linux SHELL语句
发布时间:2023年12月28日
shell编程
shell编程
一、初识shell
- 程序 语言 编程
- 语言
- 自然语言
- 汉语 英语
- 计算机语言
- c语言
- c++
- java php python go shell
- 编译型语言 c c++ java
- 解释型语言 php python bash (不能闭源,开发难度低)
- 自然语言
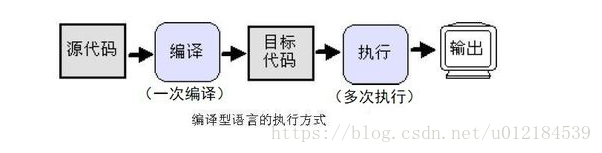
编译型语言:运行编译型语言是相对于解释型语言存在的,编译型语言的首先将源代码编译生成机器语言,再由机器运行机 器码(二进制)。像C/C++等都是编译型语言。
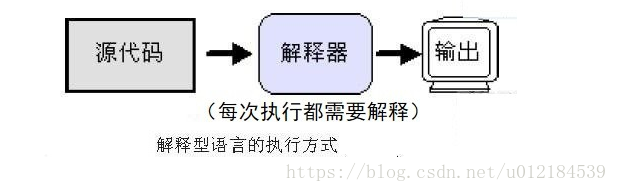
解释型语言:相对于编译型语言存在的,源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码 进行解释运行。比如Python/JavaScript / Perl /Shell等都是解释型语言
c 编译型执行 代码需要编译成cpu能认识的二进制码 x86指令集
java 编译型执行 , 编译-->字节码,cpu不能直接运行,只能被Java虚拟机执行
shell 解释型执行 慢
shell 定义
Shell 也是一种程序设计语言,它有变量,关键字,各种控制语句,有自己的语法结构,利用shell程序设计语 可以编写功能很强、代码简短的程序
#! Shebang 定义解释器
shell的分类和切换
[root@newrain ~]# cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/usr/bin/sh
/usr/bin/bash
/usr/sbin/nologin
默认shell: bash shell
centos中脚本使用的默认shell 为/usr/bin/sh
查看当前正在使用的shell
echo $SHELL
shell 的切换
vim /etc/passwd 编辑登录shell
使用场景
什么时候不适合使用Shell编程:
1. 资源紧张的项目,特别是那些速度是重要因素的地方(排序,散序,等等)
2. 程序要进行很复杂的数学计算,特别是浮点计算,任意精度的计算,或者是复数计算
3. 要求交叉编译平台的可移植性(使用C或者是Java代替)
4. 需要结构化编程的复杂应用(需要变量类型检查和函数原型等等)
5. 对于影响系统全局性的关键任务应用。
6. 安全非常重要。你必须保证系统完整性和抵抗入侵,攻击和恶意破坏。
7. 项目由连串的依赖的各个部分组成。
8. 多种文件操作要求(Bash被限制成文件顺序存取,并且是以相当笨拙,效率低下的逐行的存取方式) 9. 需要良好的多维数组支持。
10. 需要类似链表或树这样的数据结构。
11. 需要产生或操作图象或图形用户界面。
12. 需要直接存取系统硬件。
13. 需要端口号或是socket I/O。
14. 需要使用可重用的函数库或接口。
15. 所有的私有的不开源的应用程序(Shell脚本的源代码是直接可读,能被所有人看到的)
如果你需要有上面的任意一种应用,请考虑其他的更强大的脚本语言――Perl,Tcl,Python,Ruby,或者可能是其他更 高级的编译型语言,例如C,C++或者是Java
Shell 能做什么?
1. 自动化批量系统初始化程序 (update,软件安装,时区设置,安全策略...)
