python统计分析——多变量描述统计
发布时间:2023年12月28日
资料来源:用Python动手学统计学
多变量的描述统计,通常利用pandas的groupby函数将数据进行分组处理,然后再计算各统计量。
0、导入库和原始数据
import numpy as np
import pandas as pd
import scipy as sp
data_set=pd.DataFrame(
{"type":['A','A','A','B','B','B'],
"data":[2,3,4,6,8,10]}
)1、利用groupby函数对数据进行分组
group=data_set.groupby('type')
type(group)现在group变量已经按照type对数据进行分组,后面对group进行统计处理,即可获得不同type的统计量。
2、平均数
group.mean()

3、标准差
group.std(ddof=1),ddof的用法参照:python统计分析——单变量描述统计-CSDN博客

4、最大值和最小值
最大值:group.max()
最小值:group.min()


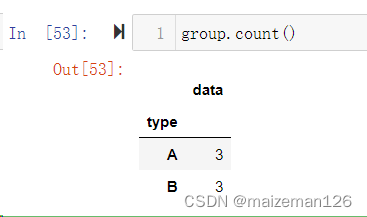
5、计数
group.count()
6、求和
group.sum()

7、中位数
group.median()

8、四分位数
下四分位数:group.quantile(q=0.25)
上四分位数:group.quantile(q=0.75)

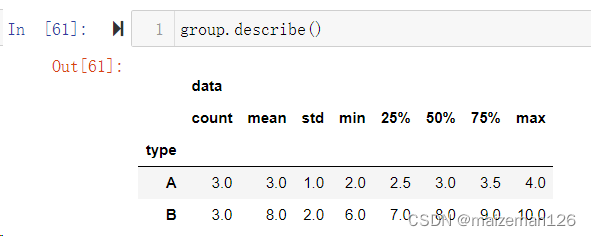
9、一次性获取计数、均值、标准差、极值、四分位数、中位数
group.describe()
文章来源:https://blog.csdn.net/maizeman126/article/details/135274344
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【开源】基于JAVA语言的食品生产管理系统
- 服务拆分及远程调用
- JAVA电商平台 免 费 搭 建 B2B2C商城系统 多用户商城系统 直播带货 新零售商城 o2o商城 电子商务 拼团商城 分销商城
- 关于接口接收一个集合作为参数后,测试时的异常
- 谷歌Linux内核自动测试平台架构介绍-用自动测试测试难以测试的问题
- Zynq UltraScale+ MPSoC-AMP(linux+裸机)
- MT1138-MT1150总结
- 学会这个测试员必懂 Lambda 小知识!
- HTML学习笔记——06:多媒体与嵌入
- idea中设置控制台显示service窗口项