YOLOv3算法较YOLOv1及YOLOv2的区别
yoloV3以V1,V2为基础进行的改进,主要有:利用多尺度特征进行目标检测;先验框更丰富;调整了网络结构;对象分类使用logistic代替了softmax,更适用于多标签分类任务。
3.1算法简介
YOLOv3是YOLO (You Only Look Once)系列目标检测算法中的第三版,相比之前的算法,尤其是针对小目标,精度有显著提升。
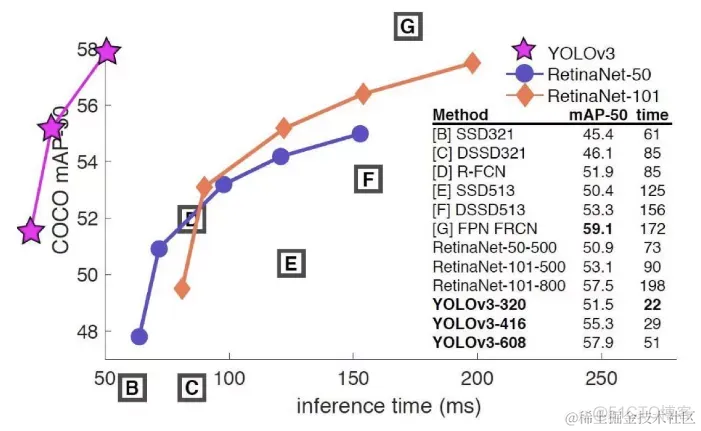
yoloV3的流程如下图所示,对于每一幅输入图像,YOLOv3会预测三个不同尺度的输出,目的是检测出不同大小的目标。
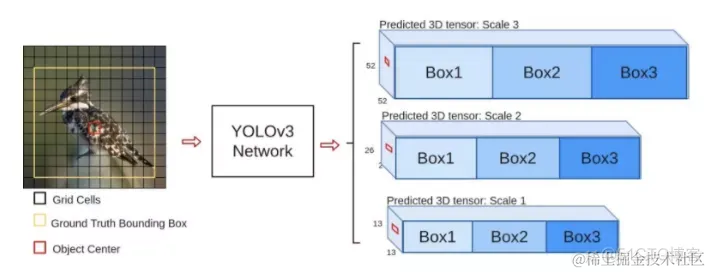
3.2多尺度检测
通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。因此,网络必须具备能够“看到”不同大小的物体的能力。因为网络越深,特征图就会越小,所以网络越深小的物体也就越难检测出来。
在实际的feature map中,随着网络深度的加深,浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。因此在不同级别的feature map对应不同的scale,所以我们可以在不同级别的特征图中进行目标检测。如下图展示了多种scale变换的经典方法。
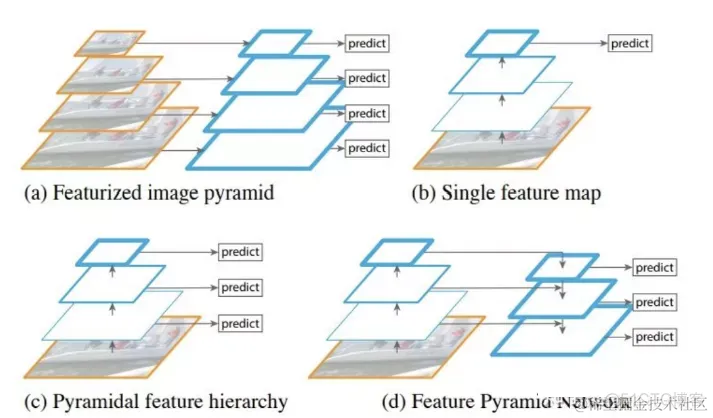
(a) 这种方法首先建立图像金字塔,不同尺度的金字塔图像被输入到对应的网络当中,用于不同scale物体的检测。但这样做的结果就是每个级别的金字塔都需要进行一次处理,速度很慢。
(b) 检测只在最后一层feature map阶段进行,这个结构无法检测不同大小的物体
? 对不同深度的feature map分别进行目标检测。SSD中采用的便是这样的结构。这样小的物体会在浅层的feature map中被检测出来,而大的物体会在深层的feature map被检测出来,从而达到对应不同scale的物体的目的,缺点是每一个feature map获得的信息仅来源于之前的层,之后的层的特征信息无法获取并加以利用。
(d) 与?很接近,但不同的是,当前层的feature map会对未来层的feature map进行上采样,并加以利用。因为有了这样一个结构,当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。在YOLOv3中,就是采用这种方式来实现目标多尺度的变换的。
3.3网络模型结构
在基本的图像特征提取方面,YOLO3采用了Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络ResNet的做法,在层之间设置了shortcut,来解决深层网络梯度的问题,shortcut如下图所示:包含两个卷积层和一个shortcut connections。