2. 自动化批量软件部署程序 (LAMP,LNMP,Tomcat,LVS,Nginx)
3. 应用管理程序 (KVM,集群管理扩容,MySQL,DELLR720批量RAID)
4. 日志分析处理程序(PV, UV, 200, !200, top 100, grep/awk)
5. 自动化备份恢复程序(MySQL完全备份/增量 + Crond)
6. 自动化管理程序(批量远程修改密码,软件升级,配置更新)
7. 自动化信息采集及监控程序(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL) 8. 配合Zabbix信息采集(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL)
8. 自动化扩容(增加云主机——>业务上线)
zabbix监控CPU 80%+|-50% Python API AWS/EC2(增加/删除云主机) + Shell Script(业务上 线)
9. 俄罗斯方块,打印三角形,打印圣诞树,打印五角星,运行小火车,坦克大战,排序实现
10. Shell可以做任何运维的事情(一切取决于业务需求)
shell 特性回顾
- shell常见元素
文件描述符与输出重定向:
在 shell 程式中,最常使用的 FD (file descriptor) 大概有三个, 分别是:
0: Standard Input (STDIN)
1: Standard Output (STDOUT)
2: Standard Error Output (STDERR)
在标准情况下, 这些FD分别跟如下设备关联:
stdin(0): keyboard 键盘输入,并返回在前端
stdout(1): monitor 正确返回值 输出到前端
stderr(2): monitor 错误返回值 输出到前端
>a.txt
1>a.txt
2>a.txt
&>a.txt
1>&2
2>&1
一般来说, "1>" 通常可以省略成 ">".
1>&2 正确输出传递给错误的通道 &2表示2输出通道,之前如果有定义标准错误重定向到某log文件,那么标准输出也重 定向到这个log文件,如果此处错写成 1>2, 就表示把1输出重定向到文件2中.
2>&1 错误输出传递给正确的通道, 同样&1表示1输出通道.
例子. 当前目录下只有a.txt,没有b.txt
[root@redhat box]# ls a.txt b.txt 1>file.out 2>&1
[root@redhat box]# cat file.out
ls: b.txt: No such file or directory
a.txt
现在, 正确的输出和错误的输出都定向到了file.out这个文件中, 而不显示在前端 =================================
[root@redhat tmp]# cat >> b.txt << !
> ni hao a hahafvs
>!
[root@redhat tmp]# cat b.txt
ni hao a haha
bash 初始化
用户登录时相关的bash配置文件 (登录脚本)
全局配置文件
/etc/profile
/etc/profile.d/*.sh
/etc/bashrc
个人配置文件
~/.bash_profile
~/.bashrc
profile类的文件: 设定环境变量
运行命令或脚本
bashrc类的文件:
定义命令别名
用户登录时加载bash配置文件的过程
登录式shell加载配置文件过程
~/.bash_profile --> ~/.bashrc --> /etc/bashrc --> /etc/profile --> /etc/profile.d/*.sh
非登录式shell加载配置文件过程
~/.bashrc --> /etc/bashrc --> /etc/profile.d/*.sh
用户的初始化脚本
环境变量 修饰用户工作环境变量
这些文件为系统的每个用户设置环境信息Shell设置文件:
/etc/profile(系统级)启动时执行
这是系统最主要的shell设置文件,也是用户登陆时系统最先检查的文件,有关重要的环境变量都定义在此,其中包括 PATH,USER,LOGNAME,MAIL,HOSTNAME,HISTSIZE,INPUTRC等。而在文件的最后,它会检查并执 行/etc/profile.d/*.sh的脚本。
~/.bash_profile(用户级)离开时执行
这个文件是每位用户的bash环境设置文件,它存在与于用户的主目录中,当系统执行/etc/profile 后,就会接着读取此 文件内的设置值。在此文件中会定义USERNAME,BASH_ENV和PATH等环境变量,但是此处的PATH除了包含系统的$PATH变 量外加入用户的“bin”目录路径.
