015:JS之正则表达式,web乱码和路径问题总结,MVC架构模式
一 JS的正则表达式
1 正则表达式简介
正则表达式是描述字符模式的对象。正则表达式用于对字符串模式匹配及检索替换,是对字符串执行模式匹配的强大工具。
- 语法
var patt=new RegExp(pattern,modifiers);//正则的格式模版,修饰符
或者更简单的方式:
var patt=/pattern/modifiers;
修饰符
| 修饰符 | 描述 |
|---|---|
| i | 执行对大小写不敏感的匹配。 |
| g | 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。 |
| m | 执行多行匹配。 |
方括号
| 表达式 | 描述 |
|---|---|
| [abc] | 查找方括号之间的任何字符。 |
| [^abc] | 查找任何不在方括号之间的字符。 |
| [0-9] | 查找任何从 0 至 9 的数字。 |
| [a-z] | 查找任何从小写 a 到小写 z 的字符。 |
| [A-Z] | 查找任何从大写 A 到大写 Z 的字符。 |
| [A-z] | 查找任何从大写 A 到小写 z 的字符。 |
| [adgk] | 查找给定集合内的任何字符。 |
| [^adgk] | 查找给定集合外的任何字符。 |
| (red|blue|green) | 查找任何指定的选项。 |
元字符
| 元字符 | 描述 |
|---|---|
. | 查找单个字符,除了换行和行结束符。 |
| \w | 查找数字、字母及下划线。 |
| \W | 查找非单词字符。 |
| \d | 查找数字。 |
| \D | 查找非数字字符。 |
| \s | 查找空白字符。 |
| \S | 查找非空白字符。 |
| \b | 匹配单词边界。 |
| \B | 匹配非单词边界。 |
| \0 | 查找 NULL 字符。 |
| \n | 查找换行符。 |
| \f | 查找换页符。 |
| \r | 查找回车符。 |
| \t | 查找制表符。 |
| \v | 查找垂直制表符。 |
| \xxx | 查找以八进制数 xxx 规定的字符。 |
| \xdd | 查找以十六进制数 dd 规定的字符。 |
| \uxxxx | 查找以十六进制数 xxxx 规定的 Unicode 字符。 |
量词
| 量词 | 描述 |
|---|---|
| n+ | 匹配任何包含至少一个 n 的字符串。例如,/a+/ 匹配 “candy” 中的 “a”,“caaaaaaandy” 中所有的 “a”。 |
| n* | 匹配任何包含零个或多个 n 的字符串。例如,/bo*/ 匹配 “A ghost booooed” 中的 “boooo”,“A bird warbled” 中的 “b”,但是不匹配 “A goat grunted”。 |
| n? | 匹配任何包含零个或一个 n 的字符串。例如,/e?le?/ 匹配 “angel” 中的 “el”,“angle” 中的 “le”。 |
| n{X} | 匹配包含 X 个 n 的序列的字符串。例如,/a{2}/ 不匹配 “candy,” 中的 “a”,但是匹配 “caandy,” 中的两个 “a”,且匹配 “caaandy.” 中的前两个 “a”。 |
| n{X,} | X 是一个正整数。前面的模式 n 连续出现至少 X 次时匹配。例如,/a{2,}/ 不匹配 “candy” 中的 “a”,但是匹配 “caandy” 和 “caaaaaaandy.” 中所有的 “a”。 |
| n{X,Y} | X 和 Y 为正整数。前面的模式 n 连续出现至少 X 次,至多 Y 次时匹配。例如,/a{1,3}/ 不匹配 “cndy”,匹配 “candy,” 中的 “a”,“caandy,” 中的两个 “a”,匹配 “caaaaaaandy” 中的前面三个 “a”。注意,当匹配 “caaaaaaandy” 时,即使原始字符串拥有更多的 “a”,匹配项也是 “aaa”。 |
| n$ | 匹配任何结尾为 n 的字符串。 |
| ^n | 匹配任何开头为 n 的字符串。 |
| ?=n | 匹配任何其后紧接指定字符串 n 的字符串。 |
| ?!n | 匹配任何其后没有紧接指定字符串 n 的字符串。 |
RegExp对象方法
| 方法 | 描述 |
|---|---|
| compile | 在 1.5 版本中已废弃。 编译正则表达式。 |
| exec | 检索字符串中指定的值。返回找到的值,并确定其位置。 |
| test | 检索字符串中指定的值。返回 true 或 false。 |
| toString | 返回正则表达式的字符串。 |
支持正则的String的方法
| 方法 | 描述 |
|---|---|
| search | 检索与正则表达式相匹配的值。 |
| match | 找到一个或多个正则表达式的匹配。 |
| replace | 替换与正则表达式匹配的子串。 |
| split | 把字符串分割为字符串数组。 |
2 正则表达式体验
2.1 验证
注意:这里是使用正则表达式对象来调用方法。
/* test(): 检索字符串中指定的值。返回 true 或 false。 */
// 创建一个最简单的正则表达式对象
var reg = /o/; //查找为o的字符
// 创建一个字符串对象作为目标字符串
var str = 'Hello World!';
// 调用正则表达式对象的test()方法验证目标字符串是否满足我们指定的这个模式,返回结果true
console.log("/o/.test('Hello World!')="+reg.test(str));
2.2 匹配
注意:这里是使用字符串对象来调用方法。
/* match():找到一个或多个正则表达式的匹配。 */
// 创建一个最简单的正则表达式对象
//默认是只匹配到第一个,可以加上修饰符g进行全局匹配 var reg = /o/g;
var reg = /o/;
// 创建一个字符串对象作为目标字符串
var str = 'Hello World!';
// 在目标字符串中查找匹配的字符,返回匹配结果组成的数组
var resultArr = str.match(reg);
// 数组长度为1
console.log("resultArr.length="+resultArr.length);
// 数组内容是o
console.log("resultArr[0]="+resultArr[0]);
2.3 替换
注意:这里是使用字符串对象来调用方法。
/* replace(): 替换与正则表达式匹配的子串。 */
// 创建一个最简单的正则表达式对象
//var reg = /o/gi; 把为o的字符替换掉,并且是全局匹配(g)不区分大小写(i)
var reg = /o/;
// 创建一个字符串对象作为目标字符串
var str = 'Hello World!';
var newStr = str.replace(reg,'@');
// 只有第一个o被替换了,说明我们这个正则表达式只能匹配第一个满足的字符串
console.log("str.replace(reg)="+newStr);//Hell@ World!
// 原字符串并没有变化,只是返回了一个新字符串
console.log("str="+str);//str=Hello World!
2.4 全文查找
如果不使用g对正则表达式对象进行修饰,则使用正则表达式进行查找时,仅返回第一个匹配;使用g后,返回所有匹配。
// 目标字符串
var targetStr = 'Hello World!';
// 没有使用全局匹配的正则表达式
var reg = /[A-Z]/; //查找任何从大写 A 到大写 Z 的字符。
// 获取全部匹配
var resultArr = targetStr.match(reg);
// 数组长度为1
console.log("resultArr.length="+resultArr.length);
// 遍历数组,发现只能得到'H'
for(var i = 0; i < resultArr.length; i++){
console.log("resultArr["+i+"]="+resultArr[i]);
}
对比
// 目标字符串
var targetStr = 'Hello World!';
// 使用了全局匹配的正则表达式
var reg = /[A-Z]/g;
// 获取全部匹配
var resultArr = targetStr.match(reg);
// 数组长度为2
console.log("resultArr.length="+resultArr.length);
// 遍历数组,发现可以获取到“H”和“W”
for(var i = 0; i < resultArr.length; i++){
console.log("resultArr["+i+"]="+resultArr[i]);
}
2.5 忽略大小写
//目标字符串
var targetStr = 'Hello WORLD!';
//没有使用忽略大小写的正则表达式
