编译器和解释器:V8是如何执行一段JS代码的
编译器和解释器:V8是如何执行一段JS代码的
背景
前端工具和框架迭出不穷,而且还不断有新的出现,要想追赶上这些工具和框架的更新速度,你就需要抓住那些本质的知识,然后才能更加轻松地理解这些上层应用。比如了解 V8 执行机制,能帮助你从底层了解 JavaScript,也能帮助你深入理解语言转换器 Babel、语法检查工具 ESLint、前端框架 Vue 和 React 的一些底层实现机制。
要深入理解 V8 的工作原理,首先关注以下几个概念:编译器(Compiler)、解释器(Interpreter)、抽象语法树(AST)、字节码(Bytecode)、即时编译器(JIT)。
编译器和解释器
之所以存在编译器和解释器,是因为机器不能直接理解我们写的代码,所以在执行程序之前,需要将我们所写的代码“翻译”成机器能读懂的机器语言。按语言的执行流程,可以将语言分为编译型语言和解释型语言。
编译型语言在程序执行之前,需要经过编译器的编译过程,编译后直接保留机器能读懂的二进制文件,运行程序时直接运行该二进制文件即可。比如 C/C++、GO语言等。
而由解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。比如 Python、JavaScript语言等。
具体流程可以参考下图
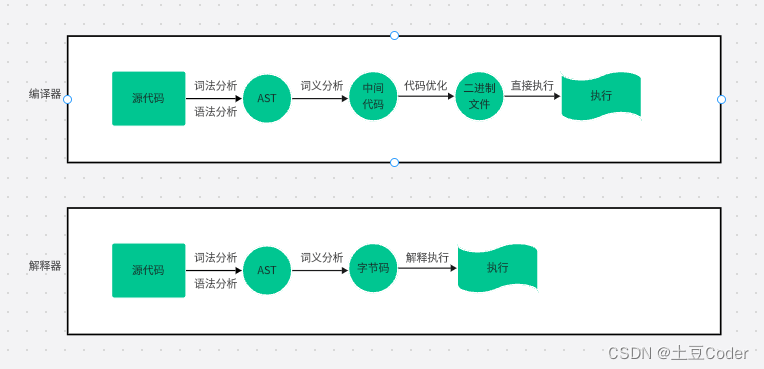
V8 执行 JavaScript 代码
1. 生成抽象语法树(AST)和执行上下文
高级语言是开发者可以理解的语言,但是让编译器或者解释器来理解就非常困难了。对于编译器和解释器来说,它们能理解的就是 AST。所以无论是编译型还是解释型语言,编译过程中都会生成一个 AST。这和渲染引擎将 HTML 格式文件转换为计算机可以理解的 DOM 树的情况类似。结合下面这段示例代码来直观地感受下什么是 AST:
var myname = 'yy'
function foo() {
return 23
}
myname = 'qq'
foo()
这段代码经过 javascript-ast 站点处理后,生成的 AST 结构如下:
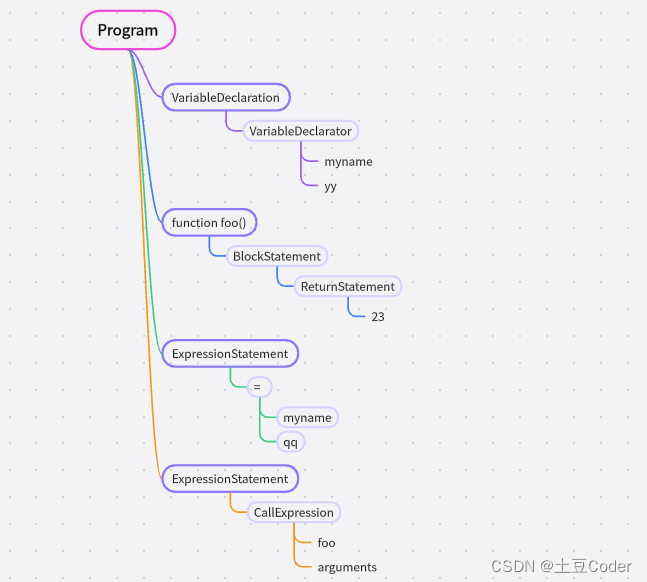
图中可以看出,AST 的结构和代码的结构非常相似,可以将其看成是代码结构化的表示,编译器或解释器后续的工作都需要依赖于 AST 而不是源代码。
AST 是一种非常重要的数据结构,在很多项目中都有着广泛的使用。例如 Babel、ESLint等。
Babel 是一个被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。
ESLint 是一个用来检查 JavaScript 编写规范的插件,它的检测流程也是将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题
那么,AST 是如何生成的呢?
