【征服Redis10】一文理解redis为什么这么快
Redis之所以一统分布式缓存的江湖,其中一大优势就是快,到底有多快呢?官方测试数据表明每秒可以处理13万次set或者lpush请求,执行lua调用可以达到12万次之多。一般来说,我们的Java服务,单台服务qps到达1000就很难了,可见这个数量确实高,那redis为什么快呢?今天我们就来讨论一下。
目录
简单来说,主要是三点:
- 纯内存结构
- 请求处理单线程
- 多路复用机制
我们接下来详细解释,后面两个紧密相关,我们放在一起来解释。
1.Redis的纯内存结构
redis是纯KV结构的内存数据库,正常使用的数据都是在内存里的,不涉及将数据保存到硬盘等工作(当然redis也有数据同步机制,不过redis正常工作的时候不需要使用)。由此,redis的数据处理就会快很多,而且也省去了复杂的IO管理等问题, 因此效率要高很多。
redis是基于内存的操作,我们在后面讨论缓存、JVM虚拟机、垃圾回收等问题时,也经常会提到“将数据放在内存、常驻内存等概念”,那内存到底是怎么回事,我们有必要结合操作系统的工作原理来看一下该如何管理内存。
所谓的内存就是我们计算机里安装的一个内存条,也称为主存,在笔记本里的结构如下所示:而硬盘等则称为辅存

在早些年,电脑以台式机为主,很多人喜欢自己选配件组装(DIY),因此对这些非常熟悉。而现在大部分人都使用笔记本,很少人拆机,所以对其熟悉的少。
所谓的内存,其实就是一个超大号的数组,有多大呢?就是平时电脑上标记的4G、8G、512G这样子,每个字节一个单元,内个字节都有自己唯一的地址,这就是物理地址的概念。
很自然的想到,如果CPU需要内存,那么就从主内存里分出一块来就行了。就像很久很久之前,如果你想有自己的房子,那只要找块空地,再弄些材料盖个瓦房就行了。这个看起来很合理,但是存在很大的弊端:
1.一般操作系统都是多用户多任务的,所有进程共享主存,如果每个进程都独占一块物理空间,主存很快就用完了,这就像在农村盖瓦房还能接收,如果在城市里也这么做,那自然是没有这么多地的。
2.如果所有进程都是直接访问物理内存,此时进程就可以修改其他进程的内存数据,导致物理地址空间被破坏,程序运行就会出现异常。这就好比你想盖大一点的房子,就先把邻居的房子给拆了,这是不行的。
虽然存在这种问题,但是现在在微信传感器、嵌入式设备、物联网领域,这种方式仍然大量使用的,原因是这类场景功能是单一的,这类分配方案简单、功耗低,因此我们不能说这种方式一无是处。
那对于比较复杂的手机、电脑等场景那怎么办呢?此时应该有个角色或者机制来进行统一协调,这个就是内存管理单元,而引入的机制就是虚拟地址。
我们前面说物理地址就是你的内存条的实际容量,比如16G、256G这样子,而虚拟地址有多大呢?这取决于你的CPU对外的连线数,一般是只有32位或者64位。我们可以通过下面的图来感受一下:

如果CPU对外有32根线,那此时32根线能表示的数值空间就是 2^32=4G,因此虚拟地址空间就是4G。也是为什么早期32位的操作系统存储文件不能超过4G,因为大了就表示不了了。当然这个图是不严谨的,因此CPU对外还要有电源等等一系列的线路,我们这里主要是为了直观的理解CPU的工作原理。
如果是64位系统能表示的空间就是2^64=1024*1024TB。很明显这是一个极大的数据,现在TB的硬盘都不多,因此这么大的内存是没有意义的。这时候我们就没有必要将所有的线全用上。在linux一般使用低48位来表示虚拟地址空间,也就是2^48=256T。
事实上,256T还是多了,在Java最新的ZGC垃圾回收器里,只用了低44位,也就是16T的空间,之后的4位是标志位。
由此也可以看到:实际的物理地址可能远远小于虚拟内存的大小。
总结一下,虚拟内存的作用是:
1.通过把同一块物理内存映射到不同的虚拟地址空间实现内存共享
2.对物理内存进行隔离,不同的进程操作互不影响。
3.虚拟内存可以提供更大的地址空间,并且地址空间是连续的,是的程序编写等等更加容易。
上面后两条还比较好理解,但是第一条我们可能会有疑问:一块地址为什么能在不同的虚拟空间里用的呢?
