Day10 Liunx高级系统设计11-数据库2
发布时间:2023年12月17日
DQL:数据查询语言
查询全表
select * from 表名;
查询指定列
select
列名
1,
列名
2,… from
表名
;
条件查询
select * from
表名
where
条件
;
注意:
条件查询就是在查询时给出
WHERE
子句,在
WHERE
子句中可以使用如下运算符及关键
字:
=
、
!=
、
<>
、
<
、
<=
、
>
、
>=
BETWEEN…AND (
等价
<=
和
>=)
IN(set) (
包含
)
IS NULL (
非空
)
AND (
逻辑与
)
OR (
逻辑或
)
NOT (
逻辑非
)
XOR (
逻辑异或
)
示例
-- 查询成绩小于80的学员
select * from stu where score < 80;
-- 查询成绩等于100的学员
select * from stu where score = 100;
-- 查询成绩在85~100的学员
select * from stu where math between 80 and 100;
-- 查询姓名叫做“张三”或者“李四”的所有学生信息。
select * from stu where name beteween "张三" and "李四";
-- 查询成绩不小于80的学员
select * from stu where not score < 80;
-- 查询姓名不叫做“张三”或者“李四”的所有学生信息。
select * from stu where name not beteween "张三" and "李四";
-- 查询姓名叫做“张三”或者“李四”的所有学生信息。
select * from stu where name in ("张三","李四");
-- 查询成绩小于0或大于100的学员
select * from stu where score < 0 or score > 100;
-- 查询性别为空的学员
select * from stu where sex IS NULL;模糊查询
语法
当想查询姓名中包含
a
字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字
LIKE
。
_:
任意一个字母
%:
任意
0~n
个字母
'
张
%'
示例
-- 查找姓名为3个字母的学生信息
select * from stu where name like '___';//注意是3个_,表示匹配3个字符
-- 查找以字母b开头的学生信息
select * from stu where name like 'b%';
正则表达式
MySQL
同样也支持其他正则表达式的匹配,
MySQL
中使用
REGEXP
操作符来进行正则
表达式匹配。
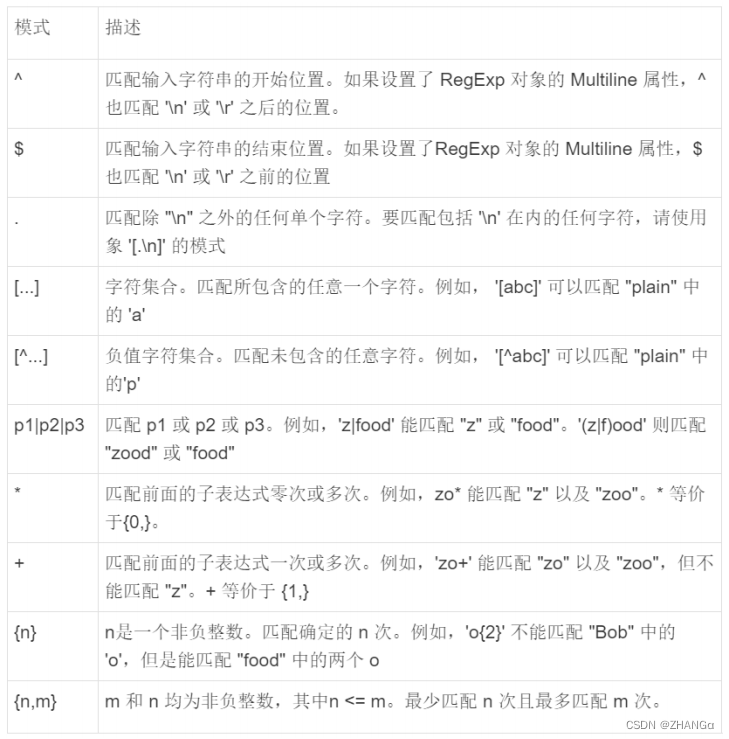
示例
--
查找姓名以
l
开头且以
y
结尾的学生信息
select
*
from
stu
where
name regexp
'^l'
and
name regexp
'y$'
;? ? ? ??
去重
关键字
:distinct
示例
--
查询
stu
表中
age
字段,剔除重复行
select distinct
age
from
stu;
计算列
对从数据表中查询的记录的列进行一定的运算之后显示出来
+,-,*,/,%
示例
--
出生年份
=
当前年份
-
年龄
select
stu_name,
2021
-stu_age
from
stus;
别名
如果在连接查询的多张表中存在相同名字的字段,我们可以使用
表名
.
