数据结构----基本封装、包装类、装箱与拆箱、泛型详解
文章目录
1 包装类
在Java中,由于基本类型不是继承自Object,为了在泛型代码中可以支持基本类型,Java给每个基本类型都对应了一个包装类型。
1.1 基本数据类型和对应的包装类
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
除了 Integer 和 Character, 其余基本类型的包装类都是首字母大写。
包装类提供了许多有用的方法来处理基本数据类型,例如进行转换、比较、解析等。它们还允许将基本数据类型作为对象使用,在集合类中存储和操作。
基本数据类型和包装类的区别:
- 存储方式:基本数据类型直接存储数据值,而包装类是将数据值封装在对象中。
- 空值表示:基本数据类型没有空值,但包装类可以通过null表示空值。
- 默认值:基本数据类型有各自的默认值(如0、0.0、false等),而包装类的默认值是null。
- 内存占用:基本数据类型占用的内存比包装类少,因为基本数据类型直接存储数据值,而包装类需要额外的空间用于存储对象的引用。
- 包装类提供了许多实用的方法来处理基本数据类型,例如类型转换、数学运算等,而基本数据类型没有这些方法。
- 在Java中,自动装箱(Autoboxing)和拆箱(Unboxing)机制允许基本数据类型和包装类之间的自动转换。这使得在需要使用对象的情况下可以直接使用基本数据类型,而无需手动进行类型转换。
1.2 装箱和拆箱
int i = 10;
// 装箱操作,新建一个 Integer 类型对象,将 i 的值放入对象的某个属性中
Integer ii = Integer.valueOf(i);
Integer ij = new Integer(i);
Integer a = new Integer(10);
// 拆箱操作,将 Integer 对象中的值取出,放到一个基本数据类型中
int j = ii.intValue();
//显示拆箱 拆箱为自己指定的元素
int c = a.intValue();
double d = a.doubleValue();
1.3 自动装箱和自动拆箱
可以看到在使用过程中,装箱和拆箱带来不少的代码量,所以为了减少开发者的负担,java 提供了自动机制。自动装箱,又称“隐式装箱”,是指在编译阶段,Java编译器会自动将基本类型转换为对应的包装类型,而不需要显式地调用构造函数来完成装箱操作。
int i = 10;
Integer ii = i; // 自动装箱
Integer ij = (Integer)i; // 自动装箱
int j = ii; // 自动拆箱
int k = (int)ii; // 自动拆箱
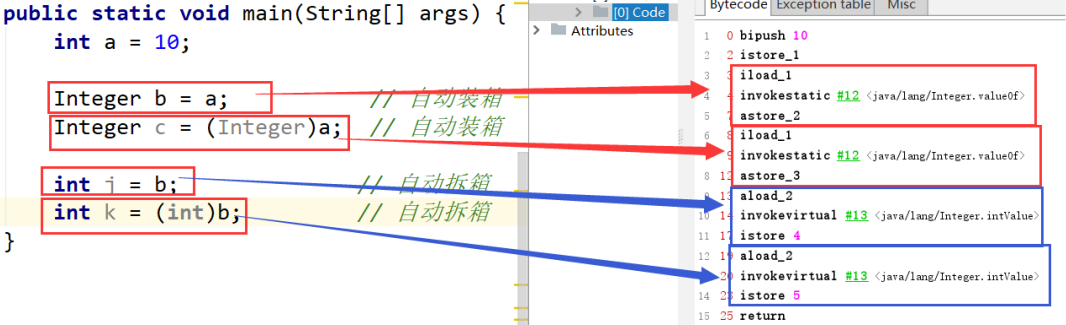
严格来说,int k = (int)ii; 不是自动装箱,而是强制类型转换,将基本数据类型int转换为包装类型Integer。在这种情况下,需要注意i的值不能超出Integer类型的取值范围,否则会抛出NumberFormatException异常。
1.4 易错题
public static void main(String[] args) {
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b);
System.out.println(c == d);
}
运行结果:
true
false
对于整数类型,存在一个整数缓存(Integer Cache),默认情况下缓存的范围是从 -128 到127。这意味着在这个范围内的整数装箱时,将重用缓存中已有的Integer对象,而不会每次都创建新的对象。这种缓存的机制是为了提高性能和节省内存。
由于a和b的值都在[-128, 127]之间,因此它们会被缓存在已有的整数缓存中,重复使用同一个对象,所以a和b指向的是同一个对象,因此a == b的结果为true。
