都很完美,对吧?然而,现实往往没有理想那么丰满!接着往下看吧。
流水线冲突
大家可能注意到了,前面多次强调过,“在理想状态下”,为什么呢?
现实中程序的指令序列之间往往存在各种各样的依赖和相关性,而CPU为了解决这种指令间的依赖和相关性,有时候不得不“停顿”下来,直到这些依赖得到解决,这就导致CPU指令流水线无法总是保持“全速运行”。
这种现象被称之为Pipeline Hazard,很多资料翻译为“流水线冒险”,我觉得“流水线冲突”更为贴切易懂。
归结起来,有三种情况:
-
??数据冲突(Data Hazard)
-
??控制冲突(Control Hazard)
-
??结构冲突(Structure Hazard)
下面分别举例解释这三种类型的冲突。
数据冲突
所谓数据冲突,简单讲,就是两条在流水线中并行执行的指令,第二条指令需要用到第一条指令的执行结果,因此第二条指令的执行不得不暂停,一直到可以获取到第一条指令的执行结果为止。
比如,用伪代码举例:
x?=?1;
y?=?x;要对y进行赋值,必须要先得到x的值,因此这两条语句无法完全并行执行。
这只是其中的一种典型情况,其他情况不再赘述。
控制冲突
所谓控制冲突,简单讲,就是在CPU在执行分支跳转时,无法预知下一条要执行的指令。
比如:
if(a?>?100)?{
????x?=?1;
}?else?{
????y?=?2;
}在CPU计算出a > 100这个条件是否成立之前,无法确定接下来是应该执行x = 1 还是执行 y = 2。
为了解决这个问题,CPU可以简单的让流水线停顿一直到确定下一条要执行的指令,也可以采取如分支预测(branch prediction)和推测执行(speculation execution)等手段,但是,预测失败的话,流水线往往会受到比较严重的性能惩罚。之后会有专门的文章分析这个问题,感兴趣的话,可以右上角关注一下!
结构冲突
结构冲突,简单来说,就是多条指令同时竞争同一个硬件资源,由于硬件资源短缺,无法同时满足所有指令的执行请求。如两条并行执行的命令需要同时访问内存,而内存地址译码单元可能只有一个,这就产生了结构冲突。
有了上面这些基础知识做铺垫,接下来就可以开始真正分析这个问题了。
test.c为什么性能最差?
对于计算阶乘,test.c可能是最简单直观、可读性最强的算法。不过可惜的是,它也是性能最差的。
我们再看一下test.c的源码:
说它性能最差,主要有三点原因:
1. 热点路径无用指令太多。
2. 热点路径跳转指令太多。
3. 热点路径内存访问太多。
注意,这里说的无用指令,是指对计算阶乘本身不产生直接影响的指令,但是它们对整个算法的正确性仍然是必不可少的!
为例方便理解,我们来分别看下test.c不加优化选项和加了-O3编译之后的汇编代码。
test.c不加优化选项时
先是不加优化选项的:

绿色方框标注出来的8 ~ 14行是for循环,也就是主循环体。其中,蓝色方框标注出来的8 ~ 11行是真正计算阶乘的代码,12 ~ 14行是循环控制代码,对计算阶乘来说,则是无用代码。
不难看出:
-
1. 热点路径上,也就是循环体内无用指令占比是3/7 = 42%!即便在不考虑其他因素的情况下,CPU单单用来执行这些无用的指令,也是一笔不小的开销!
-
2. 整个阶乘计算过程中,循环体内需要执行1000000000次条件跳转指令!条件跳转又会造成控制冲突,使得流水线无法全速运行,从而造成巨大的性能损失。
-
3. 整个函数一共有10个内存访问操作,而循环体内就有6个内存操作!尽管很多时候可以通过Cache来缓解,但相对于CPU计算速度来说,内存操作仍然是非常慢的,而且容易造成流水线冲突!
那加了-O3优化选项之后,编译器能不能帮我们解决这些问题呢?
test.c加了-O3优化选项后
现在我们看下加了-O3之后的汇编代码:

首先,不得不感叹,现在的编译器的优化真的是太强大了!直接把整个for循环优化成了4条指令!
不难看出,对于test.c而言,加了-O3之后,GCC做的最大的优化是把所有变量存放在寄存器中,消除了所有的内存访问操作!
可以回过头去看下优化之前的汇编代码,整个函数一共有10个内存访问操作,其中6个是在循环体内,而加了-O3之后,整个函数没有任何内存访问操作!难怪-O3编译后性能提升那么多!由此可见,内存访问相对寄存器访问的开销实在是太大了!当然,即便不使用-O3,也有优化内存操作的办法,这个后面再讲。
但是,也不难看出,对于其他两个问题,GCC并没有帮我们解决:现在无用指令占比是 2/4 = 50%! 整个阶乘计算过程,仍然需要执行1000000000次条件跳转指令,仍然无法充分发挥流水线和superscalar的指令并行执行能力!
知道了test.c性能差的原因之后,现在我们来看看,通过手动循环展开,test_2.c又帮我们解决什么问题呢?
test_2.c性能提升原因
再看下test_2.c的源码:
通过对循环进行4次展开,之前每次循环执行1次乘法,现在每次循环执行4次,这就带来了三点很重要的变化:
-
1. 循环次数减少75%,无用指令减少了,相应的CPU执行这些指令本身的开销也少了。
-
2. 计算过程中,热点路径的条件跳转指令少了75%,这样就减少了由于控制相关引起的流水线冲突,提升了流水线执行的效率。
-
3. 提升了指令的并行度,使得CPU superscalar的技术得到更充分的发挥,提高了每个时钟周期并行执行指令的条数。
这也就是为什么在使用同样的编译选项时,test_2.c比test.c的性能提升了200%!不过,热点路径上内存访问操作太多的问题仍然存在。其实,这个其实很好解决,我会在下文给出解决方法。我们先把注意力放在这里所说的三点变化上。
对于第1点和第2点,有了前面介绍的指令流水线的背景知识,即便从C语言的角度也很好理解,不需要过多解释。
至于第3点,为了便于理解,我们和test_3.c对比来看。
test_3.c性能差的原因
再看下test_3.c的代码:
test_3.c虽然也把循环进行了4次展开,但是展开的方式和test_2.c是不一样的。
test_2.c是这样展开的:
fact0?*=?i;
fact1?*=?i?+?1;
fact2?*=?i?+?2;
fact3?*=?i?+?3;而test_3.c则是这样做的:
fact?*=?i;
fact?*=?i?+?1;
fact?*=?i?+?2;
fact?*=?i?+?3;很明显,后面一条指令执行前,必须要先知道前面一条语句计算的结果。还记得前面讲过的造成流水线冲突的三个原因吗?这就是典型的数据依赖,会造成流水线冲突!
可见,虽然test_3.c也通过循环展开,减少了无用指令,也减少了热点路径上分支跳转引起的流水线控制冲突,但它同时引入了数据依赖,进而导致流水线冲突,仍然无法发挥流水线和superscalar的指令级并行执行的能力!
这就是为什么,用同样的选项编译时,test_3.c虽然比未经过循环展开的test.c性能稍微提升了一点点,但相比同样循环展开且没有引入数据相关性的test_2.c来说,性能仍然是非常差的!
讲到这里,本想演示下用perf测量出来的性能指标的,但由于篇幅过长,就不再展开讨论了,以后会专门更新文章介绍perf相关工具的使用!
最后,来看一下前面遗留的那个问题:不加优化选项的情况下,怎么解决热点路径内存访问过多的问题。
杀手锏:优化热点路径内存访问
其实很简单,只需要把test_2.c中定义局部变量的时候加上register关键字就可以了:

C语言中,register关键字的作用是建议编译器,尽可能地把变量存放在寄存器中,以加快其访问速度。
我们现在看下,加了register关键字后,test_2.c的性能如何呢?
为方便对比,我们再看下添加register之前,test_2.c的耗时:
然后是加了register关键字之后的耗时:

看到差异了吧,相差3倍!加了register后,几乎达到了和加-O3优化选项一样的性能!
当然,register的使用还有很多限制,而且它只是给编译器的一种建议,不是强制要求,编译器只能尽量满足,当变量太多,寄存器不够用的时候,还是不得不把变量放到栈中,这和-O3的行为是一样的。
register不是本文重点,限于篇幅,不再赘述。
小结
循环展开是一种非常重要的优化方法,也是编译器后端中常用的一种优化方式,它可以通过减少热点路径上的“无用指令”以及分支指令的个数,来更好地发挥CPU指令流水线的指令并行执行能力,从而提高程序整体性能。
很多时候,我们可以借助编译器来帮我们实现这种优化,但编译器也有失效的时候,比如文中这个例子。这时,我们就不得不手动来进行循环展开来优化程序性能。循环展开时,必须尽量减少语句间的相互依赖。
此外,循环展开的次数并没有一个固定的公式,需要根据具体代码和CPU来决定,通常需要多次尝试来找到一个最优值。
不过,手动循环展开往往是以牺牲代码可读性为代价的,因此使用时也做好取舍。此外,循环展开还会在一定程度上增加程序代码段的大小,还可能会影响到程序局部性,对cache产生影响,因此使用时候,要仔细权衡。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++ Primer 6.3 返回类型和return语句 知识点+练习题
- 钉钉企业机器人单聊消息发送实践-大数据平台(XSailboat)消息中心消息推送
- 【无标题】
- 国产低时延技术创新与实践分享 | 2024低时延技术创新实践论坛精彩回顾来啦
- 性能优化-HVX架构简介
- AI智能视频监控系统-监控视频识别人员着装分析报警---豌豆云
- numpy-learn
- python用户账户管理
- 携手共进 探索生命|清华大学创融同学会走进生命系 共话细胞科技新未来
- HarmonyOS4.0系统性深入开发12 卡片数据交互说明