~/.bashrc(用户级)离开时执行
接下来系统会检查~.bashrc文件,这个文件和前两个文件(/etc/profile 和~.bash_profile)最大的不同是,每次 执行bash时,~.bashrc都会被再次读取,也就是变量会再次地设置,而/etc/profile,~./bash_profile只有在登陆 时才读取。就是因为要经常的读取,所以~/.bashrc文件只定义一些终端机设置以及shell提示符号等功能,而不是定义环 境变量。
~/.bash_login(用户级)离开时执行
如果~.bash_profile文件不存在,则系统会转而读取~.bash_login这个文件内容。这是用户的登陆文件,在每次用户登 陆系统时,bash都会读此内容,所以通常都会将登陆后必须执行的命令放在这个文件中。
~/.bash_logout 离开时执行 如果想在注销shell前执行一些工作,都可以在此文件中设置。 例如:
#vi ~/.bash_logout
clear
仅执行一个clear命令在你注销的时候
~/.bash_history(用户级)
这个文件会记录用户先前使用的历史命令。
vim /etc/profile.d/history.sh
wget http://download.jhyeliu.xyz/os/get-cmd-history.sh
-
图形模式登录时,顺序读取:/etc/profile 和 ~/.profile
-
图形模式登录后,打开终端时,顺序读取:/etc/bash.bashrc 和 ~/.bashrc
-
文本模式登录时,顺序读取:/etc/bash.bashrc,/etc/profile 和 ~/.bash_profile
-
从其它用户 su 到该用户,则分两种情况:
- 如果带 -l 参数(或-参数,–login 参数),如:su -l username,则 bash 是 login 的,它将顺序读取以下配置文件:/etc/bash.bashrc,/etc/profile 和~/.bash_profile。
- 如果没有带 -l 参数,则 bash 是 non-login 的,它将顺序读取:/etc/bash.bashrc 和 ~/.bashrc
-
注销时,或退出 su 登录的用户,如果是 longin 方式,那么 bash 会读取:~/.bash_logout
- 执行自定义的 Shell 文件时,若使用 bash -l a.sh 的方式,则 bash 会读取行:/etc/profile 和 ~/.bash_profile,若使用其它方式,如:bash a.sh,./a.sh,sh a.sh(这个不属于bash Shell),则不会读取上面的任何文件。
- 上面的例子凡是读取到 ~/.bash_profile 的,若该文件不存在,则读取 ~/.bash_login,若前两者不存在,读取 ~/.profile。
-
bash shell 特性
补全 bash-completion # 增加补全
历史 history
vim /etc/profile
export HISTTIMEFORMAT="[%Y.%m.%d %H:%M:%S] "
别名 alias
快捷键 ^+a ^+e ^+r
前后台作业 bg fg nohup忽略退出信号
重定向
管道 ls ./ | xargs -i cp {} /tmp
命令排序执行
; && ||
; 命令分割,在一行中执行多条语句
&& 一行中执行多条语句,前成功后面再执行
|| 一行中执行多条语句,前面不成功,后面再执行
systemctl status firewalld &>/dev/null && echo "防火墙正在运行中" || echo "防火墙已关闭"
通配符
{} ? *
正则表达式 脚本
echo {1..10}
ls ?.sh
ls *.sh
- 历史命令
查看历史命令
history
vim /etc/profile 下的historysize 可以修改
用途:用于安全加固
调用历史命令
上下健
!关键字
!历史命令行号
!! 执行上一条命令
!$ 上一条命令的最后一个参数
esc . 上一条命令的最后一个参数
Ctrl+r 在历史命令中查找,输入关键字调出之前的命令
关键字+pgup/phdn 可以切换关键字相关的历史命令
别名
查看别名
alias
设置别名
临时设置
# aa=88
# echo $aa
永久设置
# vim /root/.bashrc
小小技巧:显示历史命令执行时间
1.设置变量:
HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S"
2.再次执行history查看结果
- Bash 部分快捷键
Ctrl+a 切换到命令行开始(跟home一样,但是home在某些unix环境下无法使用)
Ctrl+e 切换到命令行末尾
Ctrl+u 清除剪切光标之前的内容
Ctrl+k 清除剪切光标之后的内容
ctrl+y 粘贴刚才所删除的字符
Ctrl+r 在历史命令中查找,输入关键字调出之前的命令
- 通配符置换
在 Shell命令中,通常会使用通配符表达式来匹配一些文件
*,?,[],{}
例:
字符 含义 实例
* 匹配 0 或多个字符 a*b a与b之间可以有任意长度的任意字符, 也可以一个也没有, 如aabcb, axyzb, a012b, ab。
? 匹配任意一个字符 a?b a与b之间必须也只能有一个字符, 可以是任意字符, 如aab, abb, acb, a0b。
[list] 匹配 list 中的任意单一字符 a[xyz]b a与b之间必须也只能有一个字符, 但只能是 x 或 y 或 z, 如: axb, ayb, azb。
[!list] 匹配 除list 中的任意单一字符 a[!0-9]b a与b之间必须也只能有一个字符, 但不能是阿 拉伯数字, 如axb, aab, a-b。