var reg = /o/g;
//获取全部匹配
var resultArr = targetStr.match(reg);
//数组长度为1
console.log("resultArr.length="+resultArr.length);
//遍历数组,仅得到'o'
for(var i = 0; i < resultArr.length; i++){
console.log("resultArr["+i+"]="+resultArr[i]);
}
对比
//目标字符串
var targetStr = 'Hello WORLD!';
//使用了忽略大小写的正则表达式
var reg = /o/gi;
//获取全部匹配
var resultArr = targetStr.match(reg);
//数组长度为2
console.log("resultArr.length="+resultArr.length);
//遍历数组,得到'o'和'O'
for(var i = 0; i < resultArr.length; i++){
console.log("resultArr["+i+"]="+resultArr[i]);
}
2.6 量词使用
/* n$:匹配任何结尾为 n 的字符串。
^n:匹配任何开头为 n 的字符串。
*/
var str01 = 'I love Java';
var str02 = 'Java love me';
// 匹配以Java开头
var reg = /^Java/g;
console.log('reg.test(str01)='+reg.test(str01)); // false
console.log("<br />");
console.log('reg.test(str02)='+reg.test(str02)); // true
var str01 = 'I love Java';
var str02 = 'Java love me';
// 匹配以Java结尾
var reg = /Java$/g;
console.log('reg.test(str01)='+reg.test(str01)); // true
console.log("<br />");
console.log('reg.test(str02)='+reg.test(str02)); // false
var str01 = 'I love Java';
var str02 = 'Java love me';
var str03 = 'Java';
// 匹配以Java开头立刻以java结尾的字符串
var reg = /^Java$/g;
console.log('reg.test(str01)='+reg.test(str01)); // false
console.log('reg.test(str02)='+reg.test(str02)); // false
console.log('reg.test(str03)='+reg.test(str03)); // true
/*
var reg = /^a$/; 匹配以a开头,立刻以a结尾的字符。
如果在正则表达式中同时使用^$则要求字符串必须完全符合正则表达式
*/
var str01 = 'a';
var str02 = 'aa';
var reg = /^a$/;
console.log('reg.test(str01)='+reg.test(str01)); // true
console.log('reg.test(str02)='+reg.test(str02)); // false
/*
var reg = /^a|a$/;
这个才是 以a开头或者以a结尾的正则表达式
*/
var str03 = 'a';
var str04 = 'aa';
var reg = /^a|a$/;
console.log('reg.test(str03)='+reg.test(str03)); // true
console.log('reg.test(str04)='+reg.test(str04)); // true
说明:
- 正则表达式一般都是以什么什么为开头,所以加上^。
- 以什么什么为结尾或者结尾后没有其它数据了,所以加上$。
- 总结:一般写正则表达式的时候都会加上^$开头和结尾,好处:这样可以用正则对整个字符串的长度有一个明确的限制,因为它既要求开头又要求结尾不就是要求整个字符串里面有什么吗。所以一般都会加上开头和结尾以方便用正则校验一个字符串中的长度问题。
2.7 字符集合的使用
/* 需求:
校验用户名是否合法
要求:
1 必须是字母开头
2 长度必须是6-10为
3 后面其他字符可以是大小写字母,数字和下划线
分析:
第一位规则:字母开头(没说肯定是不区分大小写) ^[a-zA-Z] 一个[]代表一位 一个字符
第二位规则:后面其他字符可以是大小写字母,数字和下划线 [a-zA-Z0-9_]
剩余位规则:分析可知剩余位的比较规则和第二位的相同,所以只需要让第二位的规则重复出现即可。
整个字符长度要求6-10,前面已经占一位了,所以只需要重复出现5-9次即可。
即:[a-zA-Z0-9_]{5,9} {}定义前面这一位的规则可以重复几遍。
后面没有其它的数据了,所以以$结尾。
最终效果为:^[a-zA-Z] [a-zA-Z0-9_]{5,9} $
*/
var ss = 'asdfqwer';
var reg = /^[a-zA-Z][a-zA-Z0-9_]{5,9}$/;
console.log(reg.test(ss));//true
2.8 常用正则表达式
| 需求 | 正则表达式 |
|---|---|
| 用户名 | /^[a-zA-Z ][a-zA-Z-0-9]{5,9}$/ |
| 密码 | /^[a-zA-Z0-9 _-@#& *]{6,12}$/ |
| 前后空格 | /^\s+|\s+$/g |
| 电子邮箱 | /^[a-zA-Z0-9 _.-]+@([a-zA-Z0-9-]+[.]{1})+[a-zA-Z]+$/ |
电子邮箱解释:
1234@qq.com
xiaoming@123.com.cn
/^[a-zA-Z0-9 _.-]+@([a-zA-Z0-9-]+[.]{1})+[a-zA-Z]+$/
xiaoming @123.com. cn
/^[a-zA-Z0-9 _.-]+ @([a-zA-Z0-9-]+[.]{1})+ [a-zA-Z]+$/
@之前的:可以是字母 数字 下划线 点 分隔符 +表示前面的比较规则至少出现一次 []代表一位一个字符
@到.之间的:[a-zA-Z0-9-]+ 字符数字最少出现一次 c co com
[.]{1} .只能出现一次,不能连着. ..
[a-zA-Z0-9-]+[.]{1} 可以是co. 可以是com. 不能是com..
([a-zA-Z0-9-]+[.]{1})+ 作为整体至少出现一次 com.com. 123.com.
@([a-zA-Z0-9-]+[.]{1})+ @com.com. @123.com.
.之后的:最后可以是以字母为结尾 + 里面的字符规则至少出现一次
说明:
- 开发中需要正则表达式来校验一些手机号 邮箱之类的数据是否满足格式,可以直接打开浏览器搜索对应的手机号正则,身份证好正则,邮箱正则,复制过来后可能不是完全满足,我们只需要稍微修改下即可。
二 web乱码和路径问题总结
10.1 乱码问题
乱码问题产生的根本原因是什么
-
数据的编码和解码使用的不是同一个字符集
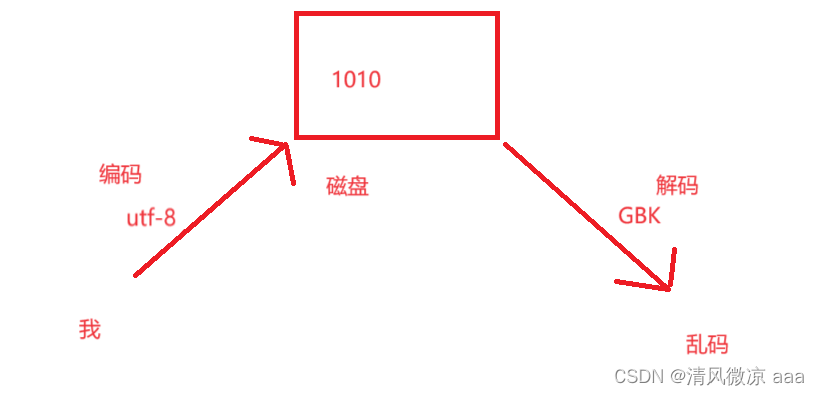
- 计算机无论存储什么样的数据最终到磁盘上都是1010这样的二进制数据,我们人看懂得是字符,把字符存储到磁盘中就需要把字符转化为1010二进制数据,那么如何转化呢?
- 想要转化肯定需要一个关系对照表,即字符集编码表。
- 字符集编码表就好比是一个字典,它记录着字符和二进制数据对应的关系,世界上有很多不同的字符集,不同的字符集的对应规则不同,比如:1010在欧洲的字符集中可能是 你好,1010在美国的字符集是 谢谢 的意思。
- 这个时候你使用utf-8进行编码,将这个汉字转化为1010存储到计算机中,之后在解码的时候通过GBK来找1010对应的汉字,此时就会出现乱码。
-
使用了不支持某个语言文字的字符集
- eg:ASCII编码表只支持英文,不支持中文,此时使用中文进行编解码操作就会出现乱码。
各个字符集的兼容性
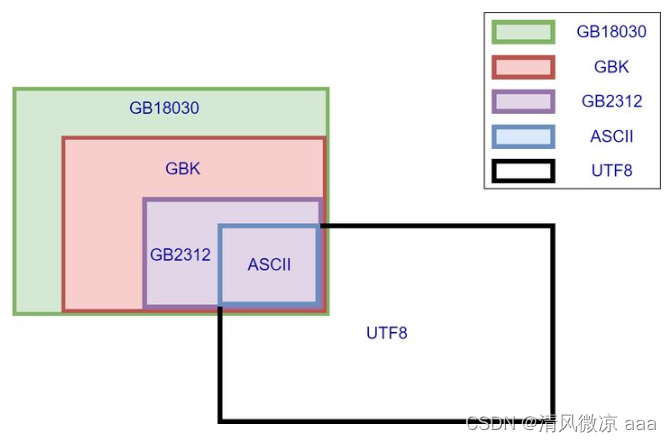
- 由上图得知,上述字符集都兼容了ASCII
- ASCII中有什么? 英文字母和一些通常使用的符号,所以这些东西无论使用什么字符集都不会乱码
10.1.1 HTML乱码问题
出现场景:
- 编码:idea中设置了字符编码为GBK,所以编写的html文件也为GBK类型。
- 解码:通过此标签设置浏览器解析时使用utf-8解码,此时就会出现乱码。
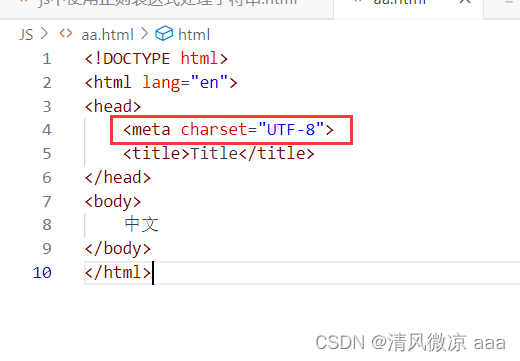
- 解决:编码和解码使用同一种支持中文的字符集。
演示:
设置项目文件的字符集要使用一个支持中文的字符集
- 查看当前文件的字符集