字段名
来进行区
分,如果表名或字段名太长则不便于
SQL
语句的编写,我们可以使用数据表别名
示例
-- 字段起别名
select name AS 姓名 from stu;
-- 表名起别名
select s.name,s.sex from stu AS s;
-- AS可以省略
select name 姓名 from stu;
select s.name,s.sex from stu s;排序order by
将查询到的满足条件的记录按照指定的列的值升序
/
降序排列
语法:
select * from
表名
where
条件
order by
列名
asc|desc;
order by
列名 表示将查询结果按照指定的列排序
????????asc 按照指定的列升序(默认)
????????desc 按照指定的列降序
示例:
# 单字段排序
select * from stu where age>15 order by score desc;
# 多字段排序:先满足第一个排序规则,当第一个排序的列的值相同时再按照第二个列的
规则排序
select * from stus where age>15 order by score asc,age desc;聚合函数
聚合函数是用来做纵向运算的函数:
COUNT()
:统计指定列不为
NULL
的记录行数;
MAX()
:计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN()
:计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM()
:计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为
0
;
AVG()
:计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为
0
;
示例
-- 统计年龄大于20的学员人数
select count(*) as cnt from stu where age>20;
-- 统计学员的总年龄
select sum(age) from stu;
-- 统计学员的平均年龄以及总年龄
select sum(age),avg(age) from stu;
-- 统计学员的最低年龄以及最高年龄
select max(age),min(age) from stu;
-- 计算班级平均分
select avg(score) from stu;分组查询
分组:就是将数据表中的记录按指定的列进行分组
语法
select 分组字段/聚合函数
from 表名
[where 条件]
group by 分组列名 [having 条件]
[order by 排序字段]
注意
语句执行顺序:
1,
先根据
where
条件从数据库查询记录
2,group by
对查询记录进行分组
3,
执行
having
对分组后的数据进行筛选
4,
排序
示例
-- 先对查询的学生信息按性别进行分组(分成了男、女两组),然后再分别统计每组
学生的个数
select stu_gender,count(stu_num) from stus group by stu_gender;
-- 先对查询的学生信息按性别进行分组(分成了男、女两组),然后再计算每组的平
均年龄
select stu_gender,avg(stu_age) from stus group by stu_gender;
-- 先对学生按年龄进行分组,然后统计各组的学生数量,还可以对最终的结果排序
select stu_age,count(stu_num) from stus group by stu_age order by
stu_age;
-- 查询所有学生,按年龄进行分组,然后分别统计每组的人数,再筛选当前组人数>1
的组,再按年龄升序显示出来
select stu_age,count(stu_num)
from stus
group by stu_age
having count(stu_num)>1
order by stu_age;
-- 查询性别为'男'的学生,按年龄进行分组,然后分别统计每组的人数,再筛选当前组人
数>1的组,再按年龄升序显示出来
select stu_age,count(stu_num)
-> from stus
-> where stu_gender='男'
-> group by stu_age
-> having count(stu_num)>1
-> order by stu_age;
分页查询
语法
select
查询的字段
from
表名
where
条件
limit
param1,param2;
注意
:
- param1
:表示获取查询语句的结果中的第一条数据的索引(索引从
0
开始)
- param2
:表示获取的查询记录的条数(如果剩下的数据条数
<param2
,则返回剩下的
所有记录)
注意
--
示例
--
假如
:
对数据表中的学生信息进行分页显示,总共有
10
条数据,我们每页显示
3
条
--
总记录数:
`count 10`
--
每页显示:
`pageSize 3`
--
总页数:
`pageCount=count%pageSize==0?
count/pageSize:count/pageSize+1`
--
查询第一页:
select
*
from
stus [
where
...]
limit
0
,
3
; (
1
-
1
)*
3
--
查询第二页:
select
*
from
stus [
where
...]
limit
3
,
3
; (
2
-
1
)*
3
--
查询第三页:
select
*
from
stus [
where
...]
limit
6
,
3
; (
3
-
1
)*
3
--
查询第四页:
select
*
from
stus [
where
...]
limit
9
,
3
; (
4
-
1
)*
3
--
如果在一张数据表中:
-- pageNum
表示查询的页码
-- pageSize
表示每页显示的条数
--
通用分页语句如下:
select
*
from
stus [
where
...]
