Java HashMap 面试题(一)
HashMap 面试题(一)
3.3 面试题-说一下HashMap的实现原理?
HashMap的数据结构: 底层使用hash表数据结构,即数组和链表或红黑树
-
当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
-
存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
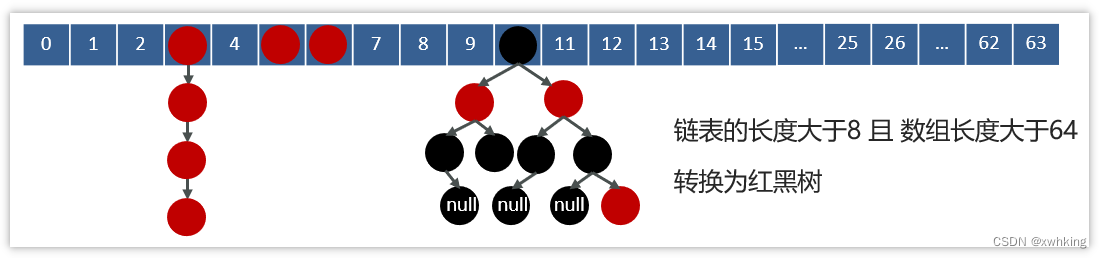
面试官追问:HashMap的jdk1.7和jdk1.8有什么区别
-
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
面试题-HashMap的put方法的具体流程
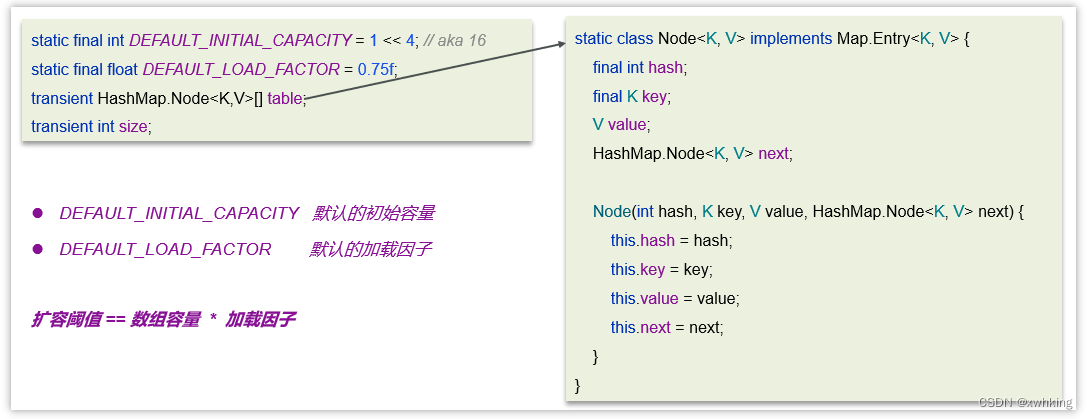
hashMap常见属性
源码分析

-
HashMap是懒惰加载,在创建对象时并没有初始化数组
-
在无参的构造函数中,设置了默认的加载因子是0.75
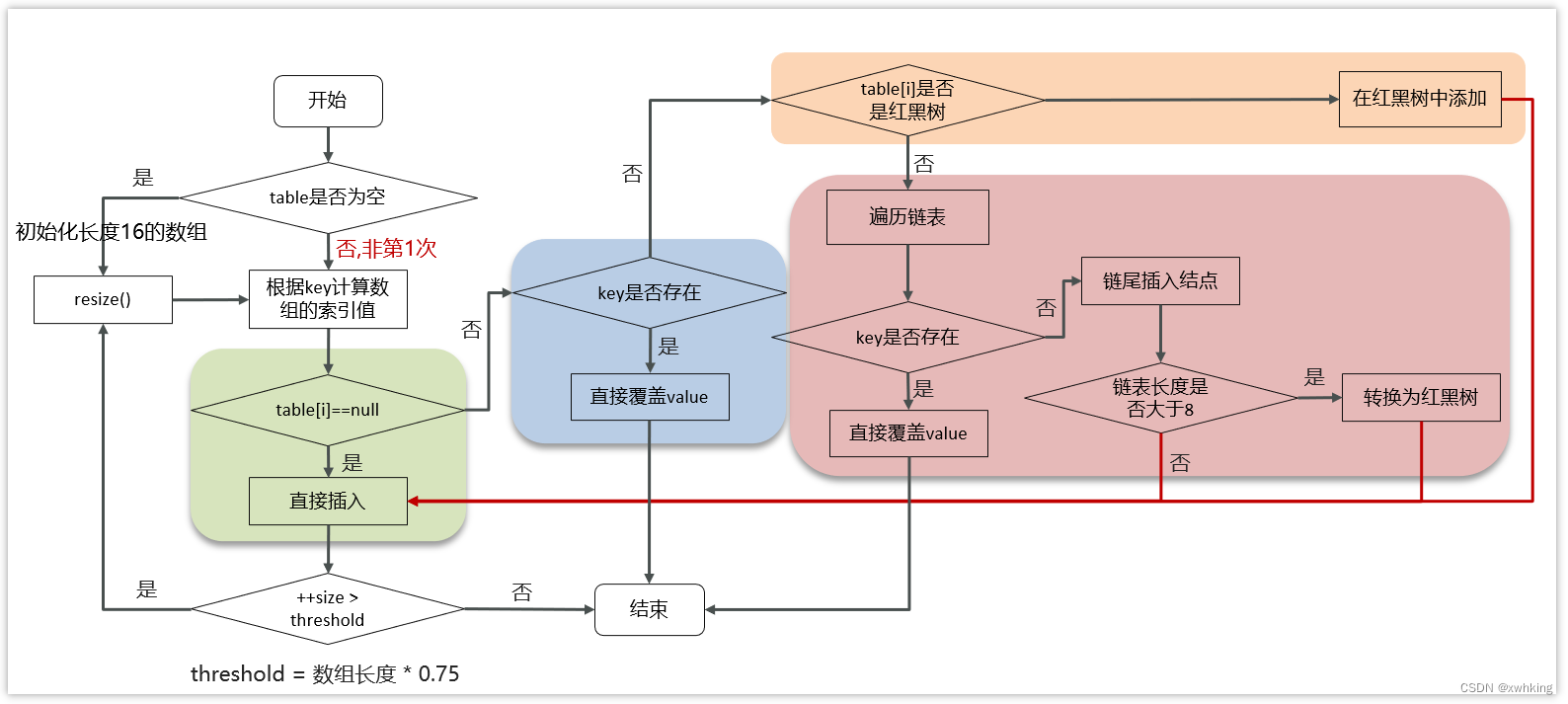
添加数据流程图
具体的源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断数组是否未初始化
if ((tab = table) == null || (n = tab.length) == 0)
//如果未初始化,调用resize方法 进行初始化
n = (tab = resize()).length;
//通过 & 运算求出该数据(key)的数组下标并判断该下标位置是否有数据
if ((p = tab[i = (n - 1) & hash]) == null)
//如果没有,直接将数据放在该下标位置
tab[i] = newNode(hash, key, value, null);
//该数组下标有数据的情况
else {
Node<K,V> e; K k;
//判断该位置数据的key和新来的数据是否一样
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果一样,证明为修改操作,该节点的数据赋值给e,后边会用到
e = p;
//判断是不是红黑树
else if (p instanceof TreeNode)
//如果是红黑树的话,进行红黑树的操作
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//新数据和当前数组既不相同,也不是红黑树节点,证明是链表
else {
//遍历链表
for (int binCount = 0; ; ++binCount) {
//判断next节点,如果为空的话,证明遍历到链表尾部了
if ((e = p.next) == null) {
//把新值放入链表尾部
p.next = newNode(hash, key, value, null);
