Spring 事务原理一
从本篇博客开始,我们将梳理Spring事务相关的知识点。在开始前,想先给自己定一个目标:通过此次梳理要完全理解事务的基本概念及Spring实现事务的基本原理。为实现这个目标我想按以下几个步骤进行:
- 讲解事务中的一些基本概念
- 使用Spring开发一个简单的事务案例,并作为后面代码跟踪的案例
- 跟踪Spring源码以梳理其实现事务的原理
下面就让我们按照这个步骤开始吧,本篇博客的目标有两个,一个是开发事务代码,一个是梳理事务中的基本概念。
事务中的基本概念
在日常工作中,大家都用过数据库,应该也知道在数据库层面有事务的概念。因为数据库作为一个公共资源,会被很多客户端操作,为了保证实际业务的准确性,一定要有一个方法来规避不可预料的风险。于是,数据库的设计者就提出了事务这个概念。在这个概念中一组操作组成了一个不可分割的操作单元,在这个操作单元中,所有的操作要么都成功,要么都失败,不能存在一部分成功一部分失败的情况发生,这个单元我将其称为事务单元(注意这里的事务单元我个人为了便于理解而自己起的一个名字)。就像组成元素的粒子一样,事务单元是一个无法分割的整体,其具有独立的行为模式,譬如事务A只修改A表中的一条记录,事务B会修改多张表中的多条记录。而事务具有不同行为模式的这个说法的根本原因是组成事务单元的操作序列不同。既然从操作者角度看,事务是一个独立的,且无法分割的具有不同行为模式的整体,那么为了达到这个效果,我们该如何实现呢?这是个非常复杂的问题,如果要回答是需要很多知识储备的,所以很抱歉。但我们可以这样想一下,代码本身就是在定义好的规则下运行的,那么为了实现这样一个事务单元,我们需要它具有什么样的规则呢?上面只是从宏观层面粗略的讲了一下事务单元的特点,那么从科学的角度来看事务究竟该具有一些什么特性呢?事务的特性主要有以下几点:
- 原子性(Atomicity):事务是数据库的逻辑工作单位,事务中包括的诸操作要么全做,要么全不做
- 一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态(一致性与原子性是密切相关的)
- 隔离性(Isolation):一个事务的执行不能被其他事务干扰
- 持久性(Durability):一个事务一旦提交,它对数据库中数据的改变就应该是永久性的
到这里,我不禁在想一个问题既然事务是一个基本的操作单元,并且这个操作单元具有上面所说的一些特性,那是不是就可以利用它为所欲为了?好像是可以的,首先我们去操作数据库的时候,有一个事务涉及到了很多表(前提:这个事务中涉及的多张表中的数据都要有变更),事务可以避免前一张表的数据变动,而后一张表数据无变化的情况发生(这里个人认为体现的是事务的原子性、一致性和持久性)。上面这个说法只是从单个事务的角度考虑的,而事实上数据库中的数据在同一时刻会被多个事务操作,这个时候这些事务又该如何执行呢?所以这里想再强调一点:事务不仅可单独运行,也可并发运行。事务是并发控制的基本单位。接下来我们先看一下多个事务并发执行时会出现一些什么问题吧:
- 脏读:所谓脏读就是事务A读取到了事务B尚未提交的数据,此时如果事务B发生错误并执行回滚操作,那么事务A读取到的数据就是脏数据。这就好比可以吃两份披萨的你,由于着急赶火车,只能拿取桌子上仅剩的一份披萨,虽然后前一个人后来又归还了一份回来,但由于你已经离开,所以无法知道这个结果。这种情况经常发生在转账和取款操作中,见下面这张图:

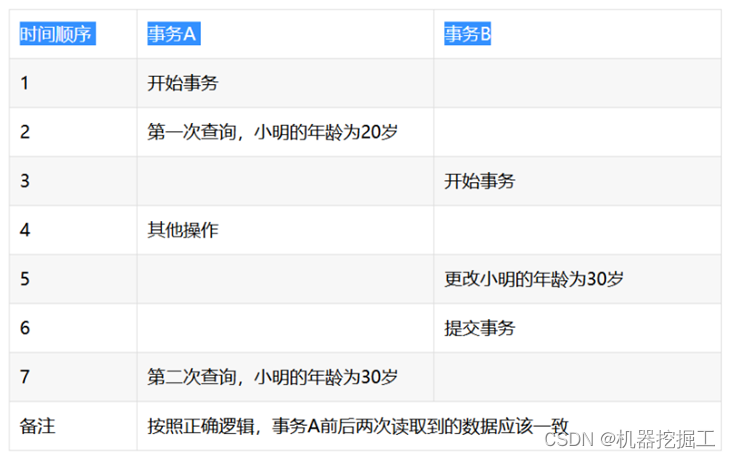
- 不可重复度:所谓不可重复读是指一个事务前后多次读取,而每次读取到的数据内容却不一致的情况。事务A在执行读取操作,由整个事务A比较大,前后读取同一条数据需要经历很长的时间。而在事务A第一次读取数据,比如此时读取了小明的年龄为20岁,事务B执行更改操作,将小明的年龄更改为30岁,此时事务A第二次读取到小明的年龄时,发现其年龄是30岁,和之前的数据不一样了,也就是数据不重复了,系统不可以读取到重复的数据,成为不可重复读。具体参见下面这幅图:
