YOLOv8改进 | 注意力篇 | ACmix自注意力与卷积混合模型(提高FPS+检测效率)
一、本文介绍
本文给大家带来的改进机制是ACmix自注意力机制的改进版本,它的核心思想是,传统卷积操作和自注意力模块的大部分计算都可以通过1x1的卷积来实现。ACmix首先使用1x1卷积对输入特征图进行投影,生成一组中间特征,然后根据不同的范式,即自注意力和卷积方式,分别重用和聚合这些中间特征。这样,ACmix既能利用自注意力的全局感知能力,又能通过卷积捕获局部特征,从而在保持较低计算成本的同时,提高模型的性能。
推荐指数:????
涨点效果:????
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备????
训练结果对比图->?
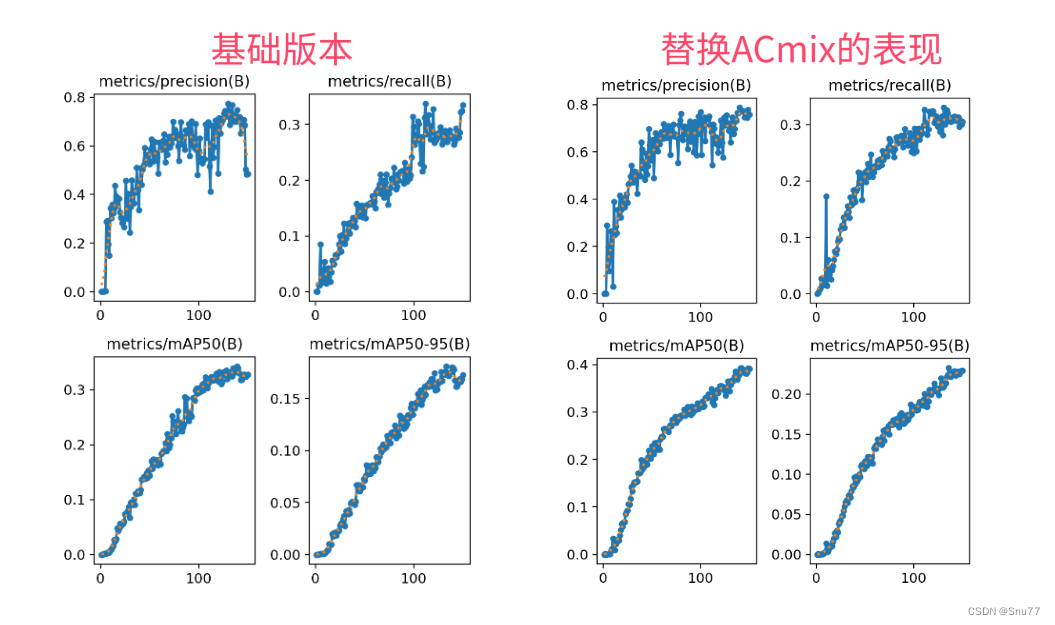 ?
?
目录
二、ACmix的框架原理
 ?
?
官方论文地址:官方论文地址
官方代码地址:官方代码地址
 ?
?
2.1 ACMix的基本原理?
ACmix是一种混合模型,结合了自注意力机制和卷积运算的优势。它的核心思想是,传统卷积操作和自注意力模块的大部分计算都可以通过1x1的卷积来实现。ACmix首先使用1x1卷积对输入特征图进行投影,生成一组中间特征,然后根据不同的范式,即自注意力和卷积方式,分别重用和聚合这些中间特征。这样,ACmix既能利用自注意力的全局感知能力,又能通过卷积捕获局部特征,从而在保持较低计算成本的同时,提高模型的性能。
ACmix模型的主要改进机制可以分为以下两点:
1. 自注意力和卷积的整合:将自注意力和卷积技术融合,实现两者优势的结合。
2. 运算分解与重构:通过分解自注意力和卷积中的运算,重构为1×1卷积形式,提高了运算效率。
2.1.1 自注意力和卷积的整合
文章中指出,自注意力和卷积的整合通过以下方式实现:
特征分解:自注意力机制的查询(query)、键(key)、值(value)与卷积操作通过1x1卷积进行特征分解。
运算共享:卷积和自注意力共享相同的1x1卷积运算,减少了重复的计算量。
特征融合:在ACmix模型中,卷积和自注意力生成的特征通过求和操作进行融合,加强了模型的特征提取能力。
模块化设计:通过模块化设计,ACmix可以灵活地嵌入到不同的网络结构中,增强网络的表征能力。
 ?
?
这张图片展示了ACmix中的主要概念,它比较了卷积、自注意力和ACmix各自的结构和计算复杂度。图中:
(a) 卷积:展示了标准卷积操作,包含一个的1x1卷积,表示卷积核大小和卷积操作的聚合。
(b) 自注意力:展示了自注意力机制,它包含三个头部的1x1卷积,代表多头注意力机制中每个头部的线性变换,以及自注意力聚合。
(c) ACmix(我们的方法):结合了卷积和自注意力聚合,其中1x1卷积在两者之间共享,旨在减少计算开销并整合轻量级的聚合操作。
整体上,ACmix旨在通过共享计算资源(1x1卷积)并结合两种不同的聚合操作,以优化特征通道上的计算复杂度。
2.1.2 运算分解与重构
在ACmix中,运算分解与重构的概念是指将传统的卷积运算和自注意力运算拆分,并重新构建为更高效的形式。这主要通过以下步骤实现:
分解卷积和自注意力:将标准的卷积核分解成多个1×1卷积核,每个核处理不同的特征子集,同时将自注意力机制中的查询(query)、键(key)和值(value)的生成也转换为1×1卷积操作。
重构为混合模块:将分解后的卷积和自注意力运算重构成一个统一的混合模块,既包含了卷积的空间特征提取能力,也融入了自注意力的全局信息聚合功能。
提高运算效率:这种分解与重构的方法减少了冗余计算,提高了运算效率,同时降低了模型的复杂度。
 ?
