亚线性空间算法1
发布时间:2023年12月26日
流模型
问题:如果采用bit存储的话 可以是n或者是Logn 但是对于特别大的数据量 这也是不行的,所以我们思考是否有Loglogn的算法 来存储统计的数据。
问题1:近似计数Morris算法
- 多次实验 使结果更准确。


问题2:不重复元素/FM算法
-
?D 不重复元素的个数 m元素的值域是[0,m] n数据流中元素的个数
-
那么我们可以采用的第一种计数方式是类似于bitmap的方式记录元素存放的位置
-
第二种方式是我们维护一个集合,每个集合中的元素的大小是Logm 或者是logx具体取决于指派。


- 最后的估值大约是12-13?
- 因为哈希函数是随机的 所以我们得到的z值是随机的
- 下面是关于算法正确性的一点讨论
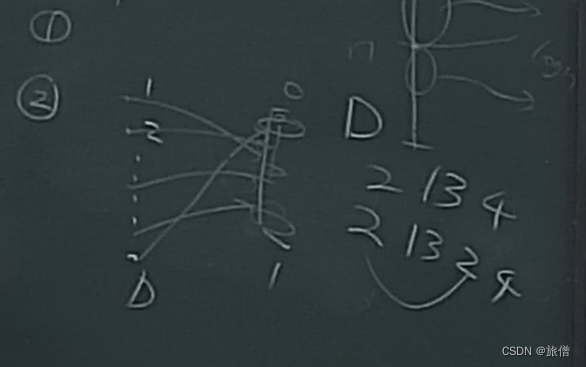
首先 右边的两种情况D是相同的 相当于哈希函数开了一个盲盒 最后的估值
只是取决于D和元素具体是什么没有关系
其次 D越大 越接近0的概率越大 因为他只要有个更小的那么他就一般很难进行更新了。问题3 :固定大小采样?
经典的水库抽样。 第二个证明略
有放回

 ?
?
文章来源:https://blog.csdn.net/qq_62260432/article/details/135027620
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【笑小枫】2023:岁月如歌,坚持与放弃的交织;2024:新的征程,希望与期望的绽放
- 给高中生的一些建议
- Qt通用属性工具:随心定义,随时可见(三)
- 【已解决】本地使用Git拉取代码的时候提示:master has no tracked branch的解决办法
- 智慧校园2.0物联网管理平台建设方案:PPT全文22页,附下载
- 测试工程师正遭【革命】,“点工”如何破局?
- 小程序OCR身份证识别
- Docker 如何在前端项目动态插入并使用变量
- ESP32-NOW(Arduino)
- GBASE南大通用CommandBuilder 属性