在AWS设计一个百万用户的系统
1: 定义Use Case和约束
Use cases
解决这个问题需要进行初始化的操作:1) Benchmark/Load Test, 2) Profile for bottlenecks 3) address bottlenecks 当评估最优化的替代解 4)重复,找到最好的方案。
除非你有 AWS 的背景,或者你正在申请一个需要 AWS 知识的职位,AWS 特定的细节不是一个需求。然而,讨论的大量实践原则会被应用在 AWS 生态之外
定义作用域内的Use Case
- User 制作一个 Read / Write 请求
- Service 做处理,存储 User Data, 然后返回结果
- Service 需要从服务少量用户到服务百万用户
- 讨论普遍的迭代架构的扩展方法,然后去处理大量的 user 和 request
- Service 有高可用
约束和假设
状态假设
- Traffic不是平均分布的
- 需要关系型数据
- 从一个 User 扩展到 数百万 User
- 表示 user 的增长比如:
- Users+
- Users++
- Users+++
- …
- 一千万 users
- 十亿 写请求 / 月
- 千亿 读请求 / 月
- 100 :1 读写比率
- 每次写入 1 KB 内容
- 表示 user 的增长比如:
计算使用量
-
1 TB 新内容 / 月
- 1 KB / 写 * 十亿 写 / 月
- 36 TB 的新内容 / 三年
- 假设大多数写入来自新内容,而不是对现有内容的更新
-
平均400 写请求 / s
-
平均4000 读请求 / s
简易转换指南:
- 250 万 s / 月
- 1 request / s = 250 万 request/ 月
- 40 request / s = 一亿 request / 月
- 400 request / s = 十亿 请求 / 月
2: 创建一个 High Level设计
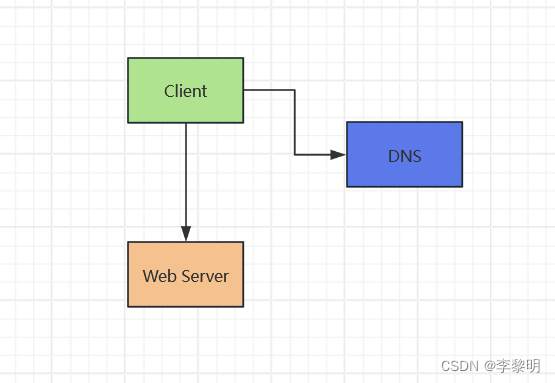
3: 设计核心组件
Use case: User 发起一个读或写 请求
目标
- 伴随着 1-2 users, 你只主要基础的setup
- 单个 box 为了简化
- 当需要的时候垂直扩展
- 监控和确认 bottlenecks
单个 box 为了简化:
-
Web Server on EC2
- Stotage for user data
- MySQL Database
-
当需要的时候垂直扩展
- 简化选择一个更大的 box
- 关注 metrix 数据去确定怎样去扩展
- 使用基础的监控去确定瓶颈: CPU,memory,IO,network等
- CloudWatch, top, nagios, statsd, graphite, 等
- 垂直扩展会是非常昂贵的
- 没有冗余 / 故障转移
也可以考虑使用水平扩展!!!