yoloV3的模型结构如下所示:整个v3结构里面,没有池化层和全连接层,网络的下采样是通过设置卷积的stride为2来达到的,每当通过这个卷积层之后图像的尺寸就会减小到一半。
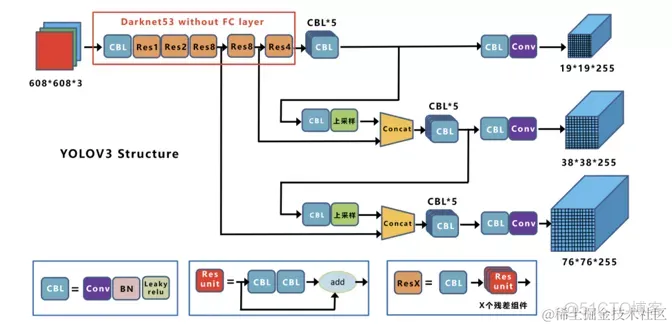
下面我们看下网络结构:
基本组件:蓝色方框内部分
1、CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。 2、Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。 3、ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作:
1、Concat:张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。
2、Add:张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。
Backbone中卷积层的数量:
每个ResX中包含1+2×X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2×1)+(1+2×2)+(1+2×8)+(1+2×8)+(1+2×4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,仍然把Yolov3的主干网络叫做Darknet53结构。
3.4先验框
yoloV3采用K-means聚类得到先验框的尺寸,为每种尺度设定3种先验框,总共聚类出9种尺寸的先验框。

在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。在最小的(13x13)特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的(26x26)特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的(52x52)特征图上(较小的感受野)应用,其中较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
直观上感受9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

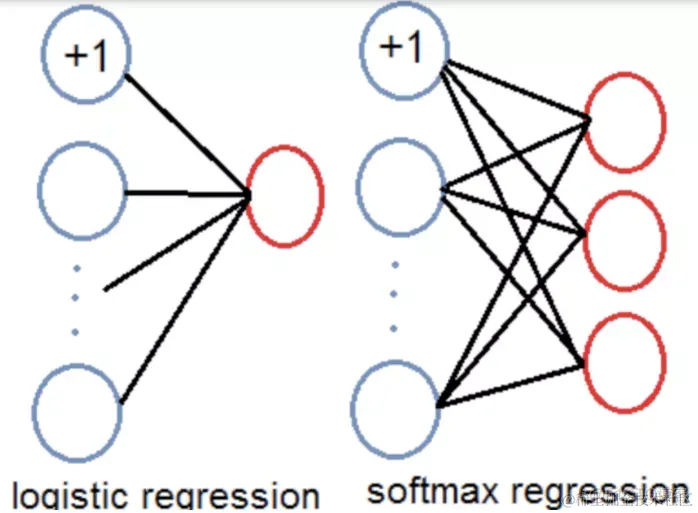
3.5 logistic回归
预测对象类别时不使用softmax,而是被替换为一个1x1的卷积层+logistic激活函数的结构。使用softmax层的时候其实已经假设每个输出仅对应某一个单个的class,但是在某些class存在重叠情况(例如woman和person)的数据集中,使用softmax就不能使网络对数据进行很好的预测。
3.6 yoloV3模型的输入与输出
YoloV3的输入输出形式如下图所示:

输入416×416×3的图像,通过darknet网络得到三种不同尺度的预测结果,每个尺度都对应N个通道,包含着预测的信息;
每个网格每个尺寸的anchors的预测结果。
YOLOv3共有13×13×3 + 26×26×3 + 52×52×3个预测 。每个预测对应85维,分别是4(坐标值)、1(置信度分数)、80(coco类别概率)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 设计模式——工厂模式
- C语言编译器(C语言编程软件)完全攻略
- 代码随想录算法训练营第32天 | 122.买卖股票的最佳时机II 55. 跳跃游戏 45.跳跃游戏II
- 分享一个基于easyui前端框架开发的后台管理系统模板
- ubuntu 20.04安装一系列软件
- 现代科技企业互动体验展厅如何设计
- Java项目:10 Springboot的电商书城管理系统
- Linux查找命令(which命令、find命令)
- python数字图像处理基础(十)——背景建模
- 【开源】基于JAVA的河南软件客服系统