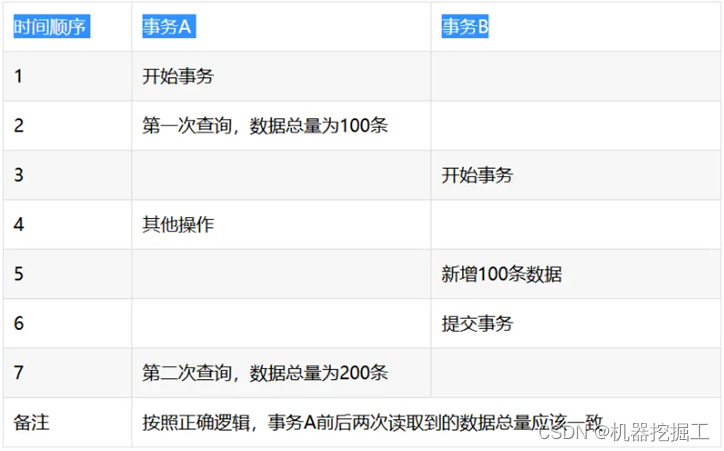
- 幻读:所谓幻读是指前后多次读取,拿到的数据总量不一致。事务A在执行读取操作,需要两次统计数据的总量,前一次查询数据总量后,此时事务B执行了新增数据的操作并提交后,这个时候事务A读取的数据总量和之前统计的不一样,就像产生了幻觉一样,平白无故的多了几条数据,成为幻读。具体详情请参见下面这幅图片:
这里想再对比一下幻读和不可重复读两个概念:不可重复读是读取了其他事务更改的数据,针对update操作。在MySQL中可以使用行级锁来解决。幻读是读取了其他事务新增的数据,针对insert和delete操作。在MySQL中可以使用表级锁来解决。
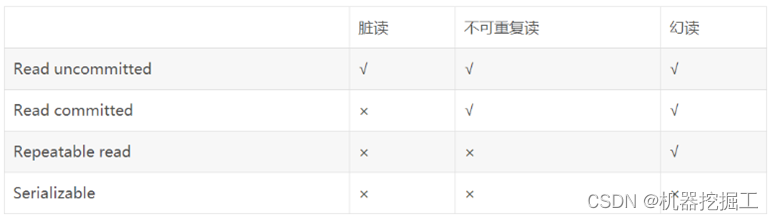
看过事务并发操作中可能出现的几个问题之后,我们再来想一下与数据库事务隔离级别有关的问题。SQL标准定义的四种隔离级别被ANSI(美国国家标准学会)和ISO/IEC(国际标准)采用,每种级别对事务的处理能力会有不同程度的影响。事务是一系列的动作,它们综合在一起才是一个完整的工作单元,这些动作必须全部完成,如果有一个失败的话,那么事务就会回滚到最开始的状态,仿佛什么都没发生过一样。数据库事务的4个隔离级别由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。具体见下面这张图:
?下面我们来详细梳理一下这几个隔离级别:
- READ UNCOMMITTED(读未提交):该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别
- READ_COMMITTED(读提交):该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值
- REPEATABLE_READ(可重复读):该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读
- SERIALIZABLE(串行化):该隔离级别下所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,所以该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。在该隔离级别下事务都是串行顺序执行的,MySQL数据库的InnoDB引擎会给读操作隐式加一把读共享锁,从而避免了脏读、不可重读复读和幻读问题
这里扩展一下——MVCC(多版本并发控制)。在MySQL中,默认的事务隔离级别是可重复读(repeatable-read),为了解决不可重复读,innodb采用了多版本并发控制来解决这一问题。MVCC是利用在每条数据后面加了隐藏的两列(创建版本号和删除版本号)来实现多版本并发控制的。每个事务在开始的时候都会有一个递增的版本号,用来和查询到的每行记录的版本号进行比较。
上面我们讲解了事务中的基本概念,接下来我们梳理一下Spring中与事务有关的几个常见问题:
Spring中的事务传播属性有几个,它们分别是什么?这个问题的答案要从Spring的事务实现组件TransactionDefinition接口中寻找,该接口的代码如下所示:
public interface TransactionDefinition {
/**
* Support a current transaction; create a new one if none exists.