[c1-c2] 匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z] a[0-9]b 0与9之间必须也只能有一个字符 如a0b, a1b... a9b。
{string1,string2,...} 匹配 sring1 或 string2 (或更多)其一字符串 a{abc,xyz,123}b a与b之间只 能是abc或xyz或123这三个字符串之一。
[root@newrain tmp]# rm -rf /tmp/*
[root@newrain tmp]# touch aabcb axyzb a012b ab acb
[root@newrain tmp]# ls
a012b aabcb ab axyzb acb
[root@newrain tmp]# ls a*b
a012b aabcb ab axyzb acb
[root@newrain tmp]# ls a?b
acb
[root@newrain tmp]# rm -rf /tmp/*
[root@newrain tmp]# touch axb ayb azb axyb
[root@newrain tmp]# ls
axb ayb azb
[root@newrain tmp]# ls a[xy]b
axb ayb
[root@newrain tmp]# ls a[!xy]b
azb
[root@newrain tmp]# ls a[!x]b
ayb azb
[root@newrain tmp]# rm -rf /tmp/*
[root@newrain tmp]# touch a0b a1b a9b
[root@newrain tmp]# ls a[0-9]b
a0b a1b a9b
[root@newrain tmp]# rm -rf /tmp/*
[root@newrain tmp]# touch aabcb axyzb a012b ab
[root@newrain tmp]# ls a{abc}b
ls: cannot access a{abc}b: No such file or directory
[root@newrain tmp]# ls a{abc,xyz}b
aabcb axyzb
[root@newrain tmp]# ls a{abc,xyz,012}b
a012b aabcb axyzb
二、shell 脚本规范
[root@newrain ~]# vim helloworld.sh ---.sh代表这个文件是个shell脚本,第一个原因,让别人认的这个是shell脚本,sh后缀有高亮显示。
拓展名后缀,如果省略.sh则不易判断该文件是否为shell脚本
1. #!/usr/bin/env bash ---shebang蛇棒, 解释器, 翻译
2. #
3. #
3. # Author: newrain
4. # Email: newrain@163.com ---这就是注释, 你没看错
5. # Github: https://github.com/newrain001
6. # Date: 2019/**/**
7. printf "hello world\n"
功能说明:打印hello world
[root@newrain ~]# sh helloworld.sh
hello world
[root@newrain ~]# chmod +x helloworld.sh
[root@newrain ~]# ./helloworld.sh
[root@newrain tmp]# /tmp/helloworld.sh
hello world
# 执行脚本方式
1、 sh 脚本.sh
2、 bash 脚本.sh
3、 ./脚本.sh # 需要执行权限
4、 . 脚本.sh
5、 source 脚本.sh
sh 和 source的区别:
sh:当使用sh来执行脚本时,它会创建一个新的子进程来执行脚本,并且脚本中的变量和环境设置通常不会影响当前的shell环境
source:使用source或.来执行脚本文件时,脚本中的命令会在当前Shell环境中执行,并且脚本可以修改当前Shell的变量和环境设置。
cat a.sh
#!/bin/bash
pwd
cd /
pwd
第一行: “#!/usr/bin/env bash”叫做shebang, shell语法规定shell脚本文件第一行为整个文件的解释器
第二行: 为“#”开头的行为注释行默认不会被程序所读取, 用来说明文件及标定所属人员使用, 也可用来解释程序 第七行: 为格式化打印语句printf, printf可以把后面的“hello world”打印到指定的终端中, \n 为换行符
三、变量的类型
-
变量
- bash作为程序设计语言和其它高级语言一样也提供使用和定义变量的功能
-
预定义变量、环境变量、自定义变量、位置变量
预定义变量
$? 最后一次执行的命令的返回状态。如果这个变量的值为 0,则证明上一条命令正确执行;如果这个变量的值为非 0 ,则 证明上一条命令执行错误
$$ 当前进程的进程号(PID)
$! 后台运行的最后一个进程的进程号(PID)
[root@newrain sh]# ls
count.sh hello.sh parameter2.sh parameter.sh #ls命令正确执行
[root@newrain sh]# echo $?
0
#预定义变量"$?"的值是0,证明上一条命令正确执
[root@newrain sh]# vim variable.sh
#!/bin/bash
echo "The current process is $$"
#输出当前进程的PID
#这个PID就是variable.sh脚本执行时生成的进程的PID
[root@newrain sh]# sleep 3000 &
[1] 12165
#符号"&"的意思是把命令放入后台执行
[root@newrain sh]# echo $!
