SQL Server多数据表之间的数据查询和分组查询
文章目录
一、多数据表之间的数据查询
在SQL中,多数据表之间的查询主要用于以下方面:
在SQL Server中,多数据表之间的数据查询主要用于以下几个方面:
-
关联数据提取:现代数据库通常将数据分散在多个相关的表中以便于管理。例如,订单信息可能存储在一个表中,而客户信息可能存储在另一个表中。为了获取完整的订单详情,你可能需要从两个表中提取并合并信息。
-
数据整合:多表查询可用于整合来自不同数据源的信息,这对于报告和分析非常重要。比如,销售报告可能需要结合产品、销售和客户表中的数据。
-
性能优化:合理设计的数据库模型会将数据分散在多个表中,以减少冗余和提高性能。通过多表查询,可以有效地检索分散的数据而无需过多冗余。
-
数据完整性:数据库设计时通常会使用外键来维护不同数据表之间的关系,确保数据的一致性和完整性。多表查询可以利用这些关系来确保查询结果的准确性。
-
复杂的数据操作:多表查询允许执行复杂的数据操作,如连接(JOIN)、子查询(subquery)、并集(UNION)等,以执行复杂的业务逻辑和数据分析。
-
条件筛选:在多表查询中,可以通过在 WHERE 子句中设定条件来筛选跨多个表的数据,以满足特定的查询需求。
多表之间的数据查询主要有下面三种方式:
1.内连接查询
2.左外连接查询
3.右外连接查询
还有一些延伸的的方式,作简单介绍
1.1内连接查询(Inner join)
内连接用来查询两个或多个表中存在匹配关系的记录。仅返回在连接的表之间具有匹配值的行。既然是匹配关系,那也就是说内连接用于查找两个表中都有的记录,比如第一个表中有十行,那么响应的第二个表中也应该有十行与之对应。
语法格式:
select columns
from table1
inner join table2
on table1.column_name = table2.column_name;
最后一句解释:
ON table1.column_name = table2.column_name 是 SQL 查询中的一个语句片段,通常用在 JOIN 操作中,用来指定两个数据表之间的连接条件。这个语句的意思是,系统在连接 table1 和 table2 这两张表时,会按照两张表中的指定列 column_name 的值是否相等来确定哪些行之间应该被连接。
我们看一个具体的例子:
我们有两张表,表一Students:
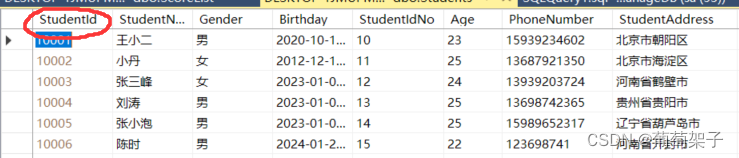
表二ScoreList:
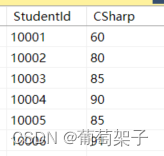
用下列程序:
select ScoreList.StudentId,StudentName,Gender ,Csharp
from ScoreList
inner join Students on Students.StudentId=ScoreList.StudentId
where CSharp>80
得到结果:
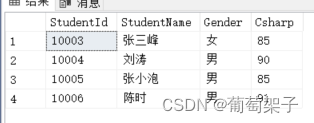
就是说我们可以以两个表上相同的列为桥梁将两个表中我们想要的数据合到一张表上,而且两张表无先后位置。
1.2 左外连接 (LEFT JOIN):
左外连接返回左表(FROM 子句中指定的表)的所有记录以及右表中匹配的记录。外连接(左、右、全)用于包含没有匹配的行的情景如果左表的行在右表中没有匹配,则结果集中这些行的右表部分为 NULL。语法:
select columns
from table1
left join table2
on table1.column_name = table2.column_name;
比如:table1(左表)是:
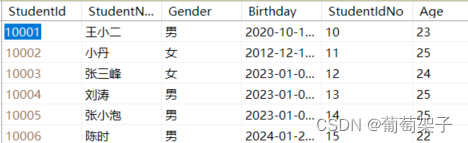
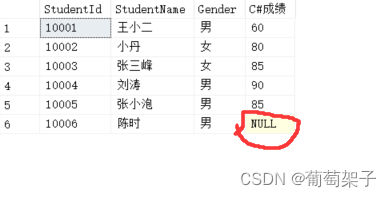
table2(右表)是:
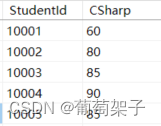
我们看到右表比左表少了一行,所以自动补上了NULL
1.3右外连接 (RIGHT JOIN):
右外连接与左外连接对应,返回右表的所有记录以及左表中匹配的记录。如果右表的行在左表中没有匹配,则结果集中这些行的左表部分为 NULL。
select columns
from table1
right join table2
on table1.column_name = table2.column_name;
1.4. 全外连接 (FULL OUTER JOIN):
全外连接返回左表和右表中的所有记录。当左表中的行在右表中没有匹配时,或者右表中的行在左表中没有匹配时,结果集会用 NULL 补充。
select columns
from table1
full outer join table2
on table1.column_name = table2.column_name;