- 查看项目字符集配置,将Global Encoding 全局字符集,Project Encoding 项目字符集,Properties Files 属性配置文件字符集(配置文件一般要写一些中文的注释,所以字符集要包含中文)设置为UTF-8

当前视图文件的字符集通过
<meta charset="UTF-8">来告知浏览器通过什么字符集来解析当前文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
中文
</body>
</html>
10.1.2 Tomcat控制台乱码
举例1:
出现场景:
- Tomact日志打印的编码 默认使用的是utf-8编码,当前所装的操作系统是中文操作系统 ,中文操作系统的Dos窗口默认用的是GBK。
- 启动tomact的时候产生的日志用的是utf-8,这些日志在Dos窗口解码展示的时候,由于Dos窗口默认是GBK,所以此时就会出现乱码。
解决:(tomact日志产生默认是utf-8、Dos窗口默认是GBK)
- 方案一:修改Dos窗口解码的时候为utf-8,这样2个用的都是同一种编码表utf-8,不会出现乱码 (
不推荐)- 因为不应该让系统环境适应tomact,而是让tomact适应系统环境,你的系统环境不一定只装tomact,一旦系统环境适应了tomact不就适应不了其他的软件吗。
- 方案二:修改tomact产生日志 编码的时候为GBK,这样2个使用的都是GBK,则不会出现中文乱码。(
推荐)
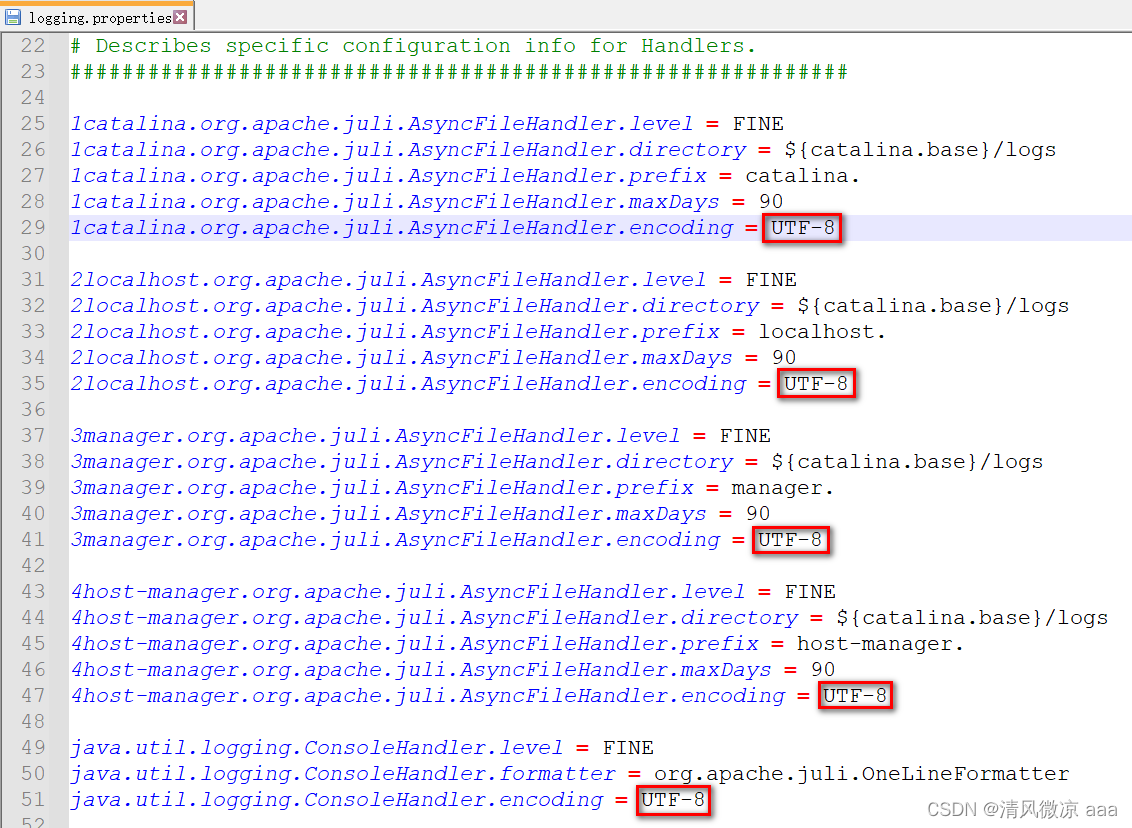
在tomcat10.1.7这个版本中,修改
tomcat/conf/logging.properties中,所有的UTF-8为GBK即可
-
修改前
-
修改后

