正则表达式 详解,10分钟学会

大家好,欢迎来到停止重构的频道。
本期我们讨论正则表达式。
正则表达式是一种用于匹配和操作文本的工具,常用于文本查找、文本替换、校验文本格式等场景。
正则表达式不仅是写代码时才会使用,在平常使用的很多文本编辑软件,都是支持正则表达式搜索或替换的。
如vs code、notepad++、word、excel等,其中,word、excel中的正则表达式语法存在一些差异。
?我们将从以下几点展开讨论:
1、正则表达式介绍与应用
2、正则表达式语法详解
3、记不住语法的解决方案
1、正则表达式 介绍 & 应用
首先是正则表达式的介绍与应用。
正则表达式是一种用于匹配和操作文本的工具,可以用于文本查找、文本替换、文本格式校验等场景?。

正则表达式本身也是一段文本,或者说是一条字符串。
如图所示,示例1的正则表达式可以检查字符串是否符合邮箱的格式,示例2的正则表达式可以查找所有a开头的单词。

在程序开发中,正则表达式可用于字符串或文本的查找、替换、格式校验,以下Python为例。
示例1为查找a开头的所有单词。?
示例2为替换手机号中间数字为*号。
?示例3为校验字符串是否符合邮箱格式。



这里顺便一提,一般数据库,如MySQL,都是支持正则表达式查询的。

正则表达式可以通过简单的一条字符串,告诉程序应该执行什么样的文本匹配和操作。
如果是正常写代码的话,将是一大段代码,且维护性特别差。
不过,正则表达式的处理性能一般都不会太高,且越复杂的正则表达式处理起来越慢。
但是一般的应用开发是不需要考虑这个性能的。

?在我们开源的代码生成器Christmas中,也大量使用正则表达式,感兴趣的小伙伴可以下载翻看。

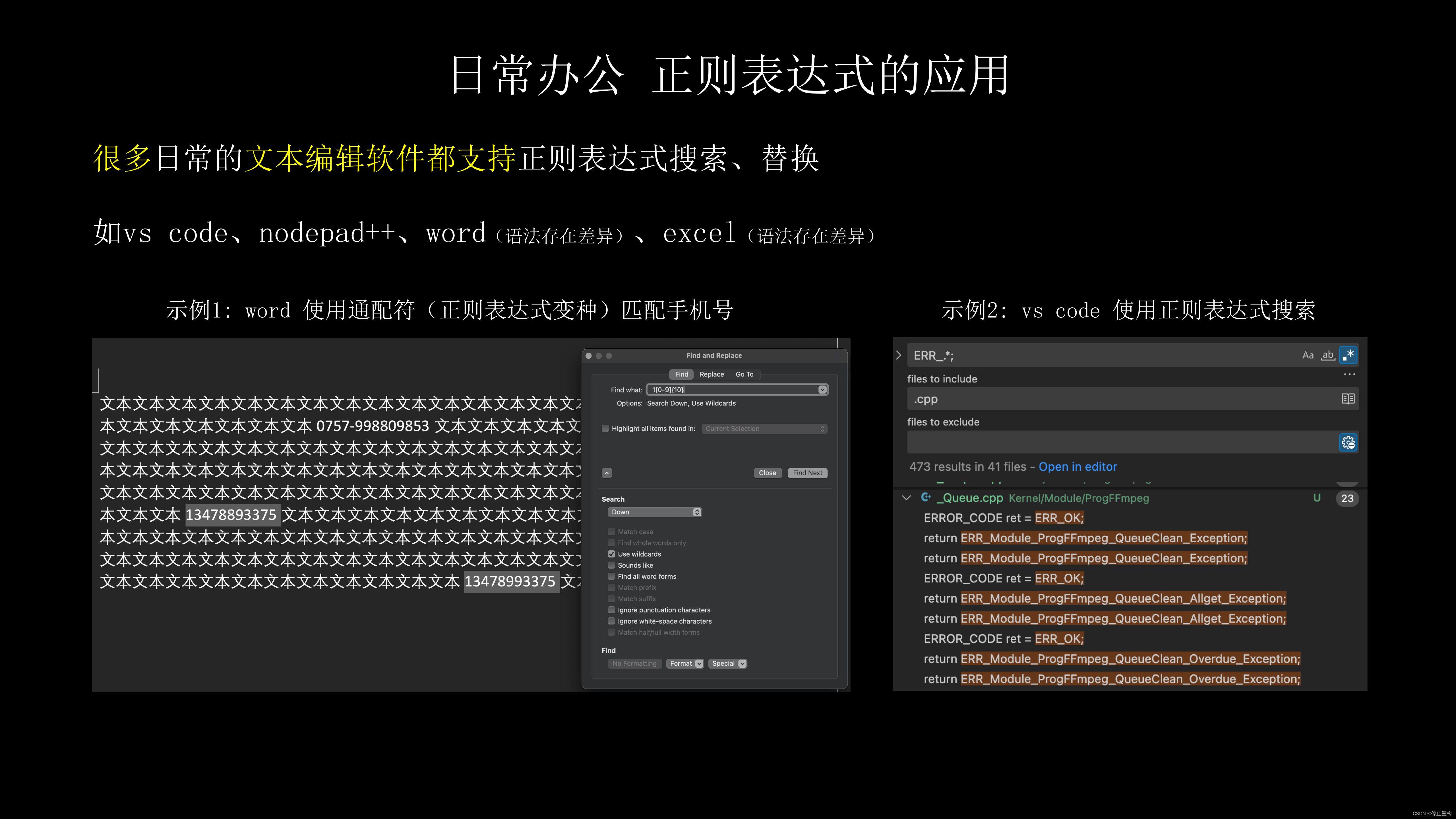
在日常办公中,很多文本处理软件也是支持正则表达式检索或替换的。
如word,在搜索框输入一条正则表达式,即可搜索出所有手机号。
2、语法:大纲
接下来详细讲解正则表达式的语法。
这里需要特别说明的是,不同正则表达式解析引擎可能有细微的语法差别,我们下面介绍的是最为通用的正则表达式标准。
?正则表达式说白了就是高级版关键字搜索。
对比普通的关键字搜索,正则表达式加入了很多具有特殊意义的元字符,通过加入这些元字符,即可实现灵活性更高的模糊匹配?。

