Ziya-Visual-Lyrics模型:高效的视觉识别与语言处理融合
前言
在当今多模态大模型的研究与应用中,封神榜大模型团队的最新力作Ziya-Visual-Lyrics在多个方面实现了显著的技术突破。该模型综合了细粒度的视觉处理和先进的语言理解能力,为多模态人工智能领域带来了革命性的影响。
伴随着GPT4V、Gemini等模型的崛起,多模态大模型已经超越了传统的大语言模型范畴,涵盖图像、音频、视频等多种模态。这些模型不仅仅是技术上的飞跃,更开启了多模态大模型应用的新篇章。Ziya-Visual-Lyrics模型就是在这一背景下诞生的,它的出现预示着多模态技术的新高度。

技术亮点
Ziya-Visual-Lyrics引入了视觉细化器,并采用了细粒度的两阶段视觉语言训练框架Lyrics,有效地促进了模型在处理视觉对象时的语义感知能力。该模型的视觉细化器包含图像标记、目标检测和语义分割模块,显著提升了模型对图像细节的理解能力。此外,Ziya-Visual-Lyrics还采用了多尺度Querying Transformer (MQ-Former) 结构来对齐视觉和语言特征,进一步提高了模型的处理效率和准确性。
-
Huggingface模型下载:https://huggingface.co/IDEA-CCNL/Ziya-Visual-Lyrics-14B
-
AI快站模型免费加速下载:https://aifasthub.com/models/IDEA-CCNL/Ziya-Visual-Lyrics-14B
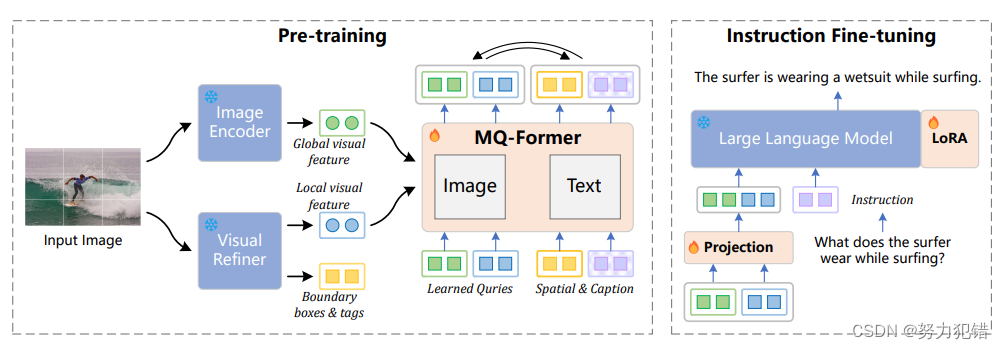
架构与功能
Ziya-Visual-Lyrics在其架构设计上,巧妙地融合了CLIP中的ViT-L/14图像编码器和三个视觉模块,以抽取图像的全局特征和局部特征。这种架构使得模型能够精确地处理图像中的复杂信息,并与文本信息有效结合。

测评
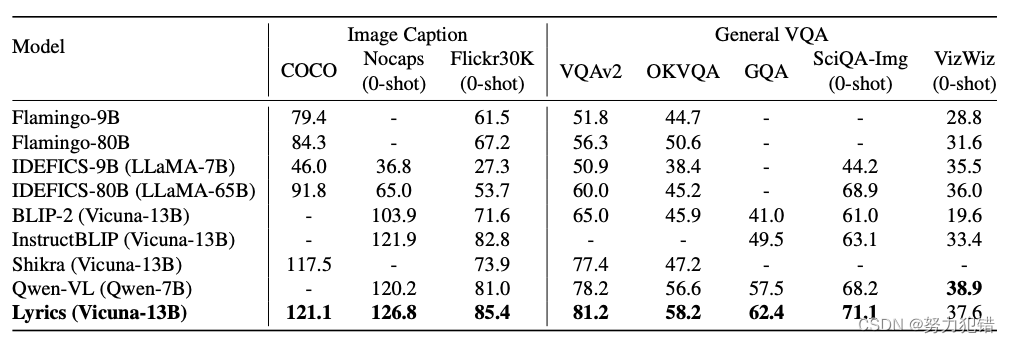
在广泛的评测任务上,如图像描述、视觉问答和指向性表达理解,Ziya-Visual-Lyrics都展现出了优秀的性能。模型在多个零样本任务上取得SOTA成果,证明了其出色的多模态处理能力。案例展示中,Ziya-Visual-Lyrics能够精确识别图片中对象的数量、颜色、方位等细节信息。例如,在识别滑雪者的示例中,模型不仅准确指出了图片中滑雪者的数量和状态,还能识别出他们的服装颜色和具体位置。
数据处理
Ziya-Visual-Lyrics的训练涵盖了5亿高质量的图文对,确保了模型在一阶段的预训练中能够获取丰富的视觉和语言信息。在二阶段的指令微调中,模型处理了包括多种多模态场景的7类任务,使其能够灵活应对各类复杂场景。

展望
Ziya-Visual-Lyrics模型的推出标志着多模态大模型领域的一个重要里程碑。通过其创新的技术架构和强大的功能,该模型在多模态理解和生成任务上表现出色,成为多模态大模型研究和应用的新典范。封神榜团队的这一突破不仅提高了模型在视觉和语言处理上的精准度和适应性,也为未来的多模态人工智能研究指明了方向。
模型下载
Huggingface模型下载
https://huggingface.co/IDEA-CCNL/Ziya-Visual-Lyrics-14B
AI快站模型免费加速下载
https://aifasthub.com/models/IDEA-CCNL/Ziya-Visual-Lyrics-14B
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!