//因为新插入了一条数据,所以判断链表长度是不是大于等于8
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//如果是,进行转换红黑树操作
treeifyBin(tab, hash);
break;
}
//判断链表当中有数据相同的值,如果一样,证明为修改操作
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//把下一个节点赋值为当前节点
p = e;
}
}
//判断e是否为空(e值为修改操作存放原数据的变量)
if (e != null) { // existing mapping for key
//不为空的话证明是修改操作,取出老值
V oldValue = e.value;
//一定会执行 onlyIfAbsent传进来的是false
if (!onlyIfAbsent || oldValue == null)
//将新值赋值当前节点
e.value = value;
afterNodeAccess(e);
//返回老值
return oldValue;
}
}
//计数器,计算当前节点的修改次数
++modCount;
//当前数组中的数据数量如果大于扩容阈值
if (++size > threshold)
//进行扩容操作
resize();
//空方法
afterNodeInsertion(evict);
//添加操作时 返回空值
return null;
}
-
判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
-
根据键值key计算hash值得到数组索引
-
判断table[i]==null,条件成立,直接新建节点添加
-
如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
-
插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
大家好,我是xwhking,一名技术爱好者,目前正在全力学习 Java,前端也会一点,如果你有任何疑问请你评论,或者可以加我QQ(2837468248)说明来意!希望能够与你共同进步
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python---静态Web服务器-面向对象开发
- hAdmin漂亮的后台html模板免费下载
- MySQL性能测试(完整版)
- 生物系统学中的进化树构建和分析R工具包V.PhyloMaker2的介绍和详细使用
- python中Pytest常用的插件
- Android 13.0 Launcher3禁止卸载某个静默安装的第三方app
- Python range函数
- 【华为数据之道学习笔记】6-2数据服务生命周期管理
- Spark调优解析-spark数据倾斜优化2(七)
- ==(双等)与 equals的区别