第一阶段是分词(tokenize),又称为词法分析,其作用是将一行行源代码拆解成一个个 token(所谓 token,指的是语法上不可能再分的、最小的单个字符或字符串)。
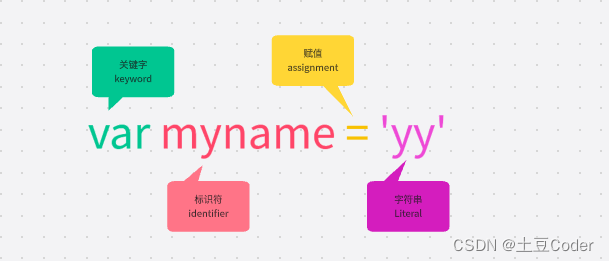
图中简单定义了一个 myname 的变量,生成了 4 个 token,而且它们代表的属性还不一样。
第二阶段是解析(parse),又称为语法分析,其作用是将上一步生成的 token 数据,根据语法规则转为 AST。当然,如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。
这就是 AST 的生成过程,先分词,再解析。有了 AST 后,接下来 V8 就会生成该段代码的执行上下文。至于执行上下文的具体内容,可以参考 JS变量和函数提升 以及 作用域链和闭包 这两篇文章。
2. 生成字节码
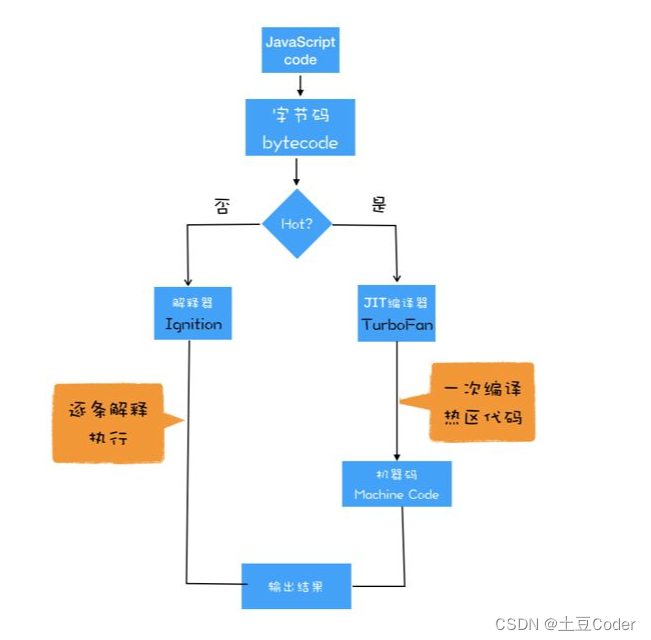
有了AST和执行上下文后,那接下来的第二步,解释器 Ignition 就登场了,它会根据 AST 生成字节码,并解释执行字节码。
其实一开始 V8 并没有字节码,而是直接将 AST 转换为机器码,由于执行机器码的效率是非常高效的,所以这种方式在发布后的一段时间内运行效果是非常好的。但是随着 Chrome 在手机上的广泛普及,特别是运行在 512M 内存的手机上,内存占用问题也暴露出来了,因为 V8 需要消耗大量的内存来存放转换后的机器码。为了解决内存占用问题,V8 团队大幅重构了引擎架构,引入字节码,并且抛弃了之前的编译器,最终花了将进四年的时间,实现了现在的这套架构。
那什么是字节码呢?为什么引入字节码就能解决内存占用问题呢?
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器 Ignition 将其转换为机器码后才能执行。
下图是对比高级代码、字节码和机器码的示意图
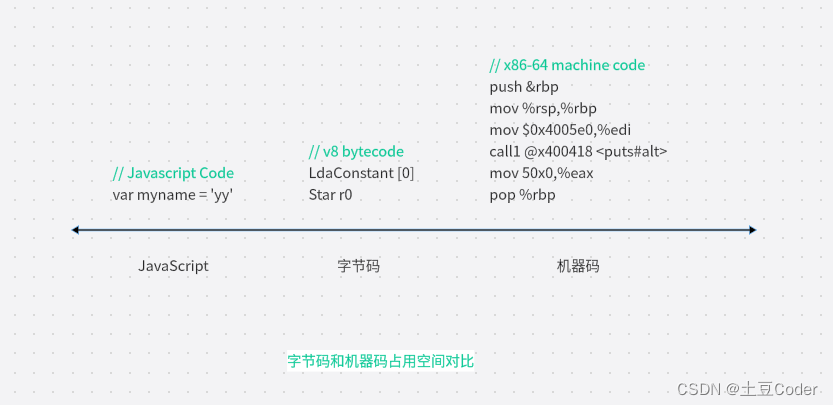
从图中可以看出,机器码所占用的空间远远超过了字节码,所以使用字节码可以减少系统的内存使用。
3. 执行代码
通常,一段第一次执行的字节码,解释器 Ignition 会逐条解释执行(相信你已经发现,解释器 Ignition 除了负责生成字节码之外,它还要解释执行字节码),在执行过程中,如果发现有热点代码(HotSpot)(一段会被重复执行多次的代码),后台编译器 TurboFan 会将该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,大大提升了代码的执行效率。
V8 的解释器和编译器的取名也很有意思。解释器
Ignition时点火器的意思,编译器TurboFan时涡轮增压的意思,寓意着代码启动时通过点火器慢慢发动,一旦启动,涡轮增压介入,其执行效率随着执行时间越来越高效率,因为热点代码都被TurboFan转换了机器码,直接执行机器码就省去了字节码“翻译”为机器码的过程。
其实字节码配合解释器和编译器是最近很火的一项技术,比如 Java 和 Python 的虚拟机都是基于这种技术实现的,我们把这种技术称为即时编译(JIT),可以结合下图看 JIT 的工作过程:
JavaScript 的性能优化
虽然在 V8 诞生之初,也出现过一系列针对 V8 专门优化 JavaScript 性能的方案,例如隐藏类、内联缓存等,不过随着 V8 的架构调整,你越来越不需要这些微优化策略了,相反,对于优化 JavaScript 执行效率,你应该将优化的中心聚焦到单次脚本的执行时间和脚本的网络下载上:
- 提升单次脚本的执行效率,避免 JavaScript 的长任务霸占主线程,使得页面快速响应交互
- 避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用线程
- 减少 JavaScript 文件的容量,因为更小的文件会提升下载速度,并且占用更低的内存
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!