从 SQL 开始,思考使用 NoSQL
这些约束假设需要关系数据。我们可以在单个盒子上使用MySQL数据库。
Assign 一个 公众静态 IP
- 弹性 IP 提供了一个公共端点,其 IP 在重新启动时不会改变
- 帮助进行故障转移,只需将域名指向新IP即可
使用DNS
要在Route 53等DNS中添加一个记录,将域名映射到实例的公共IP地址
Web Server的安全配置
- 只是打开必要的端口
- 允许 web server去响应请求从:
- 80 for HTTP
- 443 for HTTPS
- 22 for SSH 到 白名单允许的IP
- 防止Web服务器启动出站连接
- 允许 web server去响应请求从:
4:扩展这个设计
Users+
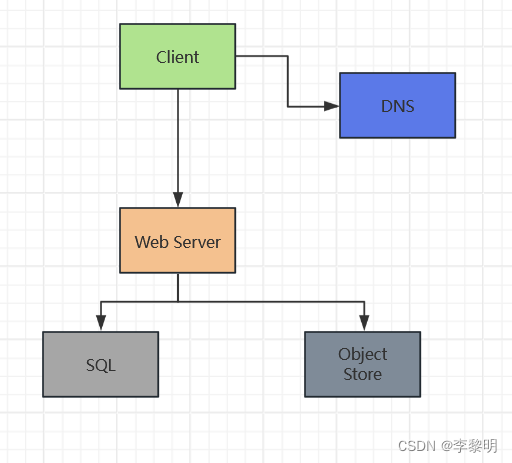
假设:
我们的User count 正在开始去挑选,而且负载正在我们的 Single Box中增长,我们的 Benchmarks/Load Tests 和 Profiling 正在指向 MySQL Database ,而且会占用越来越多的内存和 CPU资源,当这个User 内容正在填充磁盘空间的时候。
我们已经能够定位这些问题通过垂直扩展现在, 不幸的是,这已经成为十分昂贵的,而且它不会允许独立的扩展到MySQL Database和Web Server.
目标:
- 减少Single Box的负载,而且允许独立的扩展
- 分开存储静态内容进Object Store
- 移动
MySQL Database到分开的 box
- 劣势
- 这些改动会增加复杂度,而且需要发改动到
Web Server进Object Store和MySQL Database - 必须采取额外的安全措施来保护新组件
- AWS花费也会增加,但应权衡自行管理类似系统的成本
分开存储静态内容:
- 思考使用受管理的
Object Store, 比如 S3, 去存储静态内容
- 高扩展和高可用
- Server 端加密
- 移动静态内容到 S3
- User files
- JS
- CSS
- Images
- Vedeos
移动MySQL 数据库到分开的 box
- 思考使用一个 Service(比如 RDS)去管理MySQL Database
- Simple 到 Administer, 扩展
- 多个可用空间
- 加密剩下的
系统安全
- 加密传输中和静止的数据
- 使用虚拟的私有云
- 针对单个Web Server创建一个公有的子网,所以从网络发送和接收Traffic。
- 创建一个私有的子网,预防外部访问
- 只是针对每个组件开放白名单
- 这些相同的模式应在练习的剩余部分中应用于新组件
User++
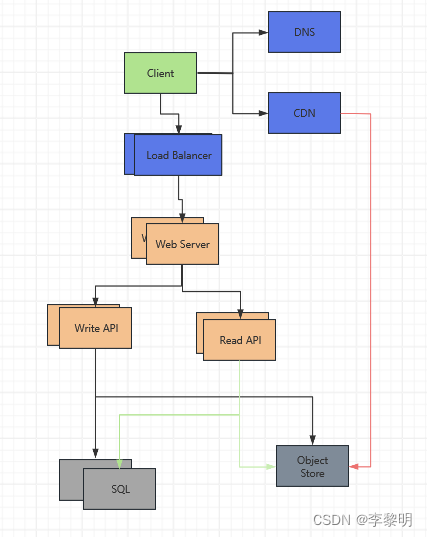
假设
我们的基准测试/负载测试和性能分析表明,我们的单台Web服务器在高峰时段存在瓶颈,导致响应速度缓慢,在某些情况下甚至会导致停机。随着服务的成熟,我们还将朝着更高的可用性和冗余性迈进。
目标
- 以下目标尝试去解决
Web Server的扩展问题- 基于 Benchmarks/Load Test和调优,你或许只需要实现一个或者两个技术点