而c和d的值都不在[-128, 127]之间,因此它们不会被缓存起来,每次自动装箱时都会创建一个新的Integer对象,所以c和d指向的不同对象,因此c==d的结果为false。

注意点:
超出缓存范围的整数值将始终创建新的Integer对象。即使是在使用自动装箱或显式装箱的情况下,超出范围的值也会导致创建新的对象。
在使用字符串转换为整数时,通过Integer.parseInt()方法将字符串解析为整数值时,如果字符串的值超出了Integer类型的取值范围,将会抛出NumberFormatException异常。这是因为parseInt()方法执行的是精确的整数解析,不会利用缓存机制。
因此,超出Integer类型取值范围的整数值会导致创建新的Integer对象,而且如果是通过字符串解析得到的超出范围的值,会抛出NumberFormatException异常。
2.泛型
在编程中,泛型(Generic)是一种通用的编程概念,它可以用于定义能够适用于多种类型的函数 、类或数据结构。泛型允许在编写代码时不指定具体的类型,而是使用类型参数来表示待定的类型。泛型的主要目的:就是指定当前的容器,要持有什么类型的对象,让编译器去做检查。此时,就需要把类型,作为参数传递。需要什么类型,就传入什么类型.
【语法说明】:
class 泛型类名称<类型形参列表> {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> {
}
class 泛型类名称<类型形参列表> extends 继承类/* 这里可以使用类型参数 */ {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {
// 可以只使用部分类型参数
}
【代码实例】:
class MyArray<T> {
public Object[] array = new Object[10];
public T getPos(int pos) {
return this.array[pos];
}
public void setVal(int pos,T val) {
this.array[pos] = val;
}
}
public class TestDemo {
public static void main(String[] args) {
MyArray<Integer> myArray = new MyArray<>();
myArray.setVal(0,10);
myArray.setVal(1,12);
int ret = myArray.getPos(1);
System.out.println(ret);
myArray.setVal(2,"bit");//代码编译报错,此时因为在初始化时指定类当前的类型为Integer,
//编译器会在存放元素的时候帮助我们进行类型检查为String类型,会编译报错
}
}
总结:
类名后的 < T > 代表占位符,表示当前类是一个泛型类 【规范】类型形参一般使用一个大写字母表示,常用的名称有:
不能new泛型类型的数组
T[] ts = new T[5];//error,编译报错
创建MyArray类型后加入 < Integer > 指定当前类型,对数据类型参数化,编译时自动进行类型检查和转换,当程序运行起来之后,到JVM之后就没有泛型的概念了
泛型只能接受继承于Object的类型,所有的基本数据类型必须使用包装类(专门为了泛型而定义)
泛型是将数据类型参数化,进行传递

3 泛型类的使用
【语法说明】:
泛型类<类型实参> 变量名; // 定义一个泛型类引用
new 泛型类<类型实参>(构造方法实参); // 实例化一个泛型类对象
【代码示例】:
MyArray<Integer> list = new MyArray<Integer>();
【类型推导(Type Inference) 】:
当编译器可以根据上下文推导出类型实参时,可以省略类型实参的填写