* Analogous to the EJB transaction attribute of the same name.
* <p>This is typically the default setting of a transaction definition
* and typically defines a transaction synchronization scope.
*/
int PROPAGATION_REQUIRED = 0;
/**
* Support a current transaction; execute non-transactionally if none exists.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> For transaction managers with transaction synchronization,
* {@code PROPAGATION_SUPPORTS} is slightly different from no transaction
* at all, as it defines a transaction scope that synchronization might apply to.
* As a consequence, the same resources (a JDBC {@code Connection}, a
* Hibernate {@code Session}, etc) will be shared for the entire specified
* scope. Note that the exact behavior depends on the actual synchronization
* configuration of the transaction manager.
* <p>In general, use {@code PROPAGATION_SUPPORTS} with care. In particular, do
* not rely on {@code PROPAGATION_REQUIRED} or {@code PROPAGATION_REQUIRES_NEW}
* <i>within</i> a {@code PROPAGATION_SUPPORTS} scope (which may lead to
* synchronization conflicts at runtime). If such nesting is unavoidable, make sure
* to configure your transaction manager appropriately (typically switching to
* "synchronization on actual transaction").
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#SYNCHRONIZATION_ON_ACTUAL_TRANSACTION
*/
int PROPAGATION_SUPPORTS = 1;
/**
* Support a current transaction; throw an exception if no current transaction
* exists. Analogous to the EJB transaction attribute of the same name.
* <p>Note that transaction synchronization within a {@code PROPAGATION_MANDATORY}
* scope will always be driven by the surrounding transaction.
*/
int PROPAGATION_MANDATORY = 2;
/**
* Create a new transaction, suspending the current transaction if one exists.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> Actual transaction suspension will not work out-of-the-box
* on all transaction managers. This in particular applies to
* {@link org.springframework.transaction.jta.JtaTransactionManager},
* which requires the {@code jakarta.transaction.TransactionManager} to be
* made available to it (which is server-specific in standard Jakarta EE).
* <p>A {@code PROPAGATION_REQUIRES_NEW} scope always defines its own
* transaction synchronizations. Existing synchronizations will be suspended
* and resumed appropriately.
* @see org.springframework.transaction.jta.JtaTransactionManager#setTransactionManager
*/
int PROPAGATION_REQUIRES_NEW = 3;
/**
* Do not support a current transaction; rather always execute non-transactionally.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> Actual transaction suspension will not work out-of-the-box
* on all transaction managers. This in particular applies to
* {@link org.springframework.transaction.jta.JtaTransactionManager},
* which requires the {@code jakarta.transaction.TransactionManager} to be
* made available to it (which is server-specific in standard Jakarta EE).
* <p>Note that transaction synchronization is <i>not</i> available within a
* {@code PROPAGATION_NOT_SUPPORTED} scope. Existing synchronizations
* will be suspended and resumed appropriately.