-
重启测试 (中文的操作系统默认用的是GBK)
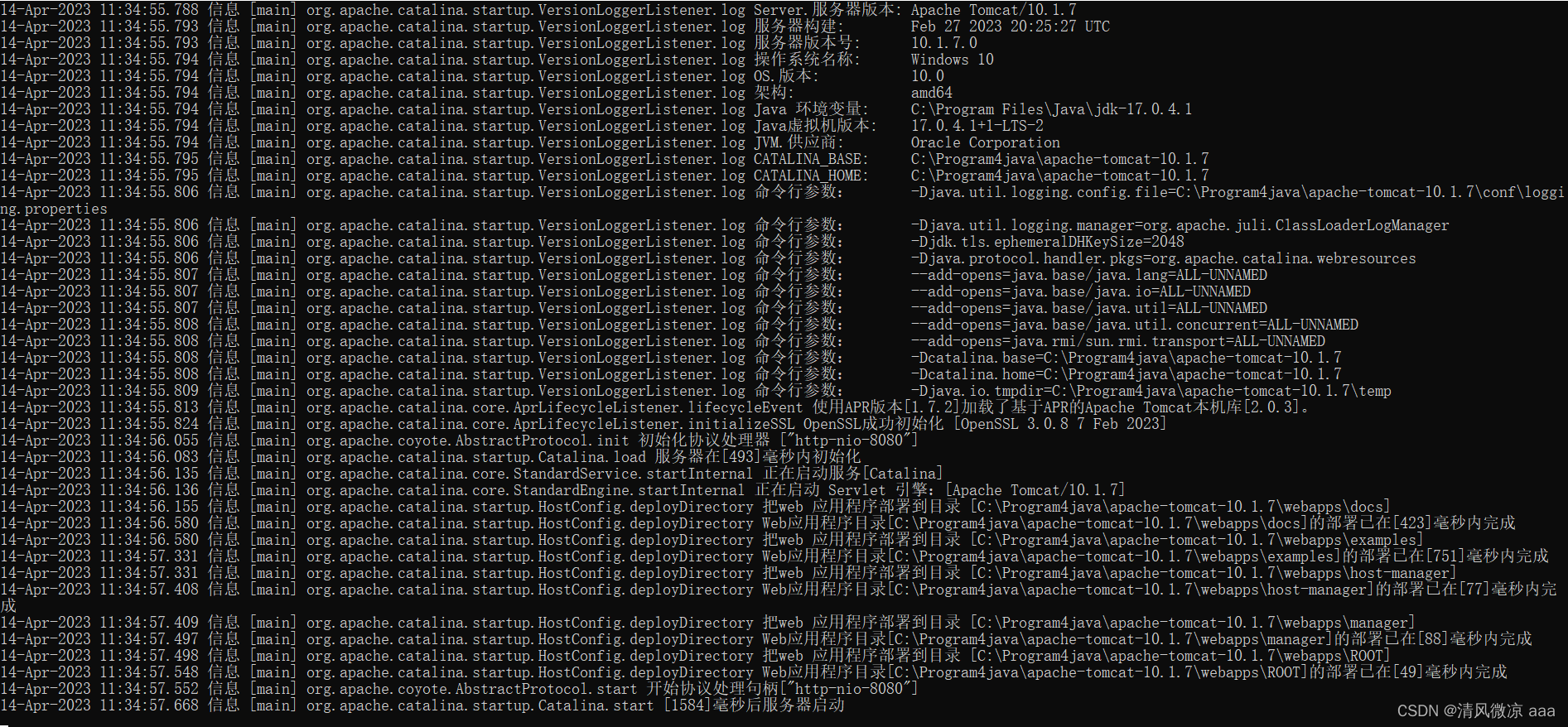
举例2:
idea控制台的乱码默认可能是utf-8,所以如果没有出现乱码就不要改这个tomact配置文件的字符集了(tomact默认是utf-8)。