limit
(pageNum-
1
)*pageSize,pageSize;
约束
概念
在创建数据表的时候,指定的对数据表的列的数据限制性的要求(对表的列中的数据进行
限制)
作用
-
保证数据的有效性
-
保证数据的完整性
-
保证数据的正确性
分类
-
非空约束(
not null
):限制此列的值必须提供,不能为
null
-
唯一约束(
unique
):在表中的多条数据,此列的值不能重复
-
主键约束(
primary key
):非空
+
唯一,能够唯一标识数据表中的一条数据
-
自增长约束
(auto_increment):
每次
+1,
从
1
起
-
检查约束(
check
):保证列中的值满足某一条件
-
默认约束(
default
):保存数据时
,
未指定值则采用默认值
-
外键约束(
foreign key
):建立不同表之间的关联关系
非空约束
含义
:
限制数据表中此列的值必须提供
例子
:
创建图书表
,
设置书名
(book_name)
的不能为空
create table
books(
????????book_isbn
integer
,
????????book_isbn
char
(
4
),
????????book_name
varchar
(
10
)
not
null
,
????????book_author
varchar
(
6
)
);
唯一约束
含义
:
在表中的多条数据,此列的值不能重复
例子
:
创建图书表
,
设置国籍标准书号
(book_isbn)
的不能重复
create table
books(
????????book_id
integer
,
????????book_isbn
char
(
4
)
unique
,
????????book_name
varchar
(
10
)
not
null
,
????????book_author
varchar
(
6
)
);
检查约束
含义
:
保证列中的值满足某一条件
例子
:
创建用户表时
,
检查年龄在
0~200
岁
方式
1:
创建表时
create table
users(
u_id
integer
,
u_name
varchar
(
30
),
u_sex
char
(
10
),
u_age
int
,
check
(u_age >=
0
and
u_age <=
200
)
);
注意
:CHECK
子句会被分析,但是会被忽略。
原因
:CREATE TABLE
语法:接受这些子句但又忽略子句的原因是为了提高兼容性,以便更
容易地从其它
SQL
服务器中导入代码,并运行应用程序,创建带参考数据的表。
解决方案
:
枚举或触发器
默认约束
含义
:
保存数据时
,
未指定值则采用默认值
例子
:
创建图书表
,
设置封面地址默认为
xxx
create table
books(
book_id
integer
,
book_isbn
char
(
4
)
unique
,
book_name
varchar
(
10
)
not
null
,
book_author
varchar
(
6
),
book_img
varchar
(
100
)
default
'xxx'
);
主键约束
概念
就是数据表中记录的唯一标识,在一张表中只能有一个主键(主键可以是一个列,也可以
是多个列的组合)
含义
:
当一个字段声明为主键之后,添加数据时:
此字段数据不能为
null
此字段数据不能重复
例子
:
创建图书表
,
设置书籍
id(book_id)
create table
books(
????????book_id
integer
primary key
,
????????book_isbn
char
(
4
)
unique
,
????????book_name
varchar
(
10
)
not
null
,
????????book_author
varchar
(
6
)
);
或
create table
books(
????????book_id
integer
,
????????book_isbn
char
(
4
)
unique
,
????????book_name
varchar
(
10
)
not
null
,
????????book_author
varchar
(
6
),
????????primary key
(book_id)
);
删除数据表主键约束
#
语法
:alter table
表名
drop primary key;
#
如
:
alter table
books
drop primary key
;
创建表之后添加主键约束
#
语法
:alter table
表名
modify
字段名 数据类型
primary key;
#
如
:
alter table
books
modify
book_id
integer
primary key
;
自增长
在我们创建一张数据表时,如果数据表中有列可以作为主键(例如:学生表的学号、图书
表的
isbn
)我们可以直接这是这个列为主键;
当有些数据表中没有合适的列作为主键时,我们可以额外定义一个与记录本身无关的列
(
ID
)作为主键,此列数据无具体的含义主要用于标识一条记录,在
mysql
中我们可以将此
列定义为
int
,同时设置为
自动增长
,当我们向数据表中新增一条记录时,无需提供
ID
列的
值,它会自动生成
定义
int
类型字段自动增长:
auto_increment
例子
create table
types(
????????type_id
int
primary key auto_increment
,
????????type_name
varchar
(
20
)
not
null
,
????????type_remark
varchar
(
100
)
);
注意:自动增长从
1
开始,每添加一条记录,自动的增长的列会自定
+1
,当我们把某条记录
删除之后再添加数据,自动增长的数据也不会重复生成(自动增长只保证唯一性、不保证
连续性)
多表查询
语法:
select
列名
1,
列名
2,.. from
表
1,
表
2,.. where
判断语句
;
示例
--
查看
stu
和
grade
表中的学生学号、姓名、班级、成绩信息
select
s.*,g.*
from
stu s,grade g
where
s
.id
= g
.stu_id
;
注意
没有条件会出现笛卡尔积
视图:虚拟表
概念
视图,就是由数据库中一张表或者多张表根据特定的条件查询出得数据构造成得虚拟表
优点
安全性:
文章来源:https://blog.csdn.net/aisheisadas/article/details/135023793
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于uniapp X 的最新消息
- 数据库灾难应对:MySQL误删除数据的救赎之道,技巧get起来!之binlog
- Android14源码剖析:MediaPlayer与MediaPlayerService是一个服务吗?(五十四)
- 乙级 1002 写出这个数
- [网络安全]用户与组管理
- Java复习
- 计算机毕业设计------SSM游戏点评网站
- js reverse方法的使用
- 2023年中国法拍房用户画像和数据分析
- ssm基于web的物流配送管理系统的设计与实现+vue论文