大模型实战营Day5 LMDeploy大模型量化部署实践
发布时间:2024年01月14日
模型部署 定义 产品形态 计算设备
大模型特点 内存开销大 动态shape 结构简单
部署挑战 设备存储 推理速度 服务质量
部署方案:技术点 (模型并行 transformer计算和访存优化 低比特量化 Continuous Batch Page Attention)方案(云端 移动端)

LMDeploy: 云端部署
接口: python gRPC RESTful
轻量化 推理引擎 服务(api server gradio triton inference server)
无缝对接open compass

推理性能 静态vs动态

核心功能 量化FP16 Int4-8
模型显存优化明显(24GB显存 4倍提升)

计算密集 访存密集(大模型一般是访存密集)

推理引擎 TurboMind
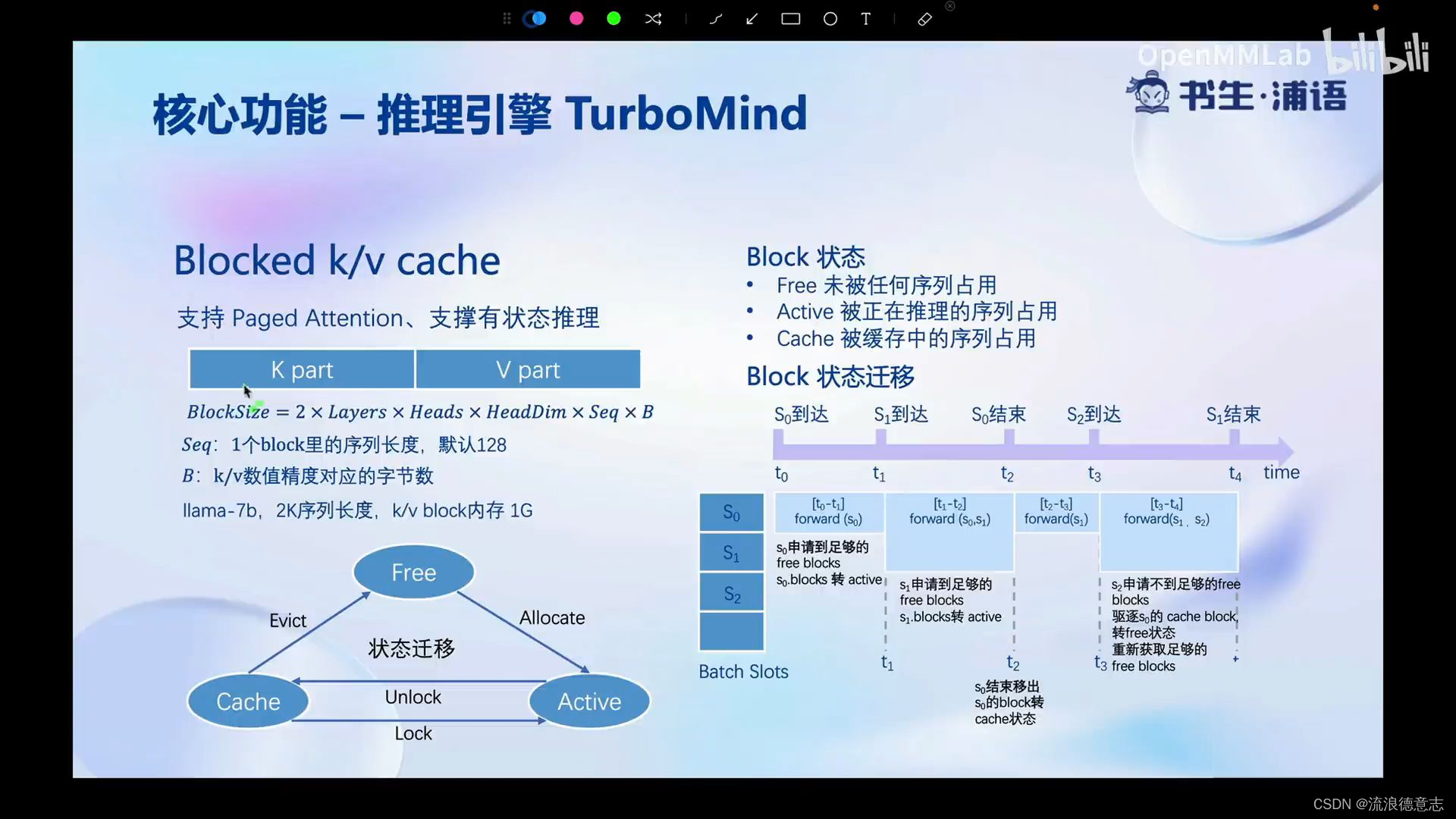
持续批处理 有状态的推理 高性能cuda kernel Blocked k/v cache分块缓存

