大模型在广告ctr预估中的应用
发布时间:2024年01月11日
背景
预训练大模型在ctr预估方面取得了不错的效果,但是应用大模型方面还主要停留在提取离线预训练,然后使用大模型的打分结果或者中间的embedding向量,这种级联的应用方式相对灵活方便。但是这种使用大模型提取特征的方式存在自身的问题,那就是通过独立训练得到的特征,对于最终的ctr模型来说不是最优的。主要原因是预训练的大模型和ctr模型存在不对齐的问题,造成大模型提取的特征存在冗余重叠的情况。为了解决这个问题,微软ad团队提出了预训练+联合学习和蒸馏学习的方式,对大模型进行端到端的应用,从而返回大模型真正的威力。
论文:Learning Supplementary NLP Features for CTR Prediction in Sponsored Search
贡献
- 论文证明了非端到端应用的预训练模型,不能取得最好的ctr预测效果,原因是因为离线提取的特征和ctr特征存在冗余重叠问题,影响到了预训练模型提取特征的效果。
- 第一次提出了一种预训练+联合学习的方法,相对与离线大模型提取特征的应用方式,本方法能够有效的客服预训练模型提取特征存在冗余重叠的问题,并且提出了一种蒸馏学习的方法,将预训练的大模型中的只是蒸馏到一个更轻量级的小模型中。
- 基于商业和公共的数据集进行了充分的实验,证明了基于联合学习的方式,取得了显著的效果。基于蒸馏学习的方式,相比于基于特征的蒸馏学习的方式,能够取得两倍显著效果。
实现
预训练+联合学习
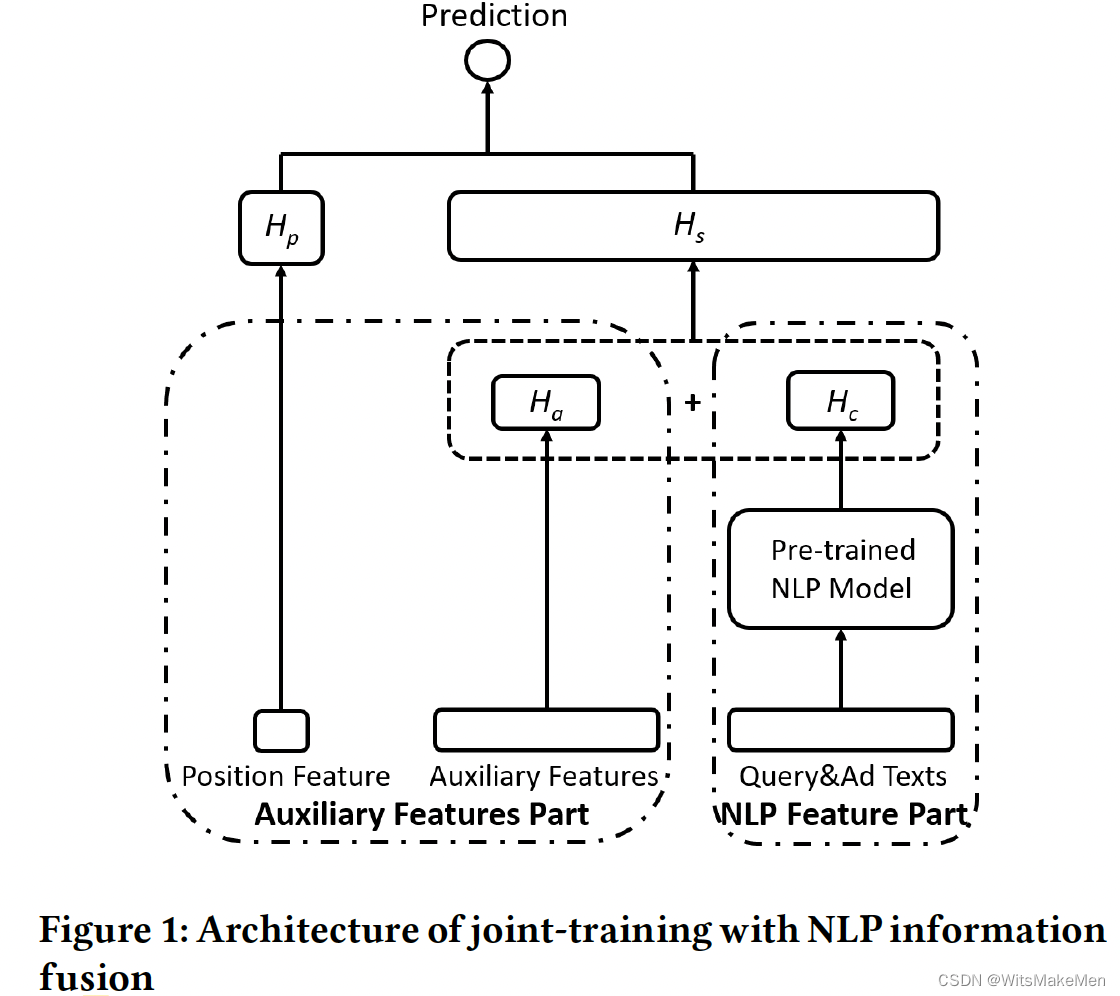
蒸馏学习
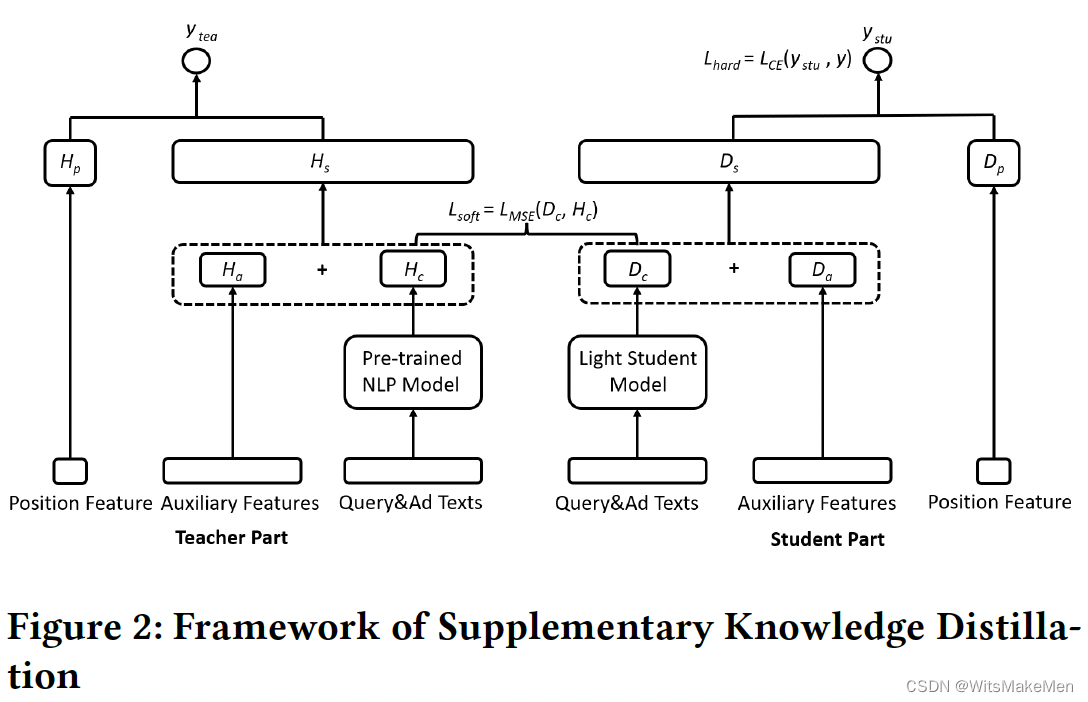
实验效果
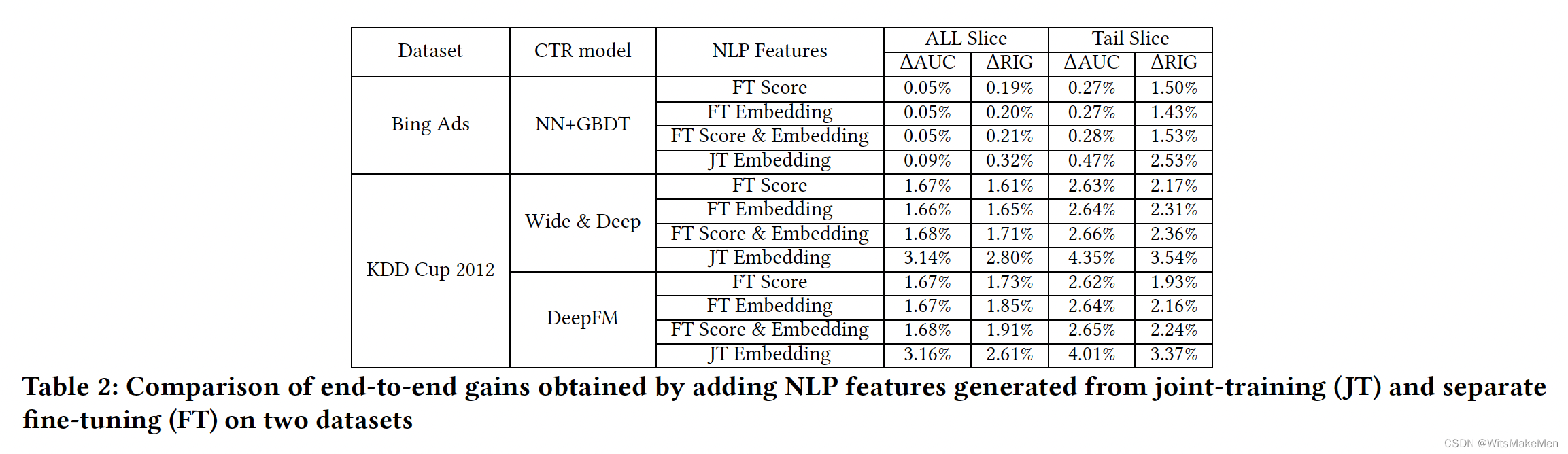
联合学习不同的融合效果对比

联合学习和离线特征提取效果对比
蒸馏学习效果对比
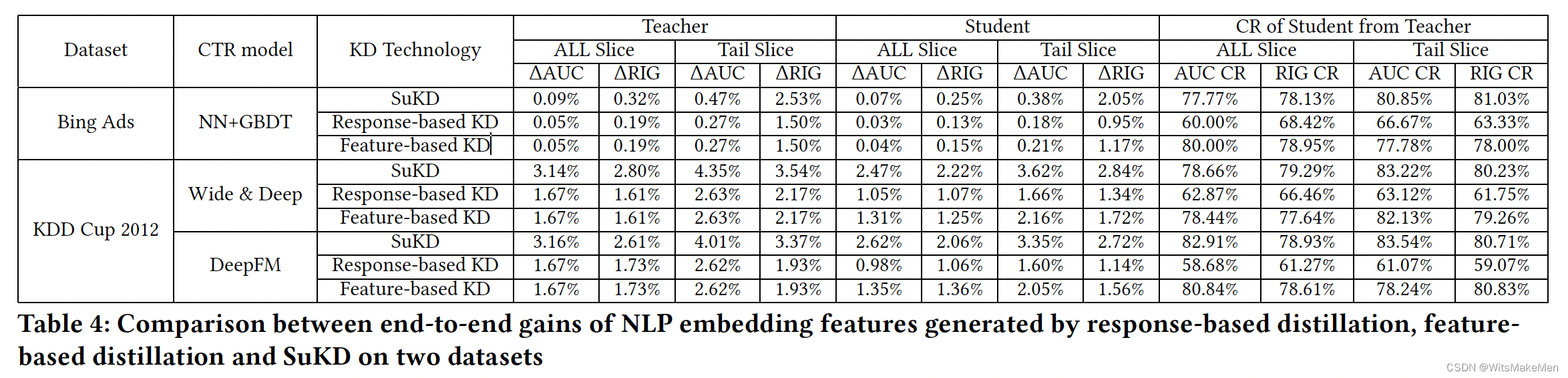