MyArray<Integer> list = new MyArray<>(); // 可以推导出实例化需要的类型实参为 Integer
4.裸类型(Raw Type)
裸类型(Raw Type)是一个泛型类但没有带着类型实参,例如 MyArrayList 就是一个裸类型
MyArray list = new MyArray();
注意: 我们不要自己去使用裸类型,裸类型是为了兼容老版本的 API 保留的机制
裸类型(Raw Type)是指在泛型代码中使用泛型类型参数而没有指定具体类型实参的情况。当使用裸类型时,泛型的类型安全性检查被绕过,可能导致编译器无法捕获潜在的类型错误。
裸类型主要出现在以下两种情况下:
- 在旧版本的Java代码中:在引入泛型之前的旧代码中,没有使用泛型的概念。当将这些代码与使用泛型的新代码进行交互时,编译器会发出未经检查的警告,并将泛型类型参数擦除为裸类型。
- 显式使用裸类型:在泛型代码中,可以显式地指定裸类型,即省略泛型的具体类型实参。这通常是为了与不使用泛型的代码进行兼容或避免繁琐的类型参数指定。
使用裸类型存在以下风险和问题:
- 编译时类型安全性缺失:裸类型绕过了泛型的类型检查机制,编译器无法对其进行类型安全性检查。这可能导致在运行时出现类型转换错误或其他类型相关的异常。
- 运行时类型错误:由于裸类型丢失了具体的类型信息,可能导致在运行时发生ClassCastException等类型错误。
- 代码可读性和维护性下降:使用裸类型会降低代码的可读性和可维护性,因为泛型的意图和约束没有明确表达出来,代码的含义变得模糊。
当使用裸类型时,编译器会发出未经检查的警告。下面是一个使用裸类型的例子:
public class Example {
public static void main(String[] args) {
List list = new ArrayList(); // 使用裸类型
list.add("Hello");
list.add(123);
// 从列表中获取元素时,无法保证类型的安全性
String str = (String) list.get(0); //必须进行类型强转,而且运行时还可能会发生ClassCastException
int number = (int) list.get(1); //必须进行类型强转,而且运行时还可能会发生ClassCastException
System.out.println(str);
System.out.println(number);
}
}
在上面的示例中,创建了一个ArrayList的裸类型对象,并向其添加了一个字符串和一个整数。然后 ,我们尝试从列表中获取元素并进行类型转换。由于裸类型丢失了具体的类型信息,编译器无法在编译时捕获类型错误。因此,当我们运行该代码时,可能会抛出ClassCastException。
为了防止出现这个问题,我们应该使用泛型类型参数来明确指定列表的类型。下面是一个修复后的示例:
public class Example {
public static void main(String[] args) {
List<String> list = new ArrayList<>(); // 使用泛型类型指定只能存储String类型的数据
list.add("Hello");
// list.add(123); // 编译错误,无法将整数添加到字符串列表中
String str = list.get(0); // 不需要进行类型转换
System.out.println(str);
}
}
我们使用了泛型类型参数< String >来明确指定列表的类型为字符串类型。这样,编译器会在编译时进行类型检查,并阻止将整数添加到字符串列表中。这提供了更好的类型安全性,并在编译时捕获潜在的类型错误。
注意:为了避免使用裸类型,我们都应该尽量遵循泛型的使用规范,为泛型类型参数指定具体类型实参,并避免显式使用裸类型。这样可以确保代码的类型安全性,并使代码更易于理解和维护。