- 使用水平扩展去处理正在增长的负载,然后去定位单点故障
- 添加 Load Balancer, 比如Amazon的
ELB或者HAProxyELB是高可用的- 如果你正在配置你自己的
Load Balancer, 设置多个 server 在 active-active 或者 active-passive 到多个可用空间将提高可用性 - 在
Load Balancer上关闭 SSL 可以减少后端 server的计算负载,而且去简化证书管理
- 使用多个
Web Server扩展开,通过多个可用空间 - 使用多个
MySQL实例在 Master-Slave Failover 模式,通过多个可用空间去提高容错率
- 添加 Load Balancer, 比如Amazon的
- 从Application Servers里面分离出 Web Server
- 独立的扩展和配置这两层
Web Servers可以运行作为Reverse Proxy- 比如,你可以添加
Applictaion Servers处理 Read APIs(当处理 Write API的时候)
- 移动静态(和一些动态)内容到 Content Delivery Network (CDN),比如 CloudFront, 去减少负载和延迟
Users+++
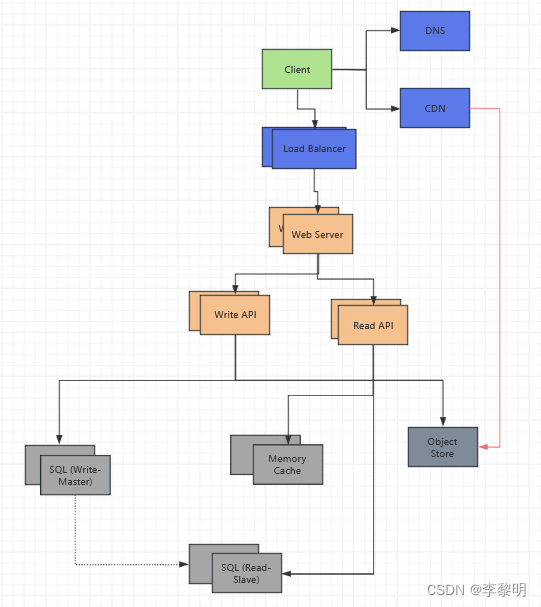
目标
移动以下的数据到Memory Cache,比如 Elasticcache 去减少负载和延迟:
- 频繁的从MySQL访问内容
- 首先,在实现内存缓存之前,尝试配置MySQL数据库缓存,以查看这是否足以缓解瓶颈
- Web Server中的 Session data
Web Server变成无状态的,允许自动扩展- 从内存中顺序读取 1 MB 数据大约需要 250 微秒,而从 SSD 读取需要 4 倍的时间,从磁盘读取需要 80 倍的时间。
- 添加 MySQL Read Replicas 去减少 写主库的负载
- 添加更多
Web Server和Application Server去提高响应率
添加 MySQL 读副本
- 处理添加可扩展内存,MySQL 写副本也可以帮助减少写主库上的负载
- 添加 logic 到
Web Server同分离写和读请求 - 添加
Load Balancer在MySQL Read Replicas的前面 - 大部分的 services 是 read-heavy vs write-heavy
User++++
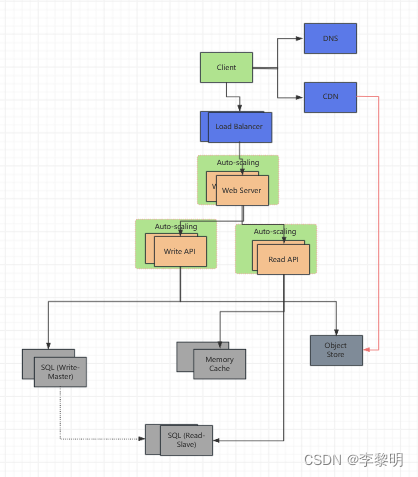
目标
- 添加自动扩展功能,根据需要配置容量
- 及时了解交通高峰情况
- 通过关闭未使用的实例来降低成本
- 自动化 DevOps
- Chef, Pupet, Ansible等
- 继续监控指标去定位系统瓶颈
- Host Level - Review 单个 EC2 实例
- Aggragate Level - Review load balancer 状态
- Log analysis - CloudWatch, CloudTrail, Loggly, Splunk, Sumo
- External site performance - Pingdom 或者 New Relic