* @see org.springframework.transaction.jta.JtaTransactionManager#setTransactionManager
*/
int PROPAGATION_NOT_SUPPORTED = 4;
/**
* Do not support a current transaction; throw an exception if a current transaction
* exists. Analogous to the EJB transaction attribute of the same name.
* <p>Note that transaction synchronization is <i>not</i> available within a
* {@code PROPAGATION_NEVER} scope.
*/
int PROPAGATION_NEVER = 5;
/**
* Execute within a nested transaction if a current transaction exists,
* behaving like {@link #PROPAGATION_REQUIRED} otherwise. There is no
* analogous feature in EJB.
* <p><b>NOTE:</b> Actual creation of a nested transaction will only work on
* specific transaction managers. Out of the box, this only applies to the JDBC
* {@link org.springframework.jdbc.datasource.DataSourceTransactionManager}
* when working on a JDBC 3.0+ driver. Some JTA providers might support
* nested transactions as well.
* @see org.springframework.jdbc.datasource.DataSourceTransactionManager
*/
int PROPAGATION_NESTED = 6;
/**
* Use the default isolation level of the underlying datastore.
* <p>All other levels correspond to the JDBC isolation levels.
* @see java.sql.Connection
*/
int ISOLATION_DEFAULT = -1;
/**
* Indicates that dirty reads, non-repeatable reads, and phantom reads
* can occur.
* <p>This level allows a row changed by one transaction to be read by another
* transaction before any changes in that row have been committed (a "dirty read").
* If any of the changes are rolled back, the second transaction will have
* retrieved an invalid row.
* @see java.sql.Connection#TRANSACTION_READ_UNCOMMITTED
*/
int ISOLATION_READ_UNCOMMITTED = 1; // same as java.sql.Connection.TRANSACTION_READ_UNCOMMITTED;
/**
* Indicates that dirty reads are prevented; non-repeatable reads and
* phantom reads can occur.
* <p>This level only prohibits a transaction from reading a row with uncommitted
* changes in it.
* @see java.sql.Connection#TRANSACTION_READ_COMMITTED
*/
int ISOLATION_READ_COMMITTED = 2; // same as java.sql.Connection.TRANSACTION_READ_COMMITTED;
/**
* Indicates that dirty reads and non-repeatable reads are prevented;
* phantom reads can occur.
* <p>This level prohibits a transaction from reading a row with uncommitted changes
* in it, and it also prohibits the situation where one transaction reads a row,
* a second transaction alters the row, and the first transaction re-reads the row,
* getting different values the second time (a "non-repeatable read").
* @see java.sql.Connection#TRANSACTION_REPEATABLE_READ
*/
int ISOLATION_REPEATABLE_READ = 4; // same as java.sql.Connection.TRANSACTION_REPEATABLE_READ;
/**
* Indicates that dirty reads, non-repeatable reads, and phantom reads
* are prevented.
* <p>This level includes the prohibitions in {@link #ISOLATION_REPEATABLE_READ}
* and further prohibits the situation where one transaction reads all rows that
* satisfy a {@code WHERE} condition, a second transaction inserts a row
* that satisfies that {@code WHERE} condition, and the first transaction
* re-reads for the same condition, retrieving the additional "phantom" row
* in the second read.
* @see java.sql.Connection#TRANSACTION_SERIALIZABLE
*/
int ISOLATION_SERIALIZABLE = 8; // same as java.sql.Connection.TRANSACTION_SERIALIZABLE;
/**
* Use the default timeout of the underlying transaction system,
* or none if timeouts are not supported.
*/
int TIMEOUT_DEFAULT = -1;
/**
* Return the propagation behavior.
* <p>Must return one of the {@code PROPAGATION_XXX} constants
* defined on {@link TransactionDefinition this interface}.
* <p>The default is {@link #PROPAGATION_REQUIRED}.
* @return the propagation behavior
* @see #PROPAGATION_REQUIRED
* @see org.springframework.transaction.support.TransactionSynchronizationManager#isActualTransactionActive()
*/
default int getPropagationBehavior() {
return PROPAGATION_REQUIRED;
}
/**
* Return the isolation level.
* <p>Must return one of the {@code ISOLATION_XXX} constants defined on
* {@link TransactionDefinition this interface}. Those constants are designed
* to match the values of the same constants on {@link java.sql.Connection}.