5 泛型编译过程
5.1 擦除机制
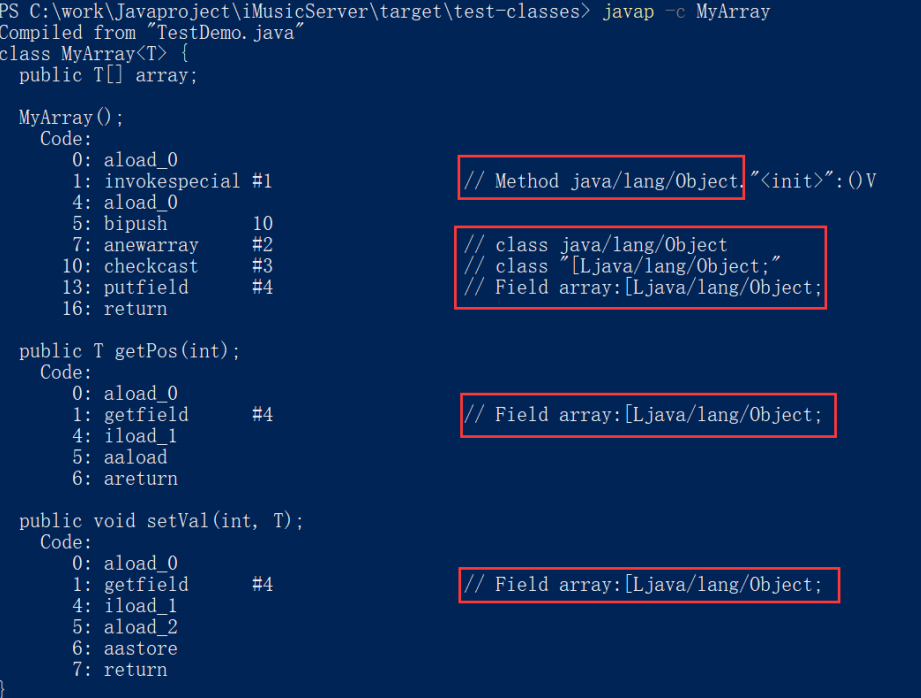
通过命令:javap -c 查看字节码文件,所有的T都是Object。
当使用泛型时,编译器会在编译过程中执行以下操作:
- 类型擦除:编译器将泛型类型参数替换为其上界或Object类型。例如,一个泛型类List< T >在擦除后会变成List< Object >。
- 类型转换:由于擦除导致类型信息丢失,编译器会插入必要的类型转换操作来保证代码的类型安全性。这些类型转换在编译时进行。
- 插入桥方法:当泛型类或接口涉及继承或实现时,编译器会插入桥方法来确保泛型类型的正确转换。桥方法是编译器生成的方法,用于在泛型类型和非泛型类型之间进行桥接。
【总结】
在编译的过程当中,将所有的T替换为Object这种机制,我们称为:擦除机制。
泛型的编译中,擦除(Erasure)机制是一项重要的步骤。它是指在编译阶段将泛型类型信息从生成的字节码中擦除的过程。擦除机制是在编译级别实现的。编译器生成的字节码在运行期间并不包含泛型的类型信息。擦除机制是为了保持与Java早期版本的向后兼容性,并允许泛型代码与不使用泛型的代码进行交互。
相关文章:Java泛型擦除机制之答疑解惑
5.2 实例化泛型类型数组的隐患
Java中不允许直接实例化泛型数组的原因与类型擦除机制有关。在泛型的擦除过程中,泛型类型参数被替换为其上界或Object类型,因此在编译时无法确定具体的泛型类型。这就导致无法直接实例化一个泛型数组。
- 使用public T[] array = new T[10]; 泛型数组出现的问题:
这种写法是不被允许的,因为在编译时无法确定泛型类型参数T的具体类型。编译器无法实例化一个未知类型的数组。例如,如果T是一个类的类型参数,那么new T[10]将无法确定要实例化哪个具体类的数组。 - 使用public T[] array = (T[])new Object[10];泛型数组出现的问题:
class MyArray<T> {
public T[] array = (T[])new Object[10];
public T getPos(int pos) {
return this.array[pos];
}
public void setVal(int pos,T val) {
this.array[pos] = val;
}
public T[] getArray() {
return array;
}
}
public static void main(String[] args) {
MyArray<Integer> myArray1 = new MyArray<>();
Integer[] strings = myArray1.getArray();
}
/*
Exception in thread "main" java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.Integer;
at TestDemo.main(TestDemo.java:31)
*/
原因:擦除机制后的方法为:将Object[]分配给Integer[]引用,程序报错。
public Object[] getArray() {
return array;
}
通俗讲就是:使用了类型转换将一个Object数组转换为泛型类型数组。尽管编译器允许这种写法,但是需要注意的是,这会引发潜在的运行时类型转换错误。由于类型擦除,编译器无法检查类型转换的正确性,返回的Object数组里面,可能存放的是任何的数据类型,可能是String,可能是Person,运行的时候,直接转给Object类型的数组,编译器认为是不安全的。因此可能会导致ClassCastException或其他类型相关的异常。
正确的方式1:
class MyArray<T> {
public Object[] array = new Object[10];
...