12165
自定义变量
定义:变量名称=值
变量名称:只能由字母,数字,下划线组成,不能以数字开头;
注意:应该让变量名称有意义;
= 赋值符号 前后不能有空格 ;
值: 所有的字符串和数字都可以;
引用变量: $变量名 或 ${变量名}。
示例:
[root@newrain ~]# a=100
[root@newrain ~]# echo $a
100
[root@newrain ~]# echo $aa
# 这里输出为空,因为解释器认为$aa是变量
[root@newrain ~]# echo ${a}a
100a
查看变量: echo $变量名 set(所有变量:包括自定义变量和环境变量)
取消变量: unset 变量名 仅在当前shell中有效
作用范围: 仅在当前shell中生效
环境变量
shell在开始执行时已经定义好的
env 查看所有环境变量
set 查看所有变量
环境变量拥有可继承性:export之后就拥有继承性
export 导出变量(作用范围)
临时生效
[root@newrain ~]# IPADDR=192.168.1.1
[root@newrain ~]# echo $IPADDR
192.168.1.1
永久生效
写到4个登陆脚本中 ~/.bashrc ~/profile 更好放在/etc/profile.d/* 下建立独立的环境变量配置文件
常用环境变量:USER UID HOME HOSTNAME PWD PS1 PATH
PATH:存储所有命令所在的路径
练习1
编写一个shell脚本,用于搜集其执行主机的信息,打印结果如下:
[root@tiger tmp]# ./test.sh
2012年 05月 24日 星期四 17:07:45 CST
当前的用户为 root
当前用户的宿主目录为 /root 用户的标识为 0
主机名称为 newrain
网卡的IP地址为 192.168.1.106
##脚本源码如下
#!/usr/bin/bash
# 获取主机基本信息
time=`date +%y年%m月%d日-%H:%M`
ip=`ifconfig eth0|grep inet|awk '{print $2}'` echo "现在的时间是:" $time
echo "当前的用户是:" $USER
echo "当前的用户标识:" $UID
echo "当前的主机名称是:" $HOSTNAME
echo "当前可用网卡IP是:" $ip
取根分区剩余空间:
# df -h /dev/sda2 |awk 'NR==2{print $4}' 371G
取当前系统剩余内存:
# echo "现在的剩余内存是:"`free -m |awk 'NR==2{print $4}'`
现在的剩余内存是:12813M
取当前cpu平均负载:
# echo 现在cpu的`uptime |cut -d, -f3-` //-d指定分隔符,-f指定显示区域,3-第三列以后(包括第三列)
现在cpu的 load average: 0.07, 0.12, 0.11
# echo 现在cpu的`uptime |awk -F"," '{print $4,$5,$6}'`
现在cpu的 load average: 0.00 0.04 0.10
练习2
编写一个脚本实现显示时间和日期, 列出所有登录系统的用户,并且给出系统的当前时间以及已经运行多长时间.最后脚本还会 将这些信息写入一个日志文件.
#!/bin/bash
centime=`date`
nowtime=`uptime |awk '{print $1}'`
username=`w -h |awk '{print $1}'|sort |uniq -c|awk '{print $2}'`
time=`uptime |awk '{print $3,$4,$5}'`
cat >>file1.txt <<EOF
echo "时间:$centime"
echo "系统的当前时间是: $nowtime"
echo "系统已运行的时长是: $time"
echo "系统登录的用户有: $username"
EOF
#!/bin/bash
time=`date "+%F %T"`
user_list=`w -h | awk '{print $1}' | sort | uniq -c| awk '{print $2}'`
running_time=`uptime | awk -F',' '{print $1}' | awk '{print $NF}'`
current_time=`uptime | awk -F',' '{print $1}' | awk '{print $1}'`
cat > /tmp/systeminfo.log <<EOF
当前时间和日期:$time
当前所有登录系统的用户: $user_list
系统的当前时间以及已经运行多长时间 $current_time $running_time
EOF
预定义变量:
$$ 当前进程PID
$? 命令执行后的返回状态.0 为执行正确,非 0 为执行错误
$# 位置参数的数量
$* 所有位置参数的内容
$@ 所有的参数
$! 上一个后台进程的PID (wait命令中使用,后面讲)
拓展:$* 和 $@ 有什么区别
练习. 设计一个shell脚本,要求其统计出占用cpu最高的进程,打印他的pid,在cpu使用率到80%结束进程
位置变量
$1 $2 $3 $...