持续批处理 请求队列+Persistent线程

有状态的推理 推理测的缓存
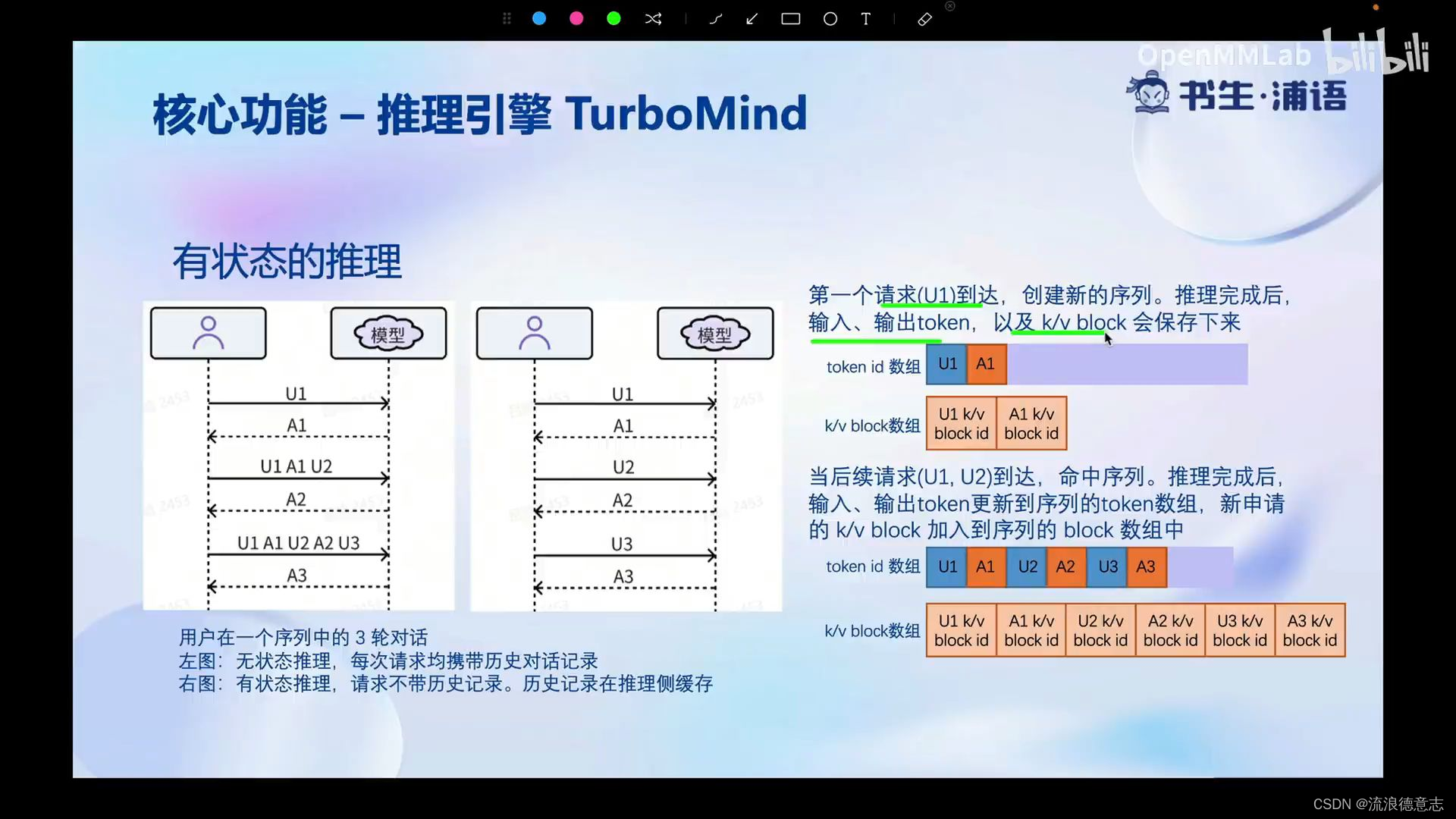
分块的k/v缓存 历史缓存
高性能cuda kernel
Flash Attention2
Split-k decoding
Fast w4a16, kv8
算子融合

推理服务api server

文章来源:https://blog.csdn.net/li4692625/article/details/135581429
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 美易官方:开盘:美股高开科技股领涨 标普指数创盘中新高
- 权重初始化和激活函数小结
- C++单例设计模式
- 基于Java+SpringBoot+vue+elementui的校园文具商城系统详细设计和实现
- 游泳耳机哪个牌子好?最好用的游泳耳机品牌推荐
- 关于Geek软件的下载
- java类与对象详细介绍
- 百度云IOCR自定义模版分类器进行文字识别(非通用文字识别)
- 论文速看 Few-shot Image Generation with ElasticWeight Consolidation
- DDD领域驱动设计(四)