举例3:
sout输出乱码问题:虚拟机加载.class文件的字符集和编译时使用的字符集不一致所造成的。
解释:
-
.java经过编译变为.class字节码文件:编译的过程中比如使用GBK进行编码
- 一般在idea中设置好后的编码为utf-8,那么在编译的时候也是utf-8.
-
.class字节码文件会被加载到虚拟机:加载的时候比如使用utf-8的字符集来解码的,此时就会出现sout乱码。
- 运行字节码文件用jvm的虚拟机,一般来自于自己安装的jdk中携带的,你安装的jdk字符集可能就不受idea的控制 ,使用别的字符集对字节码文件进行加载。
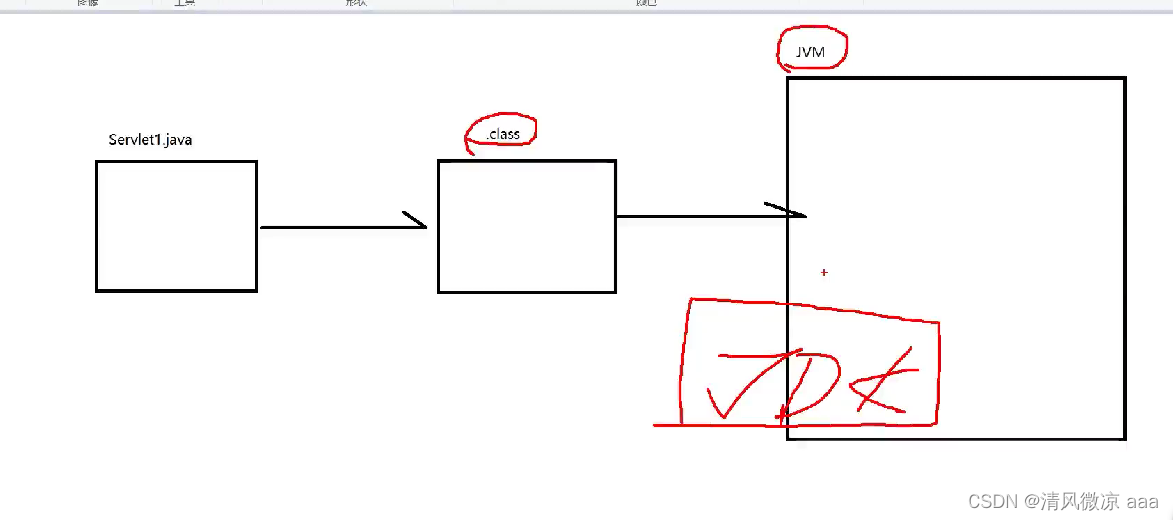
- 运行字节码文件用jvm的虚拟机,一般来自于自己安装的jdk中携带的,你安装的jdk字符集可能就不受idea的控制 ,使用别的字符集对字节码文件进行加载。
-
解决:告诉jvm用指定的字符集来加载字节码文件。
- 设置虚拟机加载.class文件的字符集和编译时使用的字符集一致
- 设置JVM加载.class文件时使用UTF-8字符集
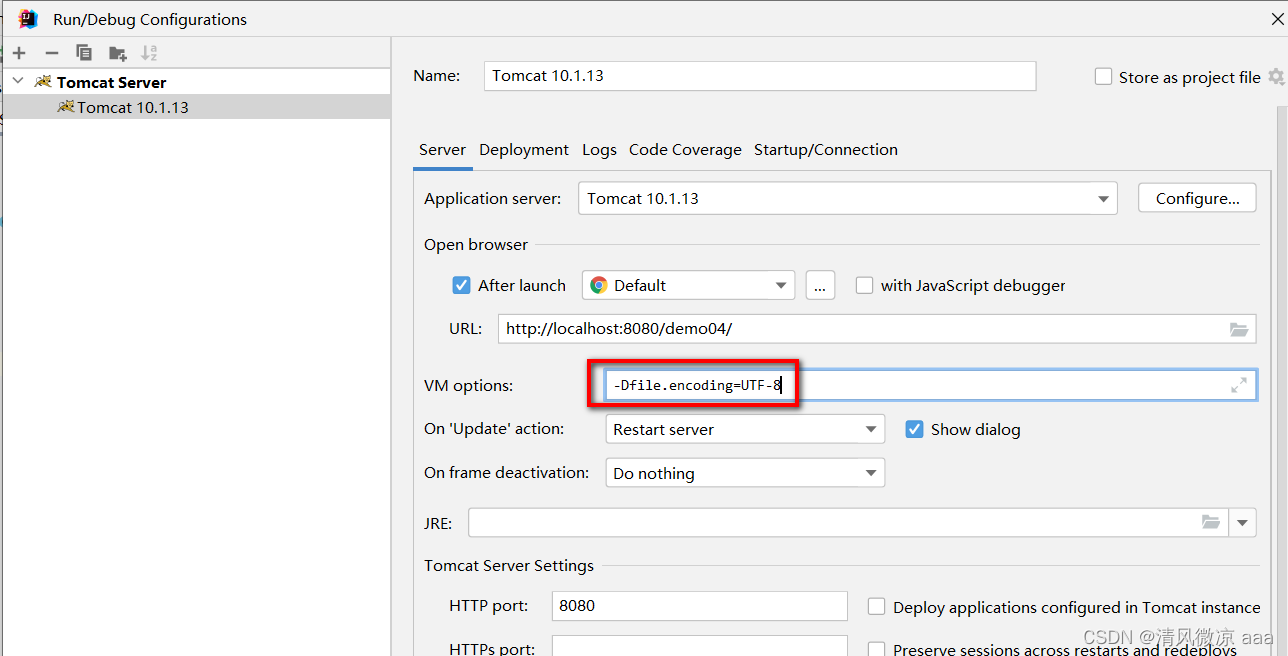
10.1.3 请求乱码问题
10.1.3.1 GET请求乱码
GET请求方式乱码分析
- GET方式提交参数的方式是将参数放到URL后面,如果使用的不是UTF-8,那么会对参数进行URL编码处理
- HTML中的
<meta charset='字符集'/>影响了GET方式提交参数的URL编码 - tomcat10.1.7的URI编码默认为 UTF-8
- 当GET方式提交的参数URL编码和tomcat10.1.7默认的URI编码不一致时,就会出现乱码
GET请求方式乱码演示
-
浏览器解析的文档的
<meta charset="GBK" />

-
GET方式提交时,会对数据进行URL编码处理 ,是将GBK 转码为 “百分号码”

- tomcat10.1.7 默认使用UTF-8对URI进行解析,造成前后端使用的字符集不一致,出现乱码

GET请求方式乱码解决
-
方式1 :设置GET方式提交的编码和Tomcat10.1.7的URI默认解析编码一致即可 (推荐)
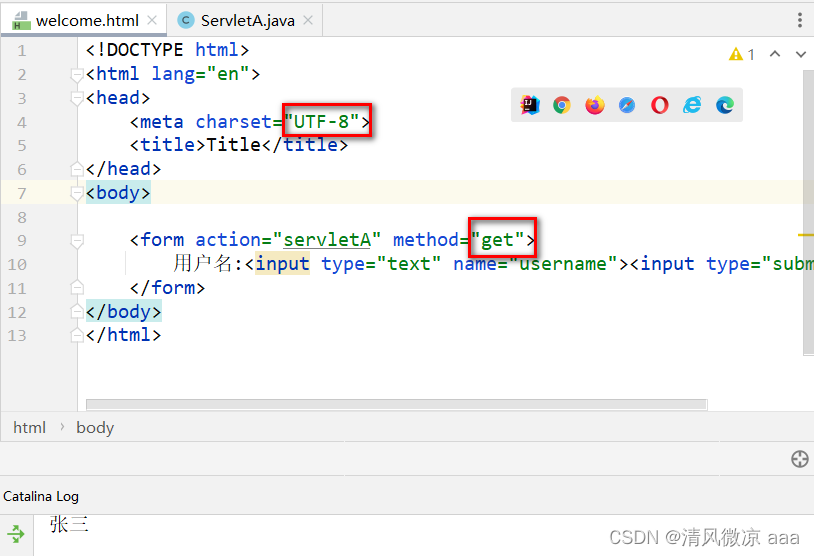

-
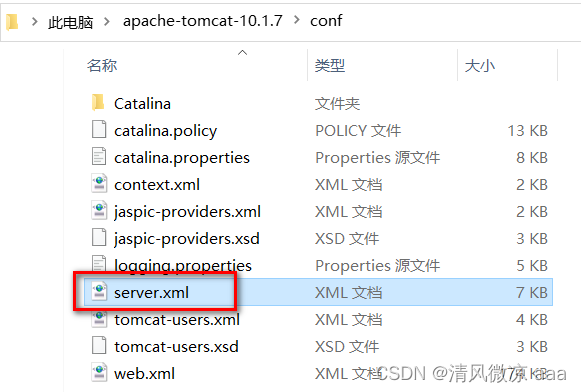
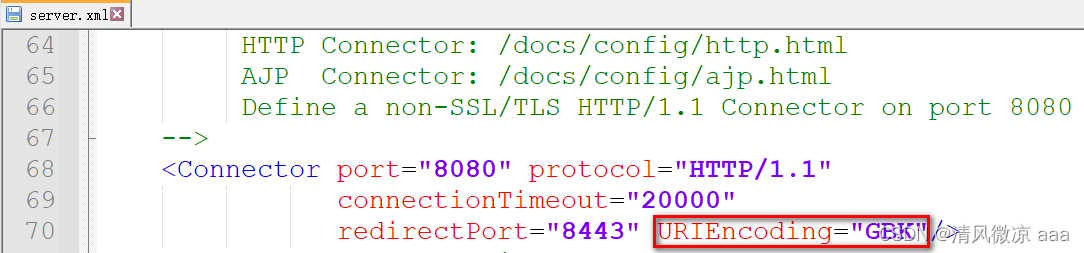
方式2 : 设置Tomcat10.1.7的URI解析字符集和GET请求发送时所使用URL转码时的字符集一致即可,修改conf/server.xml中 Connecter 添加 URIEncoding=“GBK” (不推荐)
10.1.3.2 POST方式请求乱码
POST请求方式乱码分析
- POST请求将参数放在请求体中进行发送
- 请求体使用的字符集受到了
<meta charset="字符集"/>的影响 - Tomcat10.1.7 默认使用UTF-8字符集对请求体进行解析
- 如果请求体的URL转码和Tomcat的请求体解析编码不一致,就容易出现乱码
POST方式乱码演示
-
POST请求请求体受到了
<meta charset="字符集"/>的影响

