LLaMa2大模型初体验
一直想在自己电脑或者测试环境随便找台服务器尝试部署一下“大模型”,但“大模型”对于内存和GPU的要求令人望而却步,层出不穷的各种术语也令人困惑,有点难以下手。
经过一段时间,在百度千帆大模型平台、讯飞星火大模型平台、魔搭社区等平台的锤炼之下,对于“大模型”的应用有了一点点认知,但离“本地”部署和应用仍然差距甚远。无意中了解到 llama.cpp 这个开源项目,才算打开了一扇窗户。
The main goal of llama.cpp is to run the LLaMA model using 4-bit integer quantization on a MacBook …
根据llama.cpp项目的介绍,我们知道它是 llama 大模型的c++实现,通过对参数的量化减少模型体积(内存占用)、提高推理速度,使得 llama 等大模型可以在个人电脑、linux 等环境下只依赖cpu就能跑起来。目前,它已经可以支持包括LLaMA2、Chinese LLaMA-2 / Alpaca - 2、百川、通义千问等等在内的众多开源大模型。项目介绍中甚至可以在安卓手机中跑起来。更多详细介绍,参考https://github.com/ggerganov/llama.cpp
初体验
基础环境准备
给自己分配了一台测试虚拟机,配置了10核心20线程的CPU(原本分配的是8核心16线程,后来测试发现分配为10核心后有明显提升,因此此处直接描述为修改后的配置),16G内存,centos 7 操作系统。
对于服务器主要做了如下调整:
- 安装git
- 升级gcc版本(否则在编译llama.cpp时会报错)
- 升级python到3.10.5 以上版本
下载和安装
- 通过git 拉取项目
git clone https://github.com/ggerganov/llama.cpp
- 编译
make
- 下载模型
llama.cpp项目提供了脚本,可以将网上下载的开源模型文件转换成F16格式,然后再使用脚本进行向量化,生成4-bit的gguf格式,这种格式的模型文件大大减少了模型体积,加快了推理速度,并且相比于F16格式并没有显著降低推理效果 (请注意这一切都是我从文档得知的结论,我本身并未进行效果对比测试)。
到这一步的时候,文档是让你自己选择模型,去huggingface进行下载。考虑到LLaMa 本身对中文支持并不好,并且,LLaMa本身是个基座模型,并不适用于对话类场景(也就是我们平时用的ChatGPT这种),因此,我选择了一个开源的基于LLaMa2的中文Alpaca模型 Chinese-LLaMA-Alpaca-2,最有意思的是,这个模型提供了一个RLHF版本,经过精调,在 正确价值观方面获得了显著性能提升(内涵)。