理论上只要记住这些元字符,就几乎等于掌握了正则表达式。
但是元字符总共有几十个且很难记忆,所以通过列举的方式介绍每个元字符,并不是很好的介绍方法。
 ?我们尝试将正则表达式的语法结构化,将正则表达式语法分为:普通字符、字符集合、限定符、定位符、子表达式、省略符、修饰符。
?我们尝试将正则表达式的语法结构化,将正则表达式语法分为:普通字符、字符集合、限定符、定位符、子表达式、省略符、修饰符。

2-1、语法:普通字符
首先是普通字符
普通字符可以理解为明确的关键字,主要包括文字字符、符号?。

文字字符指的是英文字母、数字、中文字这些,文字字符在正则表达式中直接写就可以了。
如需要匹配get这个单词,正则表达式则直接写为get。

而符号,像%、_这些一般也是直接写就可以了。如需要匹配_get,正则表达式也是_get。

但是一些符号由于在正则表达式中有特殊含义,如果需要匹配这些符号,则需要\转义。
图中是需要转义的特殊符号,如需要匹配get*,正则表达式是get\*。

?普通字符除了文字字符、符号以外,还有一些不太常用的非打印字符、16进制、8进制、Unicode编码字符等。
这些都不需要记住,用到的时候再查就行。

2-2、语法:字符集合
??接下来是字符集合。
字符集合是单个字符的值范围,只要符合这个范围的字符都算是匹配成功。字符集合包含在一对[]之间,[]内,每一个字符都是允许匹配的值。

字符集合适合匹配多个关键字,且这多个关键字中只有个别字符存在差异的情况?。
如需匹配文本中的get、got,这两个关键字只有中间的字符存在差异,所以采用字符集合是合理的。

??这里需要特别说明的是,字符集合是单个字符的值范围。
如需匹配文本中的get、goat这两个单词,由于这两个单词的差异不仅仅在一个字符上,所以不能采用字符集合。

?字符集合中,为了简化连续字符,可以使用-标识连续字符的范围。
如需匹配文本中的gat、gbt、gct,正则表达式如图所示。

如果希望字符集合为排除在外的范围,则可以在字符集合的最开端添加^号。

2-3、语法:限定符
接下来是限定符。限定符是为了给前一个字符追加出现次数范围,常用的限定符为*号、+号、?号。
*号表示要求前一个字符出现0次或多次。
+号表示要求前一个字符出现1次或多次。
?号表示要求前一个字符出现0次或1次。
?如需要匹配文本中的god、good、goood,由于都是以g开头、d结尾,且中间包含1个或以上个o字符,则正则表达式为go+d。