这个详细情况在操作系统、计算机组成原理、计算机体系结构等课程里会花大量篇幅来介绍,这里我们只介绍一下核心原理——同一块地址是在不同的时机被共享的。比如地址100~999这个空间,在第一分钟里是被进程1使用,在第二分钟被第二个进程使用。而两个进程是由操作系统统一来安排具体执行的时候用哪个物理空间的,但是进程1和2自己则根本不知道。
我们可以举个例子,假如我们将北京全部可出租的房屋集中起来,假如有100万间,但是呢每天都有人租房、退房,假如人员流动比例是50%,那这时候我就可以对外宣布,我们每年可以为150万提供租房服务。当有人来租房的时候,作为平台,我们只要看一下哪里空着安排过去就行了。而这个房间本身可能一个月之前还是有人住的,这就实现了房间的共享。
“同一块地址是在不同的时机被共享的”,这一点是理解虚拟映射的关键点,在JVM的ZGC的内存映射等场景用的共享,其实都是这个道理。
2.请求处理单线程与多路复用机制
一般来说,我们提到高效率,就想到要采用多线程方式,但是不见得多线程适合所有场景。多线程工作的本质是这些任务不是真的在同时运行, 而是根据时间片分片算法,在很短的时间里,将CPU轮流分配给不同的任务,从而造成多任务同时运行个错觉。
那为什么CPU可以轮流分配呢?这是因为CPU主要负责处理核心指令,而费时费力的具体任务则是有不同的外设花费很多时间才能完成。
我们举个例子 ,例如在一个公司里,要实现一个业务,程序员、测试和产品经理可能需要加班加点很长时间才能完成,而领导只关心这个任务:什么时候开始、什么时候能上线、什么时候可以通知市场部对外宣传了,而具体的工作则是下面的人在做。所以领导整体面对的就是各种“请示和决策”,而这个只有几句话就可以了,计算机在工作的时候,CPU就是这个领导,要“日理万机”,而外设就是具体干活的。
在CPU进行任务交替的时候,为了控制进程的执行,这时候必须现将正在运行的程序挂起,然后再恢复以前挂起的某个进程的执行,这种行为就是进程切换,而切换时需要保存或者恢复的数据信息等则成为“上下文 Context”。
?由此可见,切换任务本身也是要消耗资源的。这也是很多程序员在做事的时候被频繁打扰会很恼火。因为一个事情我们做的时候,需要打开对应的程序代码、执行后台、监控等等,频繁切换会让我们忙忙碌碌,但是什么也没做。
正在运行的进程执行的时候需要获取某些资源,例如IO数据等,但是没有得到及时的响应,则进程只能将自己变成阻塞状态,也就是“在门外候着”,等待响应的事件出现后才被唤醒。
这就是多线程执行的时候面临的具体场景。为了解决这种阻塞的问题,我们有几个解决的思路:
1.在服务端创建多个线程或者使用线程池,这个是大部分场景都适合的方案,但是redis面临的高并发的时候需要的线程会非常多。
2.由请求方定期轮询,在数据准备完毕后再从执行。很明显,如果轮询周期长 ,会导致比较大的延迟。
那能不能用一个线程来处理多个客户端的请求?这就是多路复用机制。
多路值得是多个TCP链接,复用指的是一个或多个线程。它的基本原理是不再由应用程序自己来监视连接,而是由操作系统来完成,具体来说是操作系统内核接替应用程序来监视文件描述符。具体如何监视的,我们就不展开了,具体可以学习linux系统下的epoll机制、max系统下的kqueue机制或者solaris系统下的evport机制。
使用了这种机制之后,客户端在操作的时候会产生不同事件类型的socket,而在服务端,IO多路复用程序会把消息放入到队列中,然后通过文件事件分派器,转发到不同的事件处理器中。
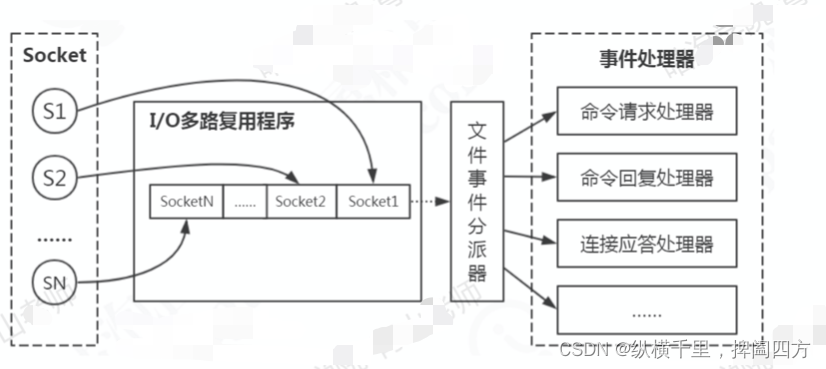
这个就像信访局统一接待各种各样来信访的人,信访局统一登记、管理,然后通知到对应的部门,平时各个部门则干自己的事情就好,这就是IO多路复用的原理。类似的在互联网公司,也是有客服部专门处理用户反馈的信息,然后右客服部来联系对应的部门,一般不允许研发人员等人员直接找用户。
我们一直在说的redis新版本有多线程特征,这个不是服务端接收客户请求变成多线程,它本身还是单线程的。多线程主要用来处理一些耗时长的工作和后台同步等工作。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!