偷偷称为一名炼丹师、掌握核心参数然后惊艳所有人!
Part0 学习思路
只有非常小的一部分核心参数会对训练产生比较大的影响,我们只需要学习那非常小的一部分就好
-
参数有很多, 不是每个都要填,可以默认留空
-
选择参数预设时,部分没用的参数会自动隐藏
Part 1 LoRA的类型
疑问:LoRA不就是一种类型吗
LoRA确实是一种模型,但在LoRA最初被发掘之后,有很多开发者在此基础之上对算法进行不断地改进,开发出很多改良模型可以实现更好的训练
杰出贡献者及其对应类型
琥珀青葉提出的LyCORIS方法—“LoRA除常规方法外的其他秩自适应实现”
其中Standard、LoCon、LoHa、LoKr、IA3等方法,它们在训练的灵活性、多样性与还原性上有些许差异
-
Standard——拿不准选择哪个模型的不二之选,传统LoRA,容错率高
-
LoCon——第二个选择,其加入卷积层控制,被广泛认为可以对训练集细节有更好的还原,速度较慢
-
IA3——简单尝试、对质量要求不“强”、希望有较快速度
各种算法各有所长,如有需要可根据青葉老师的指引认真选择自己需要的训练类型,除此之外也有一些由训练结果的来的经验,比如LoHa、LoKR更擅长训练画风且面对多概念训练时会更有优势、但在单一训练集上优势并不大
Part2 LoRA的训练步长
用来决定训练“时间”,其核心时间计量单位为“步”,而不是平时所使用的“时”、“分”、“秒”
“一步”——对训练集里的一张图片做了一次学习(ai通过不断根据训练标注生成图片、和训练集中的某一张图片做对比来验证像不像并以他们的差异进行微调进而嵌入向量)
“轮次(Epoch)”——每走完一个Epoch的步数称为一个“Epoch”,1个Epoch的步数=训练集图片数*重复数(Reoeat)
“总步长”——步长=轮次数*每个轮次的步长
-
假如训练集中有三十张图片,将训练集中的图片全部学习一次就需要进行30步的训练
-
但是往往我们将ai对每张图片的学习次数不设置为一,我们将对每张图片的学习次数定义为“重复次数”,当我们将“重复次数”设置为6时,学习完所有图片需要走的步数就是30*6=180步
打个比方,把炼模型比作烧菜,那么总步长就是烧菜的时间,时间短了,菜就不熟,时间长了,菜就有烧糊的风险;所以对训练步长的尝试和探索是我们研究的重点之一
人物训练场景之下、根据以往训练而得出的训练步长的设置经验:
-
训练集数量在20~30张,设置为1200~1500会得到较好的结果
我们又如何控制最终步长的范围
-
通过Epoch数量的设置进行控制,即总步长=轮次数*每个轮次的步长
-
设置一个很大的轮次数(不可能执行完,结果全看后面设置的最大步数进行控制),然后通过设置“最大步数”和“最大轮次数”设置它训练到一定程度自动停止
-
通过设置每隔n轮进行保存可以根据每n轮训练结果控制生成对应的文件
-
-
批次处理数量(batch size),每次学习多少张图片可以缩短训练总步长,适当提高batch size,可能会提高ai消化特征的效率,对应的微调精度可能会略微下降
Part3 学习率(Learning Rate)
“学习率”即ai学习这些训练集图片的强度,与训练步长紧密相关,学习率越高,ai越能“学得进去”
默认值为0.0001
为什么不把学习率直接拉满
同样使用做饭的例子
步长是做饭的时间,学习率就是做饭的火候,要“小火慢炖”,时刻提防饭菜做糊的风险
过拟合
在机器学习中,这种状态有种更专业的称呼——“过拟合”
AI过于紧密或精确地匹配训练用的数据集,导致它无法良好地根据新的数据生成新的结果
通俗点讲就是“过载”,处理不过来,然后乱处理一通
在LoRA中的体现就是不光把该学地学了,不该学的也学了进去,诸如“画风”、“色调”等,把学习率设置为小数点后那么多位就是为了防止“过拟合”