?如果以上常用的限定符不能满足需求,如指定3次、3-6次等。可以使用{}标注具体次数。

当限定符前面的字符是一个模糊的匹配范围,如一个字符集合,则会发生贪婪匹配的问题。
默认情况下,正则表达式会匹配到尽量多的字符,这也称为贪婪匹配。
如示例1中,会匹配文本中的gadxxgod一长串字符串(贪婪匹配)。
?但如果我们不希望匹配这个长字符串,而是其中的gad、god这两个字符串。
则应该如示例2中,在示例一的限定符后追加?号即可实现非贪婪匹配,就可以匹配到gad、god这两个字符串。

2-4、语法:定位符
接下来是定位符,定位符是标记匹配位置而存在的。
定位符只有四个,整个字符串的开端、整个字符串的末尾、单词边界、非单词边界。

??以校验字符串是否为11位手机号为例,加入定位符更有利于精细匹配。

2-5、语法:子表达式
接下来是子表达式,子表达式是内嵌的子正则表达式。
子表达式写在一对()中间,子表达式与正则表达式的语法相同,子表达式内可以再内嵌子表达式。

?那子表达式有什么用呢?
子表达式可以看作是一个整体,如示例所示,当子表达式后添加限定符后,则可以匹配文本中连续的got字符串。

子表达式也可以作为多种情况的匹配范围,子表达式中用|分割多个子表达式,以表示多种情况。
如需要匹配文本中的get、goat两个字符串,正则表达式如图所示。

?子表达式也可以标记子匹配项,如需要匹配文本中AABB形式的字符串,示例中的\1表示与第1个子匹配项相同的内容,\2表示与第2个子匹配项相同的内容。

这里值得一提的是,在正则表达式标准中,每个子表达式的匹配结果会单独存储。
?如果子表达式的匹配结果不需要存储,可以在子表达式前添加标记,不过这个在日常使用中不太常用。

?另外,子表达式也可以作为预查匹配项,预查匹配项可以理解为自定义的定位符?。因为定位符只有四个,但是实际应用中,是远远不够的。

如图中示例,预查匹配项可以指定目标结果的前或后的特征,子表达式作为预查匹配项时,需要根据4种不同的预查匹配模式,添加对应的标识。

2-6、语法:省略符
通过以上语法,其实已经可以写出全部功能的正则表达式。但是一些局部未免有些啰嗦,所以出现了省略符。
省略符是一些为了简化正则表达式而存在的元字符,一般以\开头,如示例中的\d即可代表所有数字的字符集合。

常用的省略符如图所示,但是省略符仅仅是为了简化正则表达式而存在的,每个省略符都有对应的替代方案,所以省略符不必强行记忆。

2-7、语法:修饰符
最后是修饰符,严格意义上讲,修饰符并不是正则表达式的一部分。
修饰符是指定匹配策略的,如不区分大小写、多行匹配等,所以相同正则表达式,在指定不同修饰符情况下,匹配的结果会有所区别。

修饰符一般是4个,且修饰符可以叠加使用,但是某些正则表达式代码库可能存在不同的匹配策略,可能存在多于4个修饰符的设置。
这里需要特别说明的是,有些软件虽然支持正则表达式搜索,但不一定开放修饰符的设置。