?
这张图片展示了ACmix提出的混合模块的结构。图示包含了:
(a) 卷积:3x3卷积通过1x1卷积的方式被分解,展示了特征图的转换过程。
(b)自注意力:输入特征先转换成查询(query)、键(key)和值(value),使用1x1卷积实现,并通过相似度匹配计算注意力权重。
(c) ACmix:结合了(a)和(b)的特点,在第一阶段使用三个1x1卷积对输入特征图进行投影,在第二阶段将两种路径得到的特征相加,作为最终输出。
右图显示了ACmix模块的流程,强调了两种机制的融合并提供了每个操作块的计算复杂度。
三、ACmix的核心代码?
该代码本身存在一个bug,会导致验证的适合报类型不匹配的错误,我将其进行了解决,这也是一个读者和我说的想要帮忙解决一下这个问题困扰了他很久。?
import torch
import torch.nn as nn
def position(H, W, type, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1).to(type)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W).to(type)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3 * self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes,
kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1,
stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i // self.kernel_conv, i % self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h // self.stride, w // self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.dtype, x.is_cuda))
q_att = q.view(b * self.head, self.head_dim, h, w) * scaling
k_att = k.view(b * self.head, self.head_dim, h, w)
v_att = v.view(b * self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b * self.head, self.head_dim,
self.kernel_att * self.kernel_att, h_out,
w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att * self.kernel_att, h_out,
w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2) * (unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(
1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b * self.head, self.head_dim, self.kernel_att * self.kernel_att,
h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat(
[q.view(b, self.head, self.head_dim, h * w), k.view(b, self.head, self.head_dim, h * w),
v.view(b, self.head, self.head_dim, h * w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 24, 224, 224)
image = torch.rand(*image_size)
# Model
mobilenet_v1 = ACmix(24, 24)
out = mobilenet_v1(image)
print(out)四、手把手教你添加ACmix
4.1?ACmix添加步骤
4.1.1 步骤一
首先我们找到如下的目录'ultralytics/nn/modules',然后在这个目录下创建一个py文件,名字可以根据你自己的习惯起,然后将ACmix的核心代码复制进去。
4.1.2 步骤二
之后我们找到'ultralytics/nn/tasks.py'文件,在其中注册我们的ACmix模块。
首先我们需要在文件的开头导入我们的ACmix模块,如下图所示->
 ??
??
4.1.3 步骤三
我们找到parse_model这个方法,可以用搜索也可以自己手动找,大概在六百多行吧。?我们找到如下的地方,然后将ACmix添加进去即可,模仿我添加即可。
 ??
??
elif m in {ACmix}:
args = [ch[f], ch[f]]
到此我们就注册成功了,可以修改yaml文件中输入ACmix使用这个模块了。
五、ACmix的yaml文件和运行记录
下面推荐几个版本的yaml文件给大家,大家可以复制进行训练,但是组合用很多具体那种最有效果都不一定,针对不同的数据集效果也不一样,我不可每一种都做实验,所以我下面推荐了几种我自己认为可能有效果的配合方式,你也可以自己进行组合。
5.1 ACMix的yaml版本一(推荐)
下面的添加ACMix是我实验结果的版本,我仅在大目标检测层的输出添加了一个ACMix模块,就涨点了0.05左右,所以大家可以在中等和小目标检测层都添加ACMix模块进行尝试,下面的yaml文件我会给大家推荐。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, ACmix, []] # 16
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, ACmix, []] # 20
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [-1, 1, ACmix, []] # 24
- [[16, 20, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
5.2 ACMix的yaml版本二
添加的版本二具体那种适合你需要大家自己多做实验来尝试。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 1, ACmix, []] # 22
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
5.3 推荐ACMix可添加的位置?
ACMix是一种即插即用的可替换卷积的模块,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入ACMix。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加ACMix可以帮助模型更有效地融合不同层次的特征(yaml文件一和二)。
Backbone:可以替换中干网络中的卷积部分
能添加的位置很多,一篇文章很难全部介绍到,后期我会发文件里面集成上百种的改进机制,然后还有许多融合模块,给大家。
5.4 ACMix的训练过程截图?
下面是添加了ACMix的训练截图。
大家可以看下面的运行结果和添加的位置所以不存在我发的代码不全或者运行不了的问题大家有问题也可以在评论区评论我看到都会为大家解答(我知道的)。
 ??
??
???
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
 ???
???
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机网络实验二:Packet Tracer的简单使用
- S1-11 定时器
- new mars3d.graphic.PolygonEntity({计算平面几何中心点及贴地效果展示
- Hotspot源码解析-第十六章-代码缓存空间初始化
- KY89 坠落的蚂蚁
- 设计模式-责任链模式
- Windows自带分屏使用-窗口贴靠
- vue3目录结构详细说明及文件命名规范
- itk中互信息配准二维图像(仅平移)
- 关于接口的安全性测试,这方法你学会了吗?