欠拟合
相较于“过拟合”这种高发事件,“欠拟合”出现的机率就小得多
因为一般LoRA训练都会产生拟合
学习率与步长的关系
如果学习率偏高,那么ai可能一学就会,相应不需要那么多步长
学习率偏低,ai就可能需要更多的步长才能学会
以此往复,经过多次训练,不断尝试出最佳的方案
学习率与训练批次的关系
目前最流行的说法来看,训练批次增大,学习率同样需要增高
当一次处理的图片增多时,ai需要学习的内容增多,学习率也需要对应增高
LyCORIS创始者青葉老师提出意见,除非训练批次增加到原来的十几倍,没有必要可以改变学习率
当一次处理的图片增多时,学习率也需要对应增高
文本编码器学习率和Unet学习率
对应的就是“文本编码器”和“噪声预测器”
文本编码器对学习率的敏感度远高于噪声预测器,通常我们将文本编码器学习率设置为Unet的二分之一到十分之一
Part4 优化器(Optimizer)
与学习率密切相关,与出图过程中的的采样方法一样
决定AI如何在这个过程把控学习的方式
虽然优化器众多,但是平常会使用到的只有其中的2-3个:
-
AdamWBit:机器学习领域非常著名的老牌优化器、效果稳健、默认学习率为1e-4
-
Lion:新的机器学习优化器,理论上更加“先进”,其最佳学习率比AdamW小约十倍并且在大Batch Size下表现优秀
-
Prodigy:无参数自适应学习率方法(由青龙老师贡献)就像一个无师自通的神童,只需要将刚刚提到的三个学习率都设置为1,优化器就会在接下来的学习过程中自动改变学习率来取得最佳效果
青龙圣者老师B站账号:青龙圣者的个人空间-青龙圣者个人主页-哔哩哔哩视频
调度器
调度器——主导学习率衰减
-
为了保证更好的学习效果并在后期避免过拟合、学习率随时间衰减,
-
用我们学习事务的角度来看,在我们刚开始接触新事物时需要多记多背,到后期就不需要耗费那么多的精力
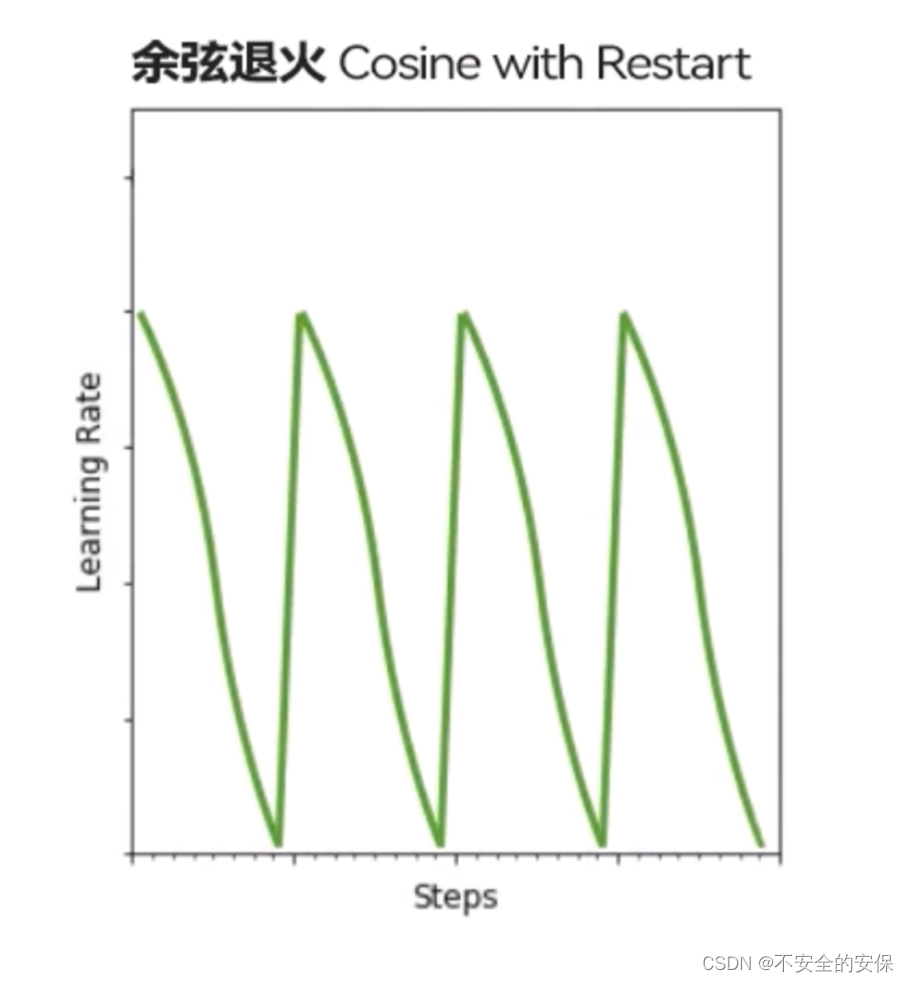
在很多时候其对模型训练的影响是微乎其微的,我们按照经验设置为余弦函数或者余弦函数的升级版——“余弦退火”(带重启的余弦函数学习率的方法)
如果设置为余弦退火,将重启次数设置为3~5次才会起效,当训练对象复杂时可以是量增大他
Part5 网络维度(Network Rank&Alpha)
即为LoRA模型的维度,体现在以下两个参数上
-
Network Rank(理论最大值为128):rank越高从原始矩阵里抽出的行列就越多->微调的数据量就越多->容纳更复杂的概念->LoRA模型的大小
-
在训练一些较为复杂的画风或者三次元物品、形象时才会用到高秩(128、68)
-
训练二次元人物等复杂度较低的物品时使用低秩(32、16、8)即可
-
维度过高可能会带来的结果是学习“太深”,同样会导致类似过拟合状况的出现
-
在实际训练中,推荐从合理范围内比较低的rank试起
-
-
Network Alpha:
-
可以把Alpha看做是一个用来调节LoRA对原模型影响作用的参数
-
Alpha和Rank的比值是我们使用LoRA时的“减弱权重”程度
-
换句话说Alpha越接近Rank则LoRA对原模型权重的影响越小、越接近0则LoRA对权重的微调作用越显著
-
实际操作中通常将Alpha设置为Rank的一半、也可以将其设置为1,使微调模型发挥最大作用
-
LoRA模型带有对卷积层的控制时
如选择LoCon和LoHa等带有对卷积层(Convolution)的控制的LoRA类型时
-
在原有的rank和alpha的基础上还会额外出现两个卷积层的Rank和Alpha设置,其逻辑与普通的rank和alpha相同
-
初学阶段留白即可,其会自动将上面两个rank和alpha数值代入卷积层进行训练