3、记不住语法的解决方案
?在以上语法讲解中,我们已经尽量结构化了,但是仍然有很多难以记忆的标记或语法。
除非是每天都使用正则表达式,否则是不可能随随便便就写出一条准确无误的正则表达式的。
以我个人为例,?虽然使用正则表达式很多年,但是一到写正则表达式的时候,还是需要翻看手册。
所以记不住语法是正常的
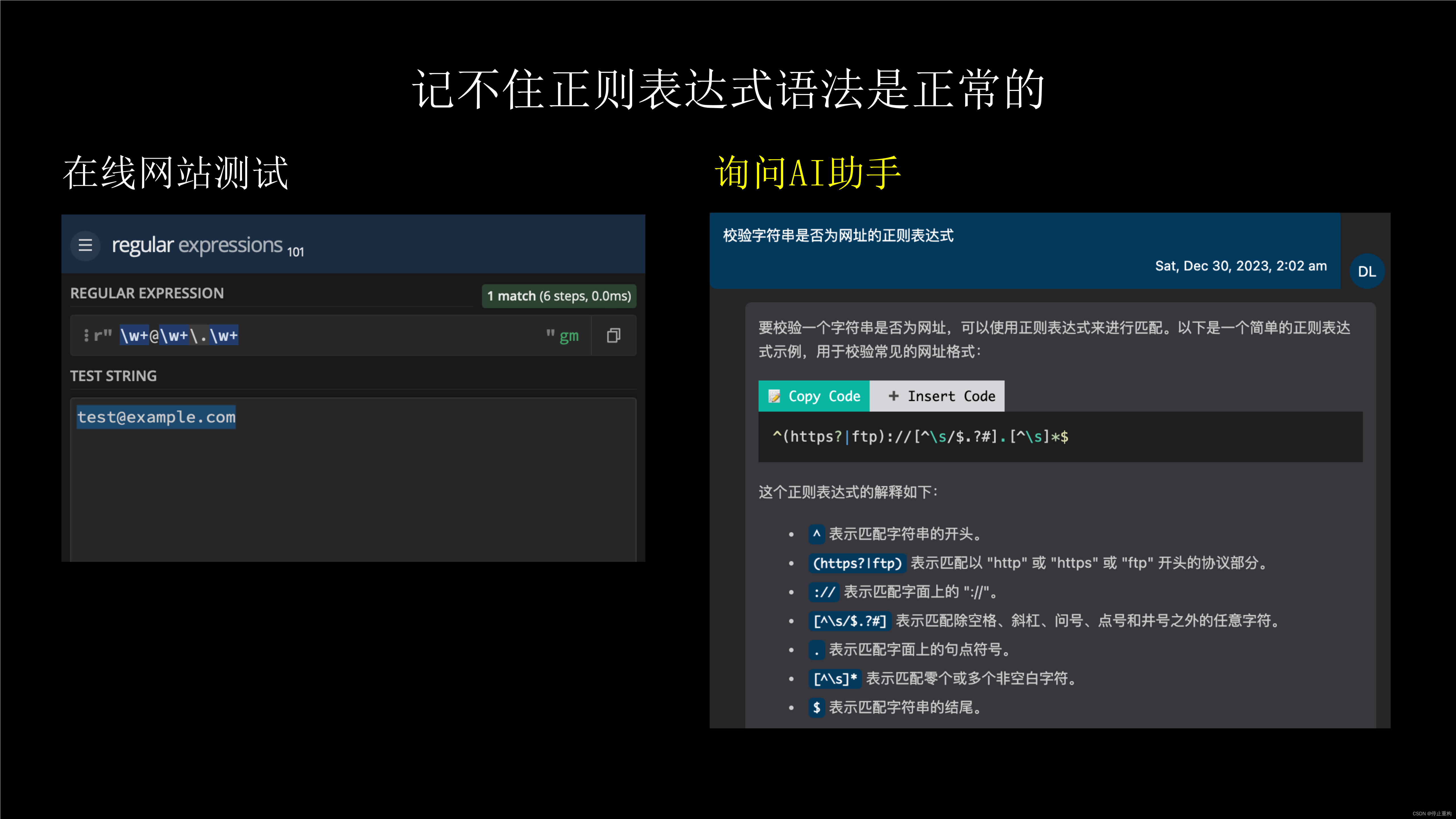
平常写正则表达式时,可以先在在线网站测试一下。
当然,如果你有一个AI助手,最好的方法是直接问AI,只要不是特别复杂或特殊的,AI助手一般都能直接给出答案,AI助手甚至能标注各个片段的作用。
总结
最后,正则表达式非常实用也足够流行,在非常多的文本处理软件中,都支持正则表达式?。大多数编程语言的标准库也包含正则表达式的支持。
但是在我们看来,正则表达式的某些元字符或标记的设计并不友好,注定是难以记忆的。
当然很多开源项目也尝试对正则表达式的语法进行改进,如google的re2,但是大多数人并不会选用。
毕竟正则表达式虽然很常用,但对于大多数人来说,也没有到天天都需要使用的程度,更何况现在有比搜索引擎更高效的AI助手呢。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!