}
正确的方式2:
class MyArray<T> {
public T[] array;
public MyArray() {
}
/**
* 通过反射创建,指定类型的数组
* @param clazz
* @param capacity
*/
public MyArray(Class<T> clazz, int capacity) {
array = (T[])Array.newInstance(clazz, capacity);
}
public T getPos(int pos) {
return this.array[pos];
}
public void setVal(int pos,T val) {
this.array[pos] = val;
}
public T[] getArray() {
return array;
}
}
public static void main(String[] args) {
MyArray<Integer> myArray1 = new MyArray<>(Integer.class,10);
Integer[] integers = myArray1.getArray();
}
在上述示例中,我们通过使用反射来创建泛型数组。尽管编译器会发出未经检查的警告,但是我们可以安全地使用泛型数组,并在运行时避免类型转换错误。
5.3 相关问题
1、为什么,T [ ] ts = new T[5]; 是不对的,编译的时候,替换为Object,不是相当于:Object [ ] ts = new Object[5]吗?
2、类型擦除,一定是把T变成Object吗?
解析:
在Java中,泛型数组的创建是受到限制的。T [ ] ts = new T[5];这样的语法是不被允许的,因为在泛型的擦除过程中,数组的实际类型信息是丢失的。编译器无法确定如何创建一个泛型数组,因为它无法确定擦除后的具体类型。为了解释这一点,让我们假设编译器允许这样的语法,并将其替换为Object [ ] ts = new Object [5];然后考虑以下情况:
java ts[0] = new T();
这里的问题是,编译器无法确定T的具体类型是什么,因为类型信息已经被擦除了。如果T代表某个类或接口的子类型,那么使用new T()无法确定具体实例化哪个类。为了避免这种类型不确定性,Java禁止直接创建泛型数组。相反,可以使用通配符类型或者使用Object数组,并进行类型转换来实现类似的效果。类型擦除并不一定将类型参数替换为Object。在泛型的擦除过程中,类型参数被替换为它们的上界(或者如果没有指定上界,则被替换为Object)。例如,对于 List < T>,在类型擦除后会变为 List < Object>。但是,如果我们指定了上界,例如List< T extends Number>,在类型擦除后,T将被替换为Number,而不是Object。 总结起来,类型擦除会将类型参数替换为上界或Object,具体取决于类型参数是否有指定的上界。这样做是为了在擦除后仍然保持代码的类型安全性,并且与不使用泛型的代码进行兼容。
尽管泛型的擦除机制限制了在运行时访问具体的泛型类型信息,但在编译时它仍然提供了类型安全性和编译时类型检查的好处。擦除机制使得泛型代码可以与不使用泛型的旧代码进行交互,并允许在编译时捕获一些类型错误。尽管存在一些局限性,但擦除机制仍然是Java泛型实现的核心特性之一。
6 泛型的上界
在定义泛型类时,有时需要对传入的类型变量做一定的约束,可以通过类型边界来约束。
【语法】:
在Java中,可以使用extends关键字来指定泛型的上界。
class 泛型类名称<类型形参 extends 类型边界> {
...
}
【代码示例】:假设我们有一个泛型类或泛型方法,使用类型参数T。我们可以使用extends关键字来限制T必须是某个特定类或接口的子类型。下面是一个简单的示例:
public class MyArray<T extends Number> {
...