Part6 训练性能(Performance)
“混合精度”(Mix Precision)与“保存精度”(Save Precision)
对训练速度起到决定性因素的选项——“混合精度”(Mix Precision)与“保存精度”(Save Precision)
均有三个预设选项:

-
无->选择默认格式进行读写
-
fp16(floating points):对于有编程经验的小伙伴想必对单精度浮点数再熟悉不过了,这里意思相通,fp32为单精度、fp16则为半精度,用来表示数值类型,会极大的提升计算速度并且节约大量显存
-
在计算机科学中,浮点(英语:floating point,缩写为FP)是一种对于实数的近似值数值表现法,由一个有效数字(即尾数)加上幂数来表示,通常是乘以某个基数的整数次指数得到。以这种表示法表示的数值,称为浮点数(floating-point number)。利用浮点进行运算,称为浮点计算,这种运算通常伴随着因为无法精确表示而进行的近似或舍入。
-
bf16(Brain Floating Point)是一种fp16的变种,理论上比fp16更稳定,是更好的选择,他们的差异比fp32和fp16之间还小,几乎可以忽略不计
“缓存潜空间图像”和“缓存潜空间图像到磁盘”
还有两个与性能直接相关的参数“缓存潜空间图像”和“缓存潜空间图像到磁盘”
-
无论是否开启“缓存潜变量”、ai在训练时都会自动将训练集图片变成潜空间向量
-
不开启,就是在训练过程中一张一张地转化,会拖慢训练速度
-
开启,会在开始训练前一次性把所有图片缓存到显存中然后反复调用
-
多数时推荐开启,对训练速度地提升很有帮助
-
-
“缓存潜变量到磁盘”就是将潜变量同时保存到本地地硬盘中-方便使用同一批训练集反复训练,省省去了反复加载地过程

进阶参数——交叉注意力(Cross Attention)
深度学习中的学习机制,可以提高模型训练和推理的效率
如果使用n卡,这里开启“xformers”可以降低训练过程中的显存需求并显著提高速度
内存高效注意力
如果选中此选项,则会抑制VRAM使用并执行注意力块处理。它比下一个
选项"xformers"慢。如果您没有足够的VRAM,请将其打开。
其会压缩一定量的显存使用,低配用户可以考虑借此降爆显存风险
相较于xformers效果不显著并且使速度变慢的幅度大
PS:现存够用时,推荐关闭
Part7 可能出现问题及其对应解决方法
过拟合怎么办
-
适当降低学习率
-
缩短学习步长(或取较早轮次结果)
-
降低Rank,提高Alpha
-
减小Repeat!数值
-
使用正则化训练
欠拟合怎么办
-
适当提高学习率
-
延长学习步长(或取较后轮次结果)
-
提高Rank,降低Alpha
-
增大Repeat数值
其他问题怎么办
-
更换LoRA类型
-
尝试另一种优化器/调度器
-
对训练集做调整
-
......
学习资料:60分钟速通LORA训练!绝对是你看过最好懂的AI绘画模型训练教程!StableDiffusion超详细训练原理讲解+实操教学,LORA参数详解与训练集处理技巧_哔哩哔哩_bilibili
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【深度学习】动手学深度学习(PyTorch版)李沐 2.4.3 梯度【公式推导】
- 西软云XMS 反序列化RCE漏洞复现
- 安装Hadoop 3.3.5
- ELK日志收集平台部署(4)
- 1.redhat网卡配置
- 【JAVA GUI+MYSQL]社团信息管理系统
- Kubernets(K8S)启动和运行 01-01 Kubernetes简介
- swing快速入门(七)
- 4.docker镜像及相关命令
- 阿里终面:10亿数据如何快速插入MySQL?