-
请求体中,将GBK数据进行 URL编码

-
后端默认使用UTF-8解析请求体,出现字符集不一致,导致乱码
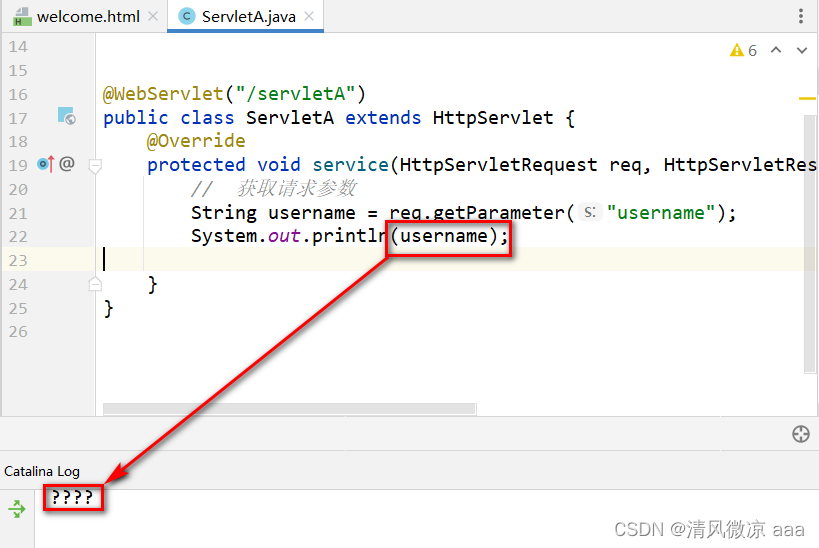
POST请求方式乱码解决
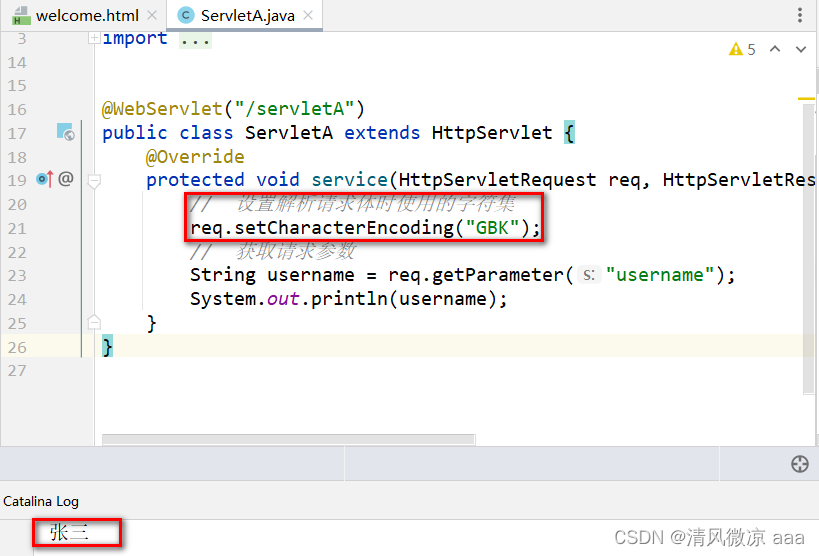
-
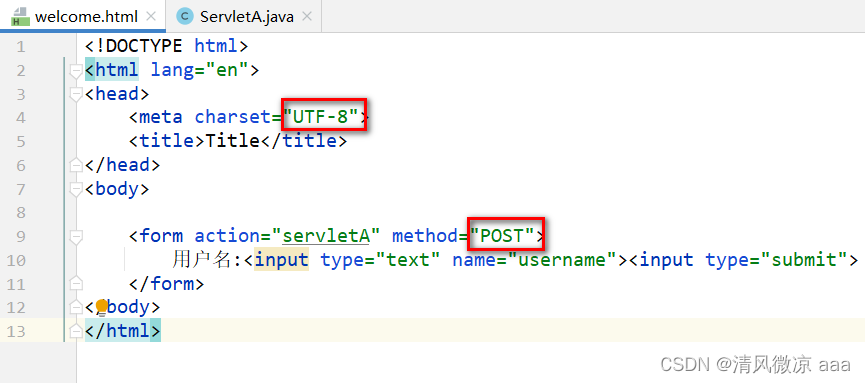
方式1 : 请求时,使用UTF-8字符集提交请求体 (推荐)
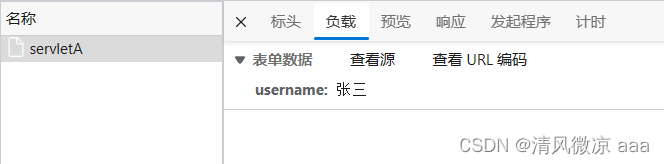
-
方式2 : 后端在获取参数前,设置解析请求体使用的字符集和请求发送时使用的字符集一致 (不推荐)
10.1.3 响应乱码问题
响应乱码分析
- 在Tomcat10.1.7中,向响应体中放入的数据默认使用了工程编码 UTF-8
- 浏览器在接收响应信息时,使用了不同的字符集或者是不支持中文的字符集就会出现乱码
响应乱码演示
-
服务端通过response对象向响应体添加数据

-
浏览器接收数据解析乱码

响应乱码解决
-
方式1 : 手动设定浏览器对本次响应体解析时使用的字符集(不推荐)
- edge和 chrome浏览器没有提供直接的比较方便的入口,不方便
-
方式2:后端通过设置响应体的字符集和浏览器解析响应体的默认字符集一致(不推荐)
- 因为前端浏览器可能是外国访问的,用的不是gbk,此时你后端使用了jdk不就又出现了乱码吗。

- 因为前端浏览器可能是外国访问的,用的不是gbk,此时你后端使用了jdk不就又出现了乱码吗。
- 方式3:通过设置content-type响应头,告诉浏览器以指定的字符集解析响应体(推荐)
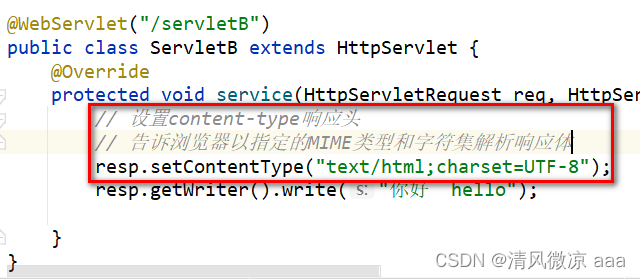