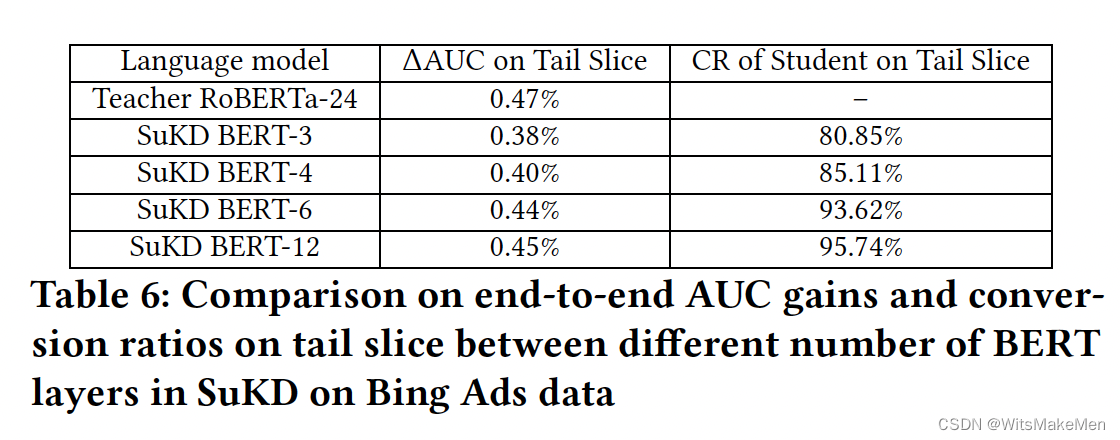
不同层数的bert蒸馏转化率对比
文章来源:https://blog.csdn.net/WitsMakeMen/article/details/135537308
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android Studio配置国内镜像源和HTTP代理/解决:Android Studio下载gradle速度慢的问题
- 本地搭建部署Canal笔记-实现MySQL与ElasticSearch7数据同步
- 网络安全B模块(笔记详解)- Web信息收集
- 积分商城小程序源码系统+会员积分功能 带完整的安装代码包以及安装部署教程
- 《思维与智慧》期刊发表投稿
- C++学习笔记--结构体
- 极智项目 | 实战Pytorch戴口罩检测
- go从0到1项目实战体系二十六:DB类与日志类
- 【C++】二叉搜索树
- 目标识别跟踪模块Tofu3