- Handle notifications 和 incidents - PagerDuty
- Error Reporting - Sentry
添加 Autoscaling
思考使用管理 Service, 比如 AWS Autoscaling
- 针对每个
Web Server创建一个组,而且一个为了每个Application ServerType, 放每个组到多个可靠空间 - 设置最小或最大数字的实例
- 通过CloudWatch Trigger 去扩展或者缩小
- 可预测的负载简化度量
- 通过时间段的度量
- CPU load
- Latency
- Network traffic
- Custom metric
- 劣势
- Autoscaling 会增加复杂度
- 系统可能需要一段时间才能适当扩大规模以满足增加的需求,或者在需求下降时缩小规模
Users+++++
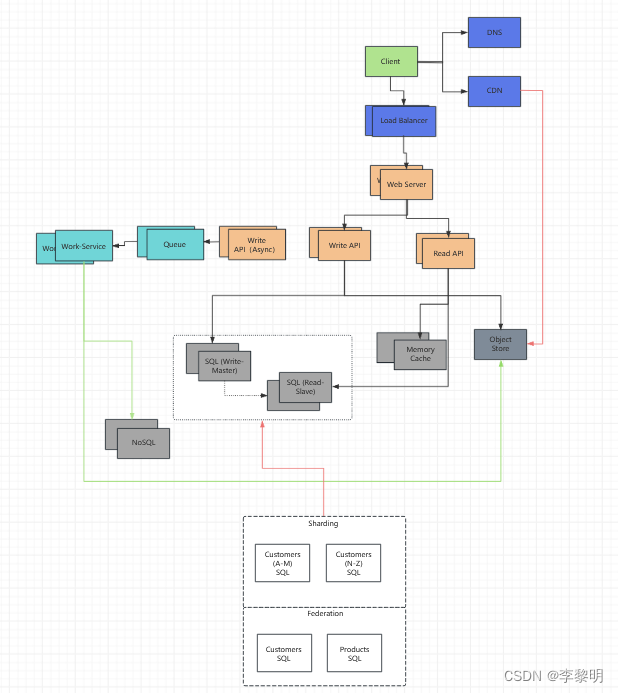
目标
- 如果我们的
MySQL Database开始增长的太大,我们或许可以考虑只是存储限制时间段的数据进数据库,当存储剩下的数据进数据仓库,比如 Redshift- 一个数据仓库,比如 Redshift可以很好的处理一个月1TB的新内容
- 伴随着 40000 读请求 / s, 针对受欢迎内容的读流量会被分散通过扩展内存,这也是非常有用的,去处理不不平衡的Traffic
SQL Read Replicas或许有问题处理机制(缓存问题),我们也可能需要添加额外的SQL 调度 pattenrs
- 平均400写请求/s 或许针对单个 SQL 主从架构,也需要检查是否有额外的扩展模式
SQL 扩展模式包含:
- Federation
- Sharding
- Denormalization
- SQL Tuning
为了进一步的处理高读和写请求,我们也应该考虑移除合适的数据进 NoSQL Database, 比如 DynamoDB
我们可以进一步拆分我们的 Application Server 去允许独立的扩展,批处理和计算(不需要被实时的做完),随着 Queue 和 Workers 异步:
- 例如,在照片服务中,照片上传和缩略图创建可以分开
- Client 上传 photo
- Application Server 放一个 job 进 Queue, 比如 SQS
- EC2 或 Lambda 上的 Worker Service 从队列中提取工作
- 创建一个缩略图
- 更新数据库
- 存储缩略图进
Object Store
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【产品应用】一体化伺服电机在管道检测机器人中的应用
- Analog-to-digital converter (ADC)
- 正则表达式-分组括号以及捕获分组
- 【浅谈】软件架构中轻量级与重量级的区别
- Dubbo的几个负载均衡类--最少活跃数
- C++面向对象语法总结(一)
- 开发模型和测试模型
- 手把手带安装水果编曲软件最版本是FL Studio 21.2.2.3914中文版
- Kafka Avro序列化之一:使用自定义序列化
- 整数和浮点数在内存中的存储