}
只接受 Number 的子类型作为 T 的类型实参
MyArray<Integer> l1; // 正常,因为 Integer 是 Number 的子类型
MyArray<String> l2; // 编译错误,因为 String 不是 Number 的子类型
error: type argument String is not within bounds of type-variable E
MyArrayList<String> l2;
^
where E is a type-variable:
E extends Number declared in class MyArrayList
在上面的示例中,类型参数 T 被限制为Number类的子类型。这意味着我们只能在MyArray中使用Number及其子类型作为T的具体类型。例如,可以使用Integer、Double或其他继承自Number的类型来实例化MyArray。
【复杂示例】:
public class MyArray<E extends Comparable<E>> {
...
}
E必须是实现了Comparable接口的
通过指定上界,我们可以在编写泛型代码时对类型参数进行更精确的控制,并在编译时捕获一些类型错误。这可以提高代码的安全性和可读性,并允许更好地利用静态类型检查的好处。
了解: 没有指定类型边界 E,可以视为 E extends Object
7 泛型方法
指在方法声明中使用了泛型类型参数的方法
【定义语法】:
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) { ... }
7.1【非静态方法代码示例】:
class Alg {
public <T extends Comparable<T>> T findMax(T[] array){
T max = array[0];
for (int i = 0; i < array.length; i++) {
if(max.compareTo(array[i]) < 0) {
max = array[i];
}
}
return max;
}
}
【使用示例-可以类型推导】:
这种泛型方法可以根据方法参数的类型推导出泛型类型参数的具体类型,而不需要显式地指定类型参数。编译器能够根据方法调用时提供的参数类型来推断泛型类型参数。这种类型的泛型方法可以更简洁地调用,因为编译器会自动推断类型。
Alg integerAlg = new Alg();
Integer maxValue = integerAlg.findMax(new Integer[]{1, 5, 2, 1, 78});
System.out.println(maxValue);
在上面的示例中,泛型类型参数T并没有显式地指定类型,而是根据方法参数array的类型进行推导。例如,如果调用findMax(new Integer[]{1, 5, 2, 1, 78}),编译器会自动推断T为Integer类型。
【使用示例-不使用类型推导】:
这种泛型方法在方法调用时显式地指定泛型类型参数的具体类型。手动指定泛型类型参数,这在某些情况下可能是必需的,特别是当类型推断无法正常工作或需要显式控制类型时。
Alg integerAlg = new Alg();
Integer maxValue = integerAlg.<Integer>findMax(new Integer[]{1, 5, 2, 1, 78});
System.out.println(maxValue);
7.2【静态方法代码示例】:
class Alg {
public static <T extends Comparable<T>> T findMax(T[] array){
T max = array[0];
for (int i = 0; i < array.length; i++) {
if(max.compareTo(array[i]) < 0) {
max = array[i];
}
}
return max;
}
}
【使用示例-可以类型推导】:
Integer maxValue2 = Alg.findMax(new Integer[]{1, 5, 2, 1, 7});
System.out.println(maxValue2);
String maxValue3 = Alg.findMax(new String[]{"add","asdf","werty"});
System.out.println(maxValue3);
【使用示例-不使用类型推导】:
Integer maxValue2 = Alg.<Integer>findMax(new Integer[]{1, 5, 2, 1, 7});
System.out.println(maxValue2);
String maxValue3 = Alg2.<String>findMax(new String[]{"add","asdf","werty"});
System.out.println(maxValue3);
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于“Python”的核心知识点整理大全44
- 国密算法:中国的密码盾牌,如何保障数据安全?
- Git提交规范
- RNN 相比于前馈神经网络的优势。
- Immutable模式想破坏也破坏不了。
- 浏览器安装证书,使用burp抓取任意https协议的流量
- List<String> list = map.getOrDefault(key, new ArrayList<String>());中getOrDefault什么意思
- 【JavaScript】DOM事件的传播机制
- 计算机体系结构----计分板(scoreboard)算法
- Java多线程&并发篇----第十一篇