* <p>Exclusively designed for use with {@link #PROPAGATION_REQUIRED} or
* {@link #PROPAGATION_REQUIRES_NEW} since it only applies to newly started
* transactions. Consider switching the "validateExistingTransactions" flag to
* "true" on your transaction manager if you'd like isolation level declarations
* to get rejected when participating in an existing transaction with a different
* isolation level.
* <p>The default is {@link #ISOLATION_DEFAULT}. Note that a transaction manager
* that does not support custom isolation levels will throw an exception when
* given any other level than {@link #ISOLATION_DEFAULT}.
* @return the isolation level
* @see #ISOLATION_DEFAULT
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#setValidateExistingTransaction
*/
default int getIsolationLevel() {
return ISOLATION_DEFAULT;
}
/**
* Return the transaction timeout.
* <p>Must return a number of seconds, or {@link #TIMEOUT_DEFAULT}.
* <p>Exclusively designed for use with {@link #PROPAGATION_REQUIRED} or
* {@link #PROPAGATION_REQUIRES_NEW} since it only applies to newly started
* transactions.
* <p>Note that a transaction manager that does not support timeouts will throw
* an exception when given any other timeout than {@link #TIMEOUT_DEFAULT}.
* <p>The default is {@link #TIMEOUT_DEFAULT}.
* @return the transaction timeout
*/
default int getTimeout() {
return TIMEOUT_DEFAULT;
}
/**
* Return whether to optimize as a read-only transaction.
* <p>The read-only flag applies to any transaction context, whether backed
* by an actual resource transaction ({@link #PROPAGATION_REQUIRED}/
* {@link #PROPAGATION_REQUIRES_NEW}) or operating non-transactionally at
* the resource level ({@link #PROPAGATION_SUPPORTS}). In the latter case,
* the flag will only apply to managed resources within the application,
* such as a Hibernate {@code Session}.
* <p>This just serves as a hint for the actual transaction subsystem;
* it will <i>not necessarily</i> cause failure of write access attempts.
* A transaction manager which cannot interpret the read-only hint will
* <i>not</i> throw an exception when asked for a read-only transaction.
* @return {@code true} if the transaction is to be optimized as read-only
* ({@code false} by default)
* @see org.springframework.transaction.support.TransactionSynchronization#beforeCommit(boolean)
* @see org.springframework.transaction.support.TransactionSynchronizationManager#isCurrentTransactionReadOnly()
*/
default boolean isReadOnly() {
return false;
}
/**
* Return the name of this transaction. Can be {@code null}.
* <p>This will be used as the transaction name to be shown in a
* transaction monitor, if applicable.
* <p>In case of Spring's declarative transactions, the exposed name will be
* the {@code fully-qualified class name + "." + method name} (by default).
* @return the name of this transaction ({@code null} by default}
* @see org.springframework.transaction.interceptor.TransactionAspectSupport
* @see org.springframework.transaction.support.TransactionSynchronizationManager#getCurrentTransactionName()
*/
@Nullable
default String getName() {
return null;
}
// Static builder methods
/**
* Return an unmodifiable {@code TransactionDefinition} with defaults.
* <p>For customization purposes, use the modifiable
* {@link org.springframework.transaction.support.DefaultTransactionDefinition}
* instead.