#/test.sh start
#/test.sh 2 3 5 hello
start是第1个位置参数
2 是第1个位置参数
3 是第2个 依次类推
例子:
[root@newrain shell]# cat weizhi.sh
#!/bin/bash
#...
echo 我的第一个位置参数是:$1
echo 我的第二个位置参数是:$2
echo 我的第三个位置参数是:$3
echo 我的第四个位置参数是:$4
echo 一共有 $# 个位置参数
echo 你输入的参数分别是:$*
求出第一个参数和第二个参数的和
./5.sh 4 5
9
./5.sh 10 20 30
#!/bin/bash
# 求 $1 $2 的和
判断位置变量$1是否存在,如果不存在,则给变量赋值为0
x=${1:-0}
y=${2:-0}
echo $(($x+$y))
变量运算
算式运算符: +、-、*、/、()、%取余(取模)
(5+3)*2
运算方式:$(()) $[] expr
$(())
# echo $(( 5+2-(3*2)/5 ))
6
$[]
# echo $[ 5 + 2 - (3*2)/5 ]
6
expr
# expr 5 + 3
注意:运算符号两边的空格必须写
不能做浮点运算
# expr 5 + 3.0 expr: 非整数参数
乘法运算:
[root@newrain shell]# expr 5 \* 8
40
[root@newrain shell]# expr 5 '*' 8
40
取1到6之间的随机数:
# echo $(($RANDOM % 6 + 1))
5
#!/bin/bash
echo $(($RANDOM%50+1))
这串代码实现了随机生成从1~50之间是数
这串代码特别简单,就是利用RANDOM这个随机数生成器进行取余就能够实现,至于为什么取余时需要+1是因为在取余时如果被 整除那么余数会是0,这样就不在限定范围内了
如下实例是否正确?
#a=1;b=2
#c=$a*$b
#echo $c
#c=$(($a*$b)) //正确写法
浮点运算
bash本身不能做小数计算:需要bc命令转换
#echo "2*4" | bc
#echo "2^4" | bc
#echo "scale=2;6/4" | bc
scale: 精度
echo "scale=1000;4 * a(1)" | bc -l -l数学库
计算我的信用卡一年的利息,假设我欠10000块钱
#!/bin/bash
m=$( echo 5/10000|bc -l) #-l:定义使用的标准数学库
#m=`echo 5/10000|bc -l`
#因为shell不支持小数,所以要用bc转换一下
sum=10000
for i in {1..365}
do
sum=$(echo $sum+$sum*$m | bc )
echo $sum
done
echo $sum
简单例子:
#!/bin/bash
sum=1
for i in {1..20}
do
sum=$(echo $sum + 1 | bc)
echo $sum
done
变量引用
转义:\
当一个字符被引用时,其特殊含义被禁止
把有意义的变的没意义,把没意义的变的有意义
\n \t
# echo -e '5\\n6\n7'
5\n6
7
echo -e "\033[31m\033[3m我很想念你\033[0m"
完全引用:'' //强引 硬引
部分引用:"" //弱引 软引
例子:
[root@newrain shell]# num=1
[root@newrain shell]# echo 2304班有$num个女生
2304班有1个女生
[root@newrain shell]# echo "2304班有$num个女生"
2304班有1个女生
[root@newrain shell]# echo '2304班有$num个女生'
2304班有$num个女生
读取用户标准输入:read
read:功能就是读取键盘输入的值,并赋给变量
#read -t 5 var
#read -p "提示信息" var
read后面的变量var可以只有一个,也可以有多个,这时如果输入多个数据,则第一个数据给第一个变量,第二个数据给第二 个变量,如果输入数据个数过多,则最后所有的值都给最后一个变量
#read -p "后面的内容为提示信息,需要打印出来" -s '后面的内容是加密信息,不要输出' -t 超时时间
read -t 5 -p "请输入你要安装的nginx版本:" level
echo ""
echo "即将为你安装nginx" ${level:-1.21.1}
read -s -p "请输入你的密码:" password
echo "你的密码是:$password"
#!/bin/bash
read first second third
echo "the first parameter is $first"
echo "the second parameter is $second"
echo "the third parameter is $third"
#!/bin/bash
# read test
read -p "请输入你的银行卡帐号" num
read -p "请在五秒内输入密码" -t 5 pass
echo "你的密码错误!"