10.2 路径问题
相对路径和绝对路径
-
相对路径
- 相对路径的规则是: 以当前资源所在的路径为出发点去寻找目标资源
- 相对路径不以 / 开头
- 在file协议下,使用的是磁盘路径
- 在http协议下,使用的是url路径
- 相对路径中可以使用 ./表示当前资源所在路径,可以省略不写
- 相对路径中可以使用…/表示当前资源所在路径的上一层路径,需要时要手动添加
-
绝对路径
- 绝对路径的规则是: 使用以一个固定的路径做出出发点去寻找目标资源,和当前资源所在的路径没有关系
- 绝对路径要以/ 开头
- 绝对路径的写法中,不以当前资源的所在路径为出发点,所以不会出现 ./ 和…/
- 不同的项目和不同的协议下,绝对路径的基础位置可能不同,要通过测试确定
- 绝对路径的好处就是:无论当前资源位置在哪,寻找目标资源路径的写法都一致
-
应用场景
- 前端代码中,href src action 等属性
- 请求转发和重定向中的路径
10.2.1 前端路径问题
前端项目结构
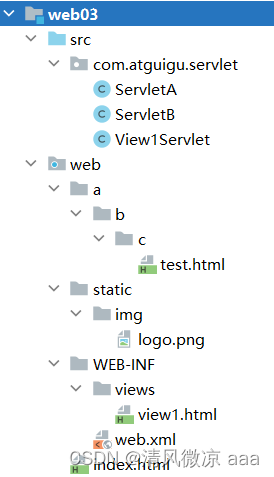
10.2.1.1 相对路径情况分析
相对路径情况1:web/index.html中引入web/static/img/logo.png
- 访问index.html的url为 : http://localhost:8080/web03_war_exploded/index.html
- 当前资源为 : index.html
- 当前资源的所在路径为 : http://localhost:8080/web03_war_exploded/
- 要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/static/img/logo.png
- index.html中定义的了 :
<img src="static/img/logo.png"/> - 寻找方式就是在当前资源所在路径(http://localhost:8080/web03_war_exploded/)后拼接src属性值(static/img/logo.png),正好是目标资源正常获取的url(http://localhost:8080/web03_war_exploded/static/img/logo.png)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<img src="static/img/logo.png">
</body>
</html>
相对路径情况2:web/a/b/c/test.html中引入web/static/img/logo.png
- 访问test.html的url为 : http://localhost:8080/web03_war_exploded/a/b/c/test.html
- 当前资源为 : test.html
- 当前资源的所在路径为 : http://localhost:8080/web03_war_exploded/a/b/c/
- 要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/static/img/logo.png
- test.html中定义的了 :
<img src="../../../static/img/logo.png"/> - 寻找方式就是在当前资源所在路径(http://localhost:8080/web03_war_exploded/a/b/c/)后拼接src属性值(…/…/…/static/img/logo.png),其中 …/可以抵消一层路径,正好是目标资源正常获取的url(http://localhost:8080/web03_war_exploded/static/img/logo.png)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- ../代表上一层路径 -->
<img src="../../../static/img/logo.png">
</body>
</html>
相对路径情况3:web/WEB-INF/views/view1.html中引入web/static/img/logo.png
- view1.html在WEB-INF下,需要通过Servlet请求转发获得
@WebServlet("/view1Servlet")
public class View1Servlet extends HttpServlet {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
RequestDispatcher requestDispatcher = req.getRequestDispatcher("WEB-INF/views/view1.html");
requestDispatcher.forward(req,resp);
}
}
- 访问view1.html的url为 : http://localhost:8080/web03_war_exploded/view1Servlet
- 当前资源为 : view1Servlet
- 当前资源的所在路径为 : http://localhost:8080/web03_war_exploded/
- 要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/static/img/logo.png
- view1.html中定义的了 :
<img src="static/img/logo.png"/> - 寻找方式就是在当前资源所在路径(http://localhost:8080/web03_war_exploded/)后拼接src属性值(static/img/logo.png),正好是目标资源正常获取的url(http://localhost:8080/web03_war_exploded/static/img/logo.png)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<img src="static/img/logo.png">
</body>
</html>
10.2.1.2 绝对路径情况分析
绝对路径情况1:web/index.html中引入web/static/img/logo.png
- 访问index.html的url为 : http://localhost:8080/web03_war_exploded/index.html
- 绝对路径的基准路径为 : http://localhost:8080
- 要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/static/img/logo.png
- index.html中定义的了 :
<img src="/web03_war_exploded/static/img/logo.png"/> - 寻找方式就是在基准路径(http://localhost:8080)后面拼接src属性值(/web03_war_exploded/static/img/logo.png),得到的正是目标资源访问的正确路径
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- 绝对路径写法 -->
<img src="/web03_war_exploded/static/img/logo.png">
</body>
</html>
绝对路径情况2:web/a/b/c/test.html中引入web/static/img/logo.png
- 访问test.html的url为 : http://localhost:8080/web03_war_exploded/a/b/c/test.html
- 绝对路径的基准路径为 : http://localhost:8080
- 要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/static/img/logo.png
- test.html中定义的了 :
<img src="/web03_war_exploded/static/img/logo.png"/> - 寻找方式就是在基准路径(http://localhost:8080)后面拼接src属性值(/web03_war_exploded/static/img/logo.png),得到的正是目标资源访问的正确路径
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- 绝对路径写法 -->
<img src="/web03_war_exploded/static/img/logo.png">
</body>
</html>
绝对路径情况3:web/WEB-INF/views/view1.html中引入web/static/img/logo.png
- view1.html在WEB-INF下,需要通过Servlet请求转发获得
@WebServlet("/view1Servlet")
public class View1Servlet extends HttpServlet {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
RequestDispatcher requestDispatcher = req.getRequestDispatcher("WEB-INF/views/view1.html");
requestDispatcher.forward(req,resp);
}
}
- 访问view1.html的url为 : http://localhost:8080/web03_war_exploded/view1Servlet
- 绝对路径的基准路径为 : http://localhost:8080
- 要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/static/img/logo.png
- view1.html中定义的了 :
<img src="/web03_war_exploded/static/img/logo.png"/> - 寻找方式就是在基准路径(http://localhost:8080)后面拼接src属性值(/static/img/logo.png),得到的正是目标资源访问的正确路径
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<img src="/web03_war_exploded/static/img/logo.png">
</body>
</html>
10.2.1.3 base标签的使用
base标签定义页面相对路径公共前缀
- base 标签定义在head标签中,用于定义相对路径的公共前缀
- base 标签定义的公共前缀只在相对路径上有效,绝对路径中无效
- 如果相对路径开头有 ./ 或者…/修饰,则base标签对该路径同样无效
index.html 和a/b/c/test.html 以及view1Servlet 中的路径处理
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<!--定义相对路径的公共前缀,将相对路径转化成了绝对路径-->
<base href="/web03_war_exploded/">
</head>