* @since 5.2
*/
static TransactionDefinition withDefaults() {
return StaticTransactionDefinition.INSTANCE;
}
}
从这段代码不难看出,TransactionDefinition接口中主要定义了Spring事务的传播属性及隔离级别。其中事务传播属性有7个,事务隔离级别有5个。其中7个事务传播属性分别为:
- PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务
- PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行
- PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常
- PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起
- PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起
- PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常
- PROPAGATION_NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于REQUIRED
4个事务隔离级别分别为:
- ISOLATION_DEFAULT:使用基础数据存储的默认隔离级别。所有其他级别都对应于JDBC隔离级别
- ISOLATION_READ_UNCOMMITTED:读未提交
- ISOLATION_READ_COMMITTED:读已提交
- ISOLATION_REPEATABLE_READ:可重复读
- ISOLATION_SERIALIZABLE:序列化读
Spring事务开发案例
在Spring中开发事务代码有三种方式:基于xml配置式、编程式、声明式。其中最常用的时声明式。由于第一种开发方式相对古老,所以这里不再介绍,下面讲着重介绍后两种方式:
- 编程式:所谓编程式事务是指通过使用Spring事务组件手动开发代码来实现对事务的管理,这里的事务组件是指PlatformTransactionManager、TransactionTemplate等等,实践中更加推荐使用TransactionTemplate。在工作中有幸使用过前一种来对数据库操作进行管理
- 声明式:所谓声明式事务是指采用Spring Boot相关组件提供的事务注解来实现对事务管理,这里的事务注解是指@Transaction等等。本系列教程要讲解的就是这部分事务的原理。
关于这两种事务管理方式优缺点的一些说明:
- 编程式事务允许用户在代码中精确定义事务的边界,但是这种方式侵入了系统业务代码,对代码产生了一定的影响(简言之就是事务管理更加细致,但是对业务代码有一定的影响)
- 声明式事务有助于用户将操作与事务规则进行解耦,它基于AOP最终会交由Spring容器实现,开发人员只需关注业务逻辑实现即可(这种方式不仅仅开发简单,而且减少了代码开发量,并且代码看起来更加清爽整洁)
下面我们主要讲解声明式事务的开发案例,这种方式的入口为Application.java类,其代码如下所示:
import org.com.chinasofti.springtransaction.service.TransferService;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import java.math.BigDecimal;
@SpringBootApplication
@EnableAspectJAutoProxy
// 注意这个注解
@EnableTransactionManagement
public class SpringTransactionApplication {
public static void main(String[] args) {
// SpringApplication.run(SpringTransactionApplication.class, args);
// 下面这段逻辑,可以根据需要新增
TransferService transferService = (TransferService) SpringApplication.run(SpringTransactionApplication.class, args).getBean(TransferService.class);
transferService.check("jack", "tom", BigDecimal.valueOf(100));
}
}
注意上面代码中的@EnableTransactionManagement这个注解。下面主要看一下案例的业务代码,首先看一下业务接口TransferService代码,如下所示:
import java.math.BigDecimal;
public interface TransferService {
void check(String from, String to, BigDecimal money);
void transfer(String from, String to, BigDecimal money);
}
接着再来看一下该业务接口实现类TransferServiceImpl的代码,主要关注该类上面的注解@Transactional,具体代码为:
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.math.BigDecimal;
/**
* 环绕增强开始!!
* 开始增强!!
* 校验开始
* 校验中||...........
* 校验中==...........
* 校验结束
* 返回之后执行
* 结束增强!!
* 环绕增强结束!!
*/
@Service("transferService")
@Transactional
public class TransferServiceImpl implements TransferService {
@Override
public void check(String from, String to, BigDecimal money) {
System.out.println("校验开始");
System.out.println("校验中||...........");
try {
System.out.println(1 / 0);
Thread.sleep(1000 * 5);
} catch (InterruptedException e) {
}
System.out.println("校验中==...........");
System.out.println("校验结束");
}
@Override
public void transfer(String from, String to, BigDecimal money) {
System.out.println("转账开始");
System.out.println("转账中...........");
System.out.println("转账结束");
}
}
这样事务相关的代码就开发完了。注意这里我们并没有列出操作数据表的代码。(声明文中所列内容部分源自网络,尤其《一文搞懂什么是事务 - 知乎 (zhihu.com)》这篇博文,如果想看原文,可以看点击上面的链接。在此向这篇博文作者说声谢谢!)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于springboot+vue的网上点餐系统(前后端分离)
- 12/26 两数之和
- Unity 面试篇|(二)Unity基础篇 【全面总结 | 持续更新】
- Vue 3与Composition API:入门指南
- “联名”盛行,2024品牌的进场机会在哪里?
- 第十二章 Java内存模型与线程(二)
- Windows平台程序和Android平台程序的差异
- 七八分钟快速用k8s部署springboot前后端分离项目
- 【Linux】Linux进程间通信
- 航空产业奖补!2024年双流区推动航空经济高发展政策申报奖补内容