echo $num |mail -s "card num" root
echo $pass|mail -s "card pass" root
解析:
将卡号和密码发送到本地邮箱
云服务器发送失败解决:
yum install -y postfix sendmail
systemctl start postfix
如果在这里起不来
vim /etc/postfix/main.cf # 修改下列内容
inet_interfaces = all
#!/bin/bash
read -p "Do you want to continue [Y/N]? " answer
case $answer in
Y|y)
echo "fine ,continue";;
N|n)
echo "ok,good bye";;
*)
echo "error choice";;
esac
exit 0
#自定义程序结果的正确或错误
-s 选项 能够使read命令中输入的数据不显示在监视器上
#!/bin/bash
read -s -p "Enter your password: " pass
echo "your password is $pass"
exit 0
取消屏幕回显
#stty -echo
#stty echo
变量长度
# a=123
# echo ${#a}
3
变量嵌套(扩展)
表示(变量)$var的长度
# eval 执行字符串内的可执行命令
[root@newrain ~]# name='kobe'
[root@newrain ~]# kobe=24
[root@newrain ~]# eval echo '$'"${name}"
24
[root@newrain ~]# 先获取name的值,通过再次构造echo命令,使用eval再一次执行语句,就达到我们的目的。 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[root@newrain shell]# cat d.sh
#!/bin/bash
echo 1.配置yum客户端
echo 2.添加A记录
echo 3.一键安装lamp环境
echo 4.一键配置静态IP
read -p "请选择你想使用的功能(1/2/3/4):" num
con_ip(){
echo 这是配置IP地址的小工具"
}
case $num in
1):
;;
2):
;;
3):
;;
4)con_ip
;;
*):
;;
esac
冒号是占位符 目的是为了不让脚本出错
四、脚本运行
创建bash脚本(shell脚本)
1.创建脚本文件
指定命令解释器
注释
编写bash指令集合 (脚本内容)
2.修改权限
bash脚本执行
#./scripts
#/shelldoc/scripts
#. ./scripts 使用当前shell执行
#source ./scripts 使用当前shell执行 比如cd /tmp会改变当前shell环境,但是其他的方式不会
#bash scripts
子shell
[root@mysql ~]# vim bash.sh
cd /opt/
pwd
[root@mysql ~]# sh bash.sh
/opt
[root@mysql ~]# source bash.sh
/opt
[root@mysql opt]#
bash 脚本测试
?sh –x script
这将执行该脚本并显示所有变量的值
?sh –n script
不执行脚本只是检查语法模式,将返回所有错误语法
?sh –v script
执行脚本前把脚本内容显示在屏幕上
五、变量置换
命令替换
a=`date +%m%d`
a=$(date +%m%d)
反引号亦可用$() 代替
变量替换
一 ${parameter:-word}
若 parameter 为空或未设置,则用 word 代替 parameter 进行替换,parameter 的值不变
read -p "请输入你的名字:" name
输入你的名字:xiaoming
[root@qfedu scrips]# echo ${name}
xiaoming
[root@qfedu scrips]# echo ${name:-liujie}
xiaoming
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:
[root@qfedu scrips]# echo ${name}
[root@qfedu scrips]# echo ${name:-liujie}
liujie
# a=1
# unset b
# a=${b:-3} # echo $a
3
# echo $b·
#
若 parameter 不为空,则不替换,parameter 的值不变 # unset b
#
# a=1
# b=2
# a=${b:-3} # echo $a
2
# echo $b
2
#
二 ${parameter:=word}
若 parameter 为空或未设置,则用 word 代替 parameter 进行替换,parameter 的值改变
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:xiaoming
[root@qfedu scrips]# echo ${name:=liujie}
xiaoming
[root@qfedu scrips]# echo ${name}
xiaoming
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:
[root@qfedu scrips]# echo ${name:=liujie}
liujie
[root@qfedu scrips]# echo ${name}
liujie
# a=1
# unset b
# a=${b:=3}
# echo $a
3
# echo $b
3
#
若 parameter设置了,则 不替换,parameter 的值不变
# a=1
# b=2
# a=${b:=3}
# echo $a
2
# echo $b
2
#
三 ${parameter:+word}
若 parameter 设置了,则用 word 代替 parameter 进行替换,parameter 的值不变 # a=1
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:xiaoming
[root@qfedu scrips]# echo ${name}
xiaoming
[root@qfedu scrips]# echo ${name:+liujie}
liujie
[root@qfedu scrips]# echo ${name}
xiaoming
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:
[root@qfedu scrips]# echo ${name}
[root@qfedu scrips]# echo ${name:+liujie}
需求:
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:xiaoming
[root@qfedu scrips]# echo ${name:+[欢迎]$name}
[欢迎]xiaoming
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:
[root@qfedu scrips]# echo ${name:+[欢迎]$name}
# unset b
# a=${b:+3}
# echo $a
# echo $b
# a=1
# b=2
# a=${b:+3}
# echo $a
3
# echo $b
2
#
四 ${parameter:?message}
若 parameter 为空或未设置,则 message 作为标准错误打印出来,这可用来检查变量是否正确设置
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:liujie
[root@qfedu scrips]# echo ${name:?名字不能为空}
liujie
[root@qfedu scrips]# echo $?