1.5 交叉连接 (CROSS JOIN):
交叉连接返回两个表中所有可能的行组合。如果第一个表有10行,第二个表有5行,交叉连接的结果将有50行。不常用
select columns
from table1
cross join table2;
1.6 自连接 (SELF JOIN):
自连接是一种特殊形式的内连接或外连接,表与自身连接。不常用:
SQL Server 中的自连接(SELF JOIN)是一种特殊类型的连接,其中一个表会根据与自身的某些条件关联来进行连接。自连接通常用于处理那些在同一表内部就需要关联查询的情况,比如层级数据、树状结构或是任何需要比较同一个表内两个不同记录的场景。
在自连接中,实际上是把同一个表当作是两个独立的表进行连接操作。虽然物理上只有一个表,但是通过给表使用不同的别名,可以在查询中将其视为两个不同的表。
举个自连接的例子,假设我们有一个员工表 Employees,其中包含以下列:
EmployeeID(员工ID) -EmployeeName(员工姓名) -ManagerID(上级经理的员工ID)
在这种情况下,ManagerID 是这个员工的上级经理的 EmployeeID。我们想要列出所有员工及其对应的上级经理姓名。在这里,我们可以使用自连接来实现这个目标。
示例 SQL 查询如下:
select
e1.EmployeeName as EmployeeName,
e2.EmployeeName as ManagerName
from
Employees e1
left join Employees e2
on e1.ManagerID = e2.EmployeeID;
在这个查询中,Employees 表以 e1 和 e2 两个不同的别名存在。我们在查询中使用 left join 自连接这个表,通过 e1.ManagerID = e2.EmployeeID 条件来找到员工的上级经理。e1 代表的是员工,而 e2 代表的是经理。left join 确保了即使某些员工没有上级经理(ManagerID 为 NULL),他们的信息也会被列出。
结果将是一个两列的列表,第一列是员工的姓名,第二列是他们经理的姓名。如果某个员工没有经理,对应的 ManagerName 列会显示为 NULL。
1.7 子查询:
子查询可以在另一个查询中使用,它可以从一个表中筛选数据,然后用来与另一个表比较或操作。
select columns
from table1
where column_name IN (SELECT column_name FROM table2 where condition);
二、分组查询
2.1 分组查询
在SQL Server Management Studio(SSMS)中,分组查询主要通过group by 子句实现。group by子句通常与聚合函数(如COUNT()、SUM()、AVG()、MAX()、MIN()等)一起使用,可以对一组行中的某些列进行分组,并对每个组进行聚合计算。
以下是一个简单的分组查询示例,假设有一个名为Sales的表,包含了Item、Quantity和SaleDate三个字段:
Sales Table
-------------------------------------
| Item | Quantity | SaleDate |
-------------------------------------
| Pen | 10 | 2023-01-01 |
| Notebook | 20 | 2023-01-01 |
| Pen | 5 | 2023-01-02 |
| Eraser | 15 | 2023-01-02 |
| Notebook | 30 | 2023-01-03 |
| Pen | 10 | 2023-01-03 |
| Eraser | 20 | 2023-01-03 |
-------------------------------------
我们运行以下SQL查询:
select Item, SUM(Quantity) as TotalQuantity
from Sales
group by Item;
这个呢,将返回每个不同物品(Item)的总销售数量(TotalQuantity)。结果如下所示:
Result
------------------------
| Item | TotalQuantity |
------------------------
| Pen | 25 |
| Notebook | 50 |
| Eraser | 35 |
------------------------
在这个结果中,Pen 的TotalQuantity是25(10+5+10),Notebook的TotalQuantity是50(20+30),而Eraser的TotalQuantity是35(15+20)。
如果我们还想过滤出总销售数量大于30的物品,那就可以使用having子句,如下所示:
select Item, SUM(Quantity) as TotalQuantity
from Sales
group by Item
having SUM(Quantity) > 30;
此查询将返回总销售数量超过30的物品的列表。结果集将会是:
Result
------------------------
| Item | TotalQuantity |
------------------------
| Notebook | 50 |
| Eraser | 35 |
------------------------
在这个结果中,只有Notebook和Eraser显示在列表中,因为它们的TotalQuantity值分别是50和35,都大于30。
2.2 查询重复数据
在SQL Server中,要筛选出重复的数据,可以使用group by和having子句结合聚合函数。例如,我么想要找出Sales表中Item字段重复的记录,可以使用以下查询:
select Item, COUNT(*)
FROM Sales
GROUP BY Item
HAVING COUNT(*) > 1;
这个查询是按Item分组的,然后数每个分组的行数。having count(*) > 1这个条件将筛选出那些行数大于1的分组,也就是那些有重复Item值的记录。
在SQL中,COUNT(*)是一个聚合函数,用来计算某个结果集中的行数。它会包含所有的行,包括NULL值在内。这里使用COUNT(*) 来找出Sales表中Item字段重复的记录。这里COUNT(*) 计算的是每个Item分组内的记录数,然后使用having COUNT(*) > 1 来过滤,只显示那些出现了不止一次的Item,这样就能找出重复的记录。
现在假设Sales表的内容如下所示:
Sales Table
-------------------------------------
| ID | Item | Quantity | SaleDate |
-------------------------------------
| 1 | Pen | 10 | 2023-01-01 |
| 2 | Notebook | 20 | 2023-01-01 |
| 3 | Pen | 5 | 2023-01-02 |
| 4 | Eraser | 15 | 2023-01-02 |
| 5 | Notebook | 30 | 2023-01-03 |
| 6 | Pen | 10 | 2023-01-03 |
-------------------------------------
运行上述查询后,会得到如下结果:
Result
------------------------
| Item | (No column name) |
------------------------
| Pen | 3 |
| Notebook | 2 |
------------------------
这个结果中显示了Pen和Notebook是重复的,因为它们各自出现了3次和2次。
(不常用)如果我们还想要获取到具体的重复记录,可以使用子查询或者with关键字(CTE,也就是公用表达式)来获取这些数据。以下是使用子查询的例子:
select *
from Sales
where Item in (
select Item
from Sales
group by Item
having COUNT(*) > 1
);
这个查询返回了Item字段重复的所有记录。
而下面是使用CTE的例子:
with DuplicateItems as (
select Item, COUNT(*) AS Count
from Sales
group by Item
having COUNT(*) > 1
)
select s.*
from Sales s
Inner join DuplicateItems d on s.Item = d.Item;
这个查询使用CTE先找出重复的Item,然后通过内连接返回Sales表中相关的所有记录。
运行上述任一查询后,你将会得到包含重复Item所有数据的结果集,它们都包含Item为Pen和Notebook的记录。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 图像分割-漫水填充法 floodFill (C#)
- python爬虫之selenium模拟浏览器
- 你知道什么是显卡频率吗?你的显卡频率是多少?
- ARM_Linux的NFS网络文件系统的搭建
- shell脚本基础之条件语句详解
- QT上位机开发(动画效果)
- python爬虫网易云音乐(js逆向)
- 干洗店小程序:洗衣、洗鞋、工厂系统、上门取送、拍照预约、下单门店管理,一站式解决方案。
- 解决Spring Boot跨域问题(配置JAVA类)
- 【redis】redis的bind配置