总而言之,考虑到内存、CPU性能限制,但是对效果又想有点追求,我直接在huggingface下载了 7B级别的 q4_k.gguf 和 q6_k.gguf 两个版本的模型文件进行测试。下载地址:https://huggingface.co/hfl/chinese-alpaca-2-7b-rlhf-gguf/tree/main
- 将模型文件上传到测试服务器,进入
llama.cpp项目路径下执行脚本测试
跑一跑
先来试试文字生成,按照说明文档,执行命令:
./main -m ../../chinese-llama-alpaca-rlhf-7b/ggml-model-q4_k.gguf --prompt '从前,有一座山,山上有个老和尚'
程序呼哧呼哧加载后就开始跑了,如下所示:
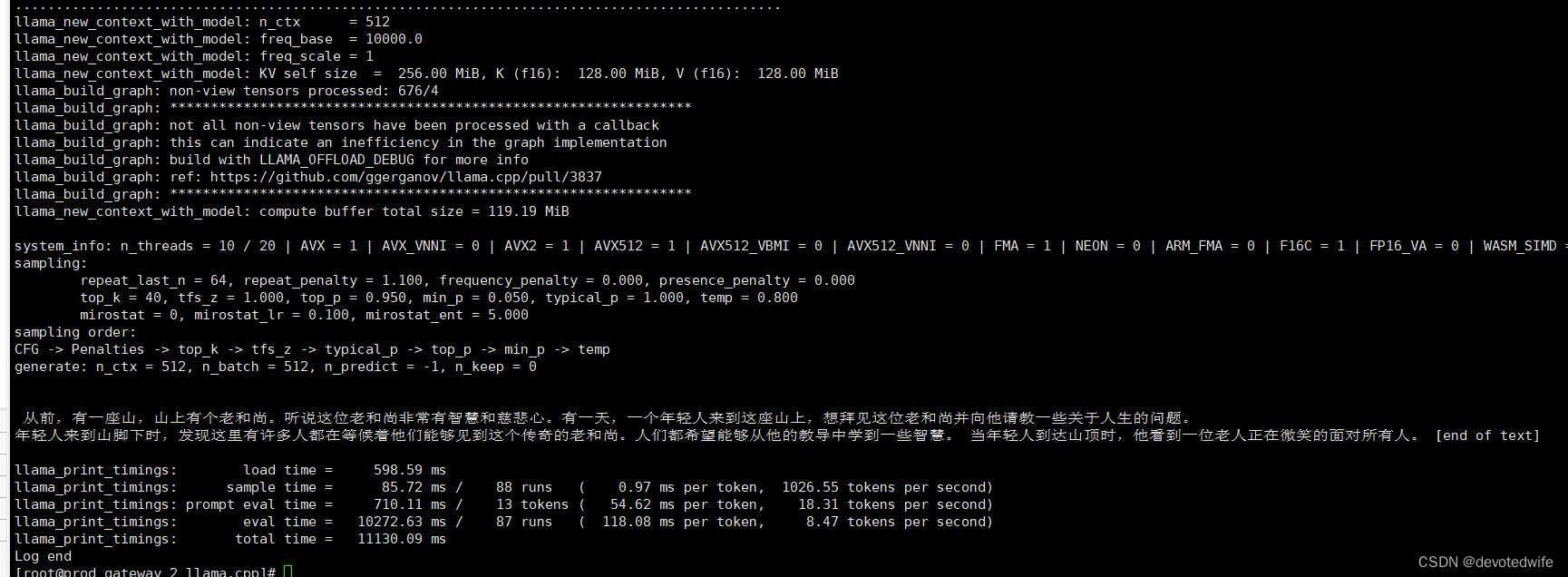
我们换成 q6_k 模型试试:
./main -m ../../chinese-llama-alpaca-rlhf-7b/ggml-model-q4_k.gguf --prompt '从前,有一座山,山上有个老和尚'
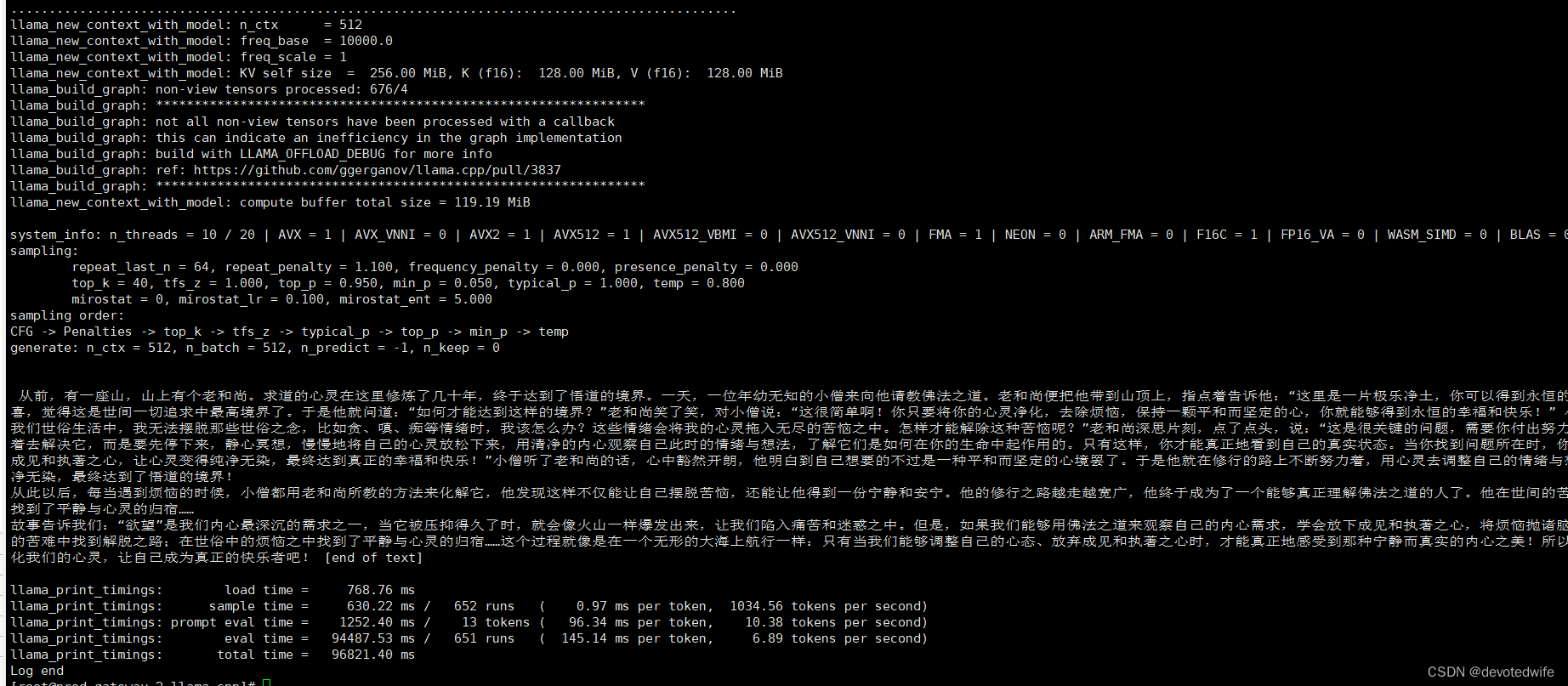
唔,我们很明显可以看到,q6_k 版本要比 q4_k 啰嗦多了。
模型推理时,观察CPU和内存占用,CPU将将跑满,内存占用35%左右,与模型文件大小相仿。
试完文字生成,让我们再来试试对话能力。
// TODO
下一步思路
- 尝试使用llama.cpp的server功能,搭建一个简单的web服务,体验通过api调用大模型
- 尝试使用 通义千问1.8B-Chat模型 对比一下效果
- 尝试使用LangChain框架结合llama.cpp
- 尝试基于LangChain框架,本地构建一个简单的文档AI应用,通过将文档向量化和搜索之后,调用大模型进行回答
- 尝试大模型微调…
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Stage 模型
- 用ChatGPT教学、科研!大学与OpenAI合作
- Java网络编程-16
- 敲敲云—超越想象的零代码平台,听听网友怎么说
- 力扣(leetcode)第35题搜索插入位置(Python)
- 用C语言递归函数strlength实现求字符串长度和将ch某个字符小写转成大写,返回个数---------(C每日一编程)
- 硬件连通性测试:确保系统稳定运行
- GPT-4与DALL·E 3:跨界融合,开启绘画与文本的新纪元
- 书生·浦语大模型实战营笔记(四)
- JavaScript实现网页全屏