<body>
<img src="static/img/logo.png">
</body>
</html>
10.2.1.4 缺省项目上下文路径
项目上下文路径变化问题
- 通过 base标签虽然解决了相对路径转绝对路径问题,但是base中定义的是项目的上下文路径
- 项目的上下文路径是可以随意变化的
- 一旦项目的上下文路径发生变化,所有base标签中的路径都需要改
解决方案
- 将项目的上下文路径进行缺省设置,设置为 /,所有的绝对路径中就不必填写项目的上下文了,直接就是/开头即可
10.2.2 重定向中的路径问题
目标 :由/x/y/z/servletA重定向到a/b/c/test.html
@WebServlet("/x/y/z/servletA")
public class ServletA extends HttpServlet {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
}
10.2.2.1相对路径写法
- 访问ServletA的url为 : http://localhost:8080/web03_war_exploded/x/y/z/servletA
- 当前资源为 : servletA
- 当前资源的所在路径为 : http://localhost:8080/web03_war_exploded/x/x/z/
- 要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/a/b/c/test.html
- ServletA重定向的路径 : …/…/…/a/b/c/test/html
- 寻找方式就是在当前资源所在路径(http://localhost:8080/web03_war_exploded/x/y/z/)后拼接(…/…/…/a/b/c/test/html),形成(http://localhost:8080/web03_war_exploded/x/y/z/…/…/…/a/b/c/test/html)每个…/抵消一层目录,正好是目标资源正常获取的url(http://localhost:8080/web03_war_exploded/a/b/c/test/html)
@WebServlet("/x/y/z/servletA")
public class ServletA extends HttpServlet {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 相对路径重定向到test.html
resp.sendRedirect("../../../a/b/c/test.html");
}
}
10.2.2.2绝对路径写法
-
访问ServletA的url为 : http://localhost:8080/web03_war_exploded/x/y/z/servletA
-
绝对路径的基准路径为 : http://localhost:8080
-
要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/a/b/c/test.html
-
ServletA重定向的路径 : /web03_war_exploded/a/b/c/test.html
-
寻找方式就是在基准路径(http://localhost:8080)后面拼接(/web03_war_exploded/a/b/c/test.html),得到( http://localhost:8080/web03_war_exploded/a/b/c/test.html)正是目标资源访问的正确路径
-
绝对路径中需要填写项目上下文路径,但是上下文路径是变换的
- 可以通过 ServletContext的getContextPath()获取上下文路径
- 可以将项目上下文路径定义为 / 缺省路径,那么路径中直接以/开头即可
//绝对路径中,要写项目上下文路径 //resp.sendRedirect("/web03_war_exploded/a/b/c/test.html"); // 通过ServletContext对象动态获取项目上下文路径 //resp.sendRedirect(getServletContext().getContextPath()+"/a/b/c/test.html"); // 缺省项目上下文路径时,直接以/开头即可 resp.sendRedirect("/a/b/c/test.html");
10.2.3 请求转发中的路径问题
目标 :由x/y/servletB请求转发到a/b/c/test.html
@WebServlet("/x/y/servletB")
public class ServletB extends HttpServlet {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
}
10.2.3.1 相对路径写法
-
访问ServletB的url为 : http://localhost:8080/web03_war_exploded/x/y/servletB
-
当前资源为 : servletB
-
当前资源的所在路径为 : http://localhost:8080/web03_war_exploded/x/x/
-
要获取的目标资源url为 : http://localhost:8080/web03_war_exploded/a/b/c/test.html
-
ServletA请求转发路径 : …/…/a/b/c/test/html
-
寻找方式就是在当前资源所在路径(http://localhost:8080/web03_war_exploded/x/y/)后拼接(…/…/a/b/c/test/html),形成(http://localhost:8080/web03_war_exploded/x/y/…/…/a/b/c/test/html)每个…/抵消一层目录,正好是目标资源正常获取的url(http://localhost:8080/web03_war_exploded/a/b/c/test/html)
@WebServlet("/x/y/servletB") public class ServletB extends HttpServlet { @Override protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { RequestDispatcher requestDispatcher = req.getRequestDispatcher("../../a/b/c/test.html"); requestDispatcher.forward(req,resp); } }
10.2.3.2绝对路径写法
-
请求转发只能转发到项目内部的资源,其绝对路径无需添加项目上下文路径
-
请求转发绝对路径的基准路径相当于http://localhost:8080/web03_war_exploded
-
在项目上下文路径为缺省值时,也无需改变,直接以/开头即可
@WebServlet("/x/y/servletB") public class ServletB extends HttpServlet { @Override protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { RequestDispatcher requestDispatcher = req.getRequestDispatcher("/a/b/c/test.html"); requestDispatcher.forward(req,resp); } }
10.2.3.3目标资源内相对路径处理
-
此时需要注意,请求转发是服务器行为,浏览器不知道,地址栏不变化,相当于我们访问test.html的路径为http://localhost:8080/web03_war_exploded/x/y/servletB
-
那么此时 test.html资源的所在路径就是http://localhost:8080/web03_war_exploded/x/y/所以test.html中相对路径要基于该路径编写,如果使用绝对路径则不用考虑
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <!-- 当前资源路径是 http://localhost:8080/web03_war_exploded/x/y/servletB 当前资源所在路径是 http://localhost:8080/web03_war_exploded/x/y/ 目标资源路径=所在资源路径+src属性值 http://localhost:8080/web03_war_exploded/x/y/../../static/img/logo.png http://localhost:8080/web03_war_exploded/static/img/logo.png 得到目标路径正是目标资源的访问路径 --> <img src="../../static/img/logo.png"> </body> </html>
三 MVC架构模式
MVC(Model View Controller)是软件工程中的一种
软件架构模式,它把软件系统分为模型、视图和控制器三个基本部分。用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。
-
M:Model 模型层,具体功能如下
- 存放和数据库对象的实体类以及一些用于存储非数据库表完整相关的VO对象
- 存放一些对数据进行逻辑运算操作的的一些业务处理代码
-
V:View 视图层,具体功能如下
- 存放一些视图文件相关的代码 html css js等
- 在前后端分离的项目中,后端已经没有视图文件,该层次已经衍化成独立的前端项目
-
C:Controller 控制层,具体功能如下
- 接收客户端请求,获得请求数据
- 将准备好的数据响应给客户端
MVC模式下,项目中的常见包
-
M:
- 实体类包(pojo /entity /bean) 专门存放和数据库对应的实体类和一些VO对象
- 数据库访问包(dao/mapper) 专门存放对数据库不同表格CURD方法封装的一些类
- 服务包(service) 专门存放对数据进行业务逻辑运算的一些类
-
C:
- 控制层包(controller)
-
V:
- web目录下的视图资源 html css js img 等
- 前端工程化后,在后端项目中已经不存在了
非前后端分离的MVC

前后端分离的MVC

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第一章:初始DDD
- 亚马逊店铺遇到账号申诉模版分享
- vue3dLoader Cannot read properties of null (reading ‘setCrossOrigin‘)“这个报错怎么解决?
- leetcode热题100.两数之和
- c语言扫雷
- beebox靶场A3 low级别 xss通关教程(三)
- 金蝶EAS pdfviewlocal.jsp接口存在任意文件读取漏洞 附POC软件
- 【深度学习每日小知识】Overfitting 过拟合
- 浏览器如何渲染页面
- 踩坑记录:errno: 600009, errMsg: “request:fail invalid url http://xxxxxxxxxx“