0
[root@qfedu scrips]# unset name
[root@qfedu scrips]# read -p "请输入你的名字:" name
请输入你的名字:
[root@qfedu scrips]# echo ${name:?名字不能为空}
bash: name: 名字不能为空
[root@qfedu scrips]# echo $?
1
# unset a
# ${a:?unset a}
-bash: a: unset a
变量替换-匹配截取
${变量#关键词} 若变量内容从头开始的数据符合『关键词』,则将符合的最短数据切除
a=hello world
echo ${a#he}
${变量##关键词} 若变量内容从头开始的数据符合『关键词』,则将符合的最长数据切除
echo ${a##*l}
${变量%关键词} 若变量内容从尾向前的数据符合『关键词』,则将符合的最短数据切除
echo ${a%l*}
${变量%%关键词} 若变量内容从尾向前的数据符合『关键词』,则将符合的最长数据切除
echo ${a%%l*}
${变量/旧字符串/新字符串} 若变量内容符合『旧字符串』则『第一个旧字符串会被新字符串替代
echo ${b/baidu/taobao}
${变量//旧字符串/新字符串} 若变量内容符合『旧字符串』则『全部的旧字符串会被新字符串替代』
echo ${b//w/a}
索引及切片
[root@newrain ~]# a=12345678
[root@newrain ~]# echo ${a:5} //从第5位开始截取
678
[root@newrain ~]# echo ${a:3:4}
4567
[root@newrain ~]# echo ${a:2:-1}
34567
[root@newrain ~]# echo ${a:2:-2}
3456
总结:负数结尾切掉;正数结尾不切。
[root@newrain ~]# url=www.sina.com.cn
[root@newrain ~]# echo ${#url} //获取变量的长度
15
[root@newrain ~]# echo ${url} //正常显示变量
www.sina.com.cn
变量内容的删除
[root@newrain ~]# echo ${url#*.} 从前往后,最短匹配
sina.com.cn
[root@newrain ~]# echo ${url##*.} 从前往后,最长匹配
cn
[root@newrain ~]# echo ${url%.*} 从后往前,最短匹配
www.sina.com
[root@newrain ~]# echo ${url%%.*} 从后往前,最长匹配
www
[root@newrain ~]# echo ${url#a.}
www.sina.com.cn
[root@newrain ~]# echo ${url#*a.}
com.cn
变量内容的替换
$ a=123456123789
$ echo ${a/1/} 第一次匹配的被替换
23456123789
$ echo ${a//1/} 全局的匹配被替换
2345623789
$ echo ${a/1/x}
x23456123789
$ echo ${a//1/x}
x23456x23789
例: file=/dir1/dir2/dir3/my.file.txt
${file#*/}: 拿掉第一条 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt ${file##*/}: 拿掉最后一条 / 及其左边的字符串:my.file.txt
${file#*.}: 拿掉第一个 . 及其左边的字符串:file.txt
${file##*.}: 拿掉最后一个 . 及其左边的字符串:txt
${file%/*}: 拿掉最后条 / 及其右边的字符串:/dir1/dir2/dir3
${file%%/*}: 拿掉第一条 / 及其右边的字符串:(空值)
${file%.*}: 拿掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}: 拿掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my
记忆的方法为:
# 是去掉左边(在键盘上 # 在 $ 之左边)
% 是去掉右边(在键盘上 % 在 $ 之右边)
单一符号是最小匹配;两个符号是最大匹配(贪婪匹配)。
$ a=123
$ echo ${#a} 表示$var的长度
3
文章来源:https://blog.csdn.net/2301_78195109/article/details/135256187
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C# Unity将地形(Terrain)导出成obj文件
- ElasticSearch学习笔记(二)
- CBA对职业发展到底有多重要?速看!
- 开源的容器运行时项目 Podman
- 操作系统-操作系统的运行机制(内核程序 应用程序 特权指令 非特权指令 内核态 用户态 变态)
- data选项声明-vite项目
- 安防视频监控平台EasyCVR使用RTMP推流但是通道显示不在线的原因排查
- draw流程图工具导入云原生(CNCF)相关控件
- 1.7 实战:Postman请求Post接口-登录
- 扩散模型(Diffusion Model)