Java JVM内存结构 虚拟机栈 本地方法栈 方法区 直接内存
Java Virtual Machine ,Java 程序的运行环境(Java 二进制字节码的运行环境)。

常见的 JVM:
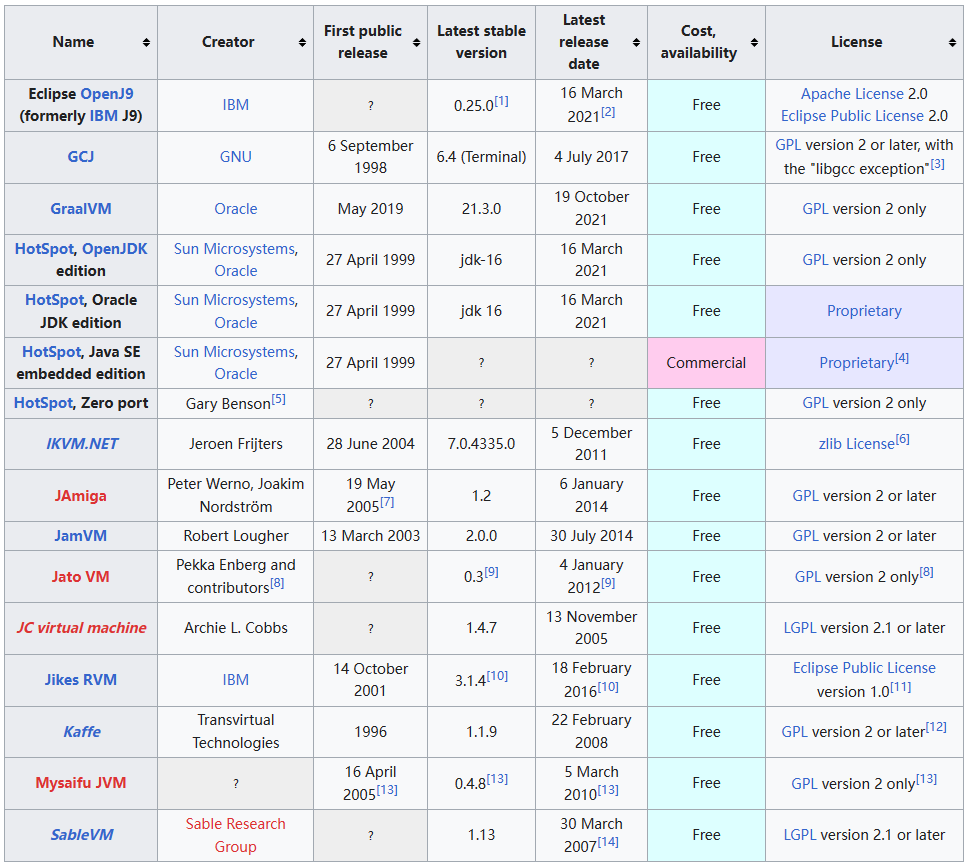
来源维基百科:https://en.wikipedia.org/wiki/Comparison_of_Java_virtual_machines
学习路线:
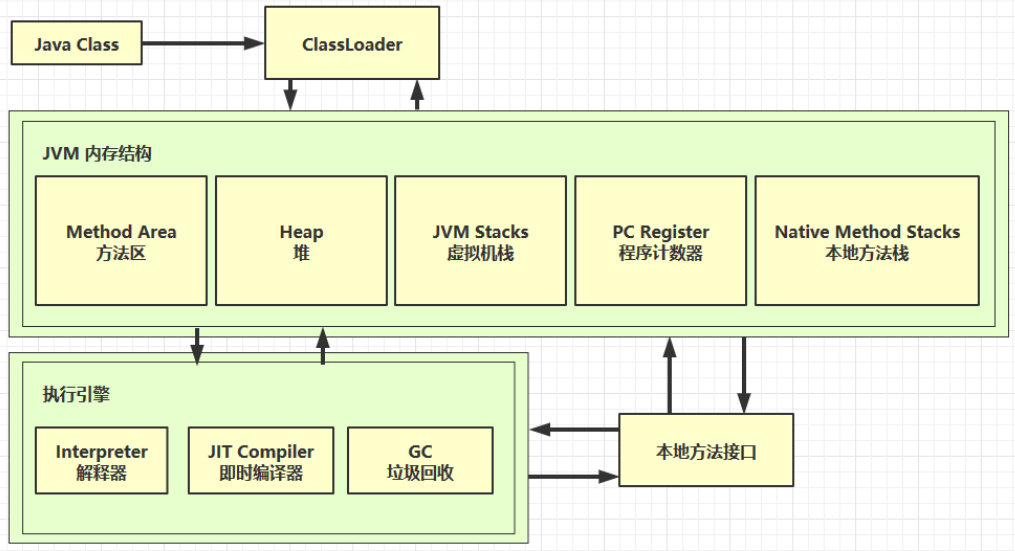
参考资料:https://www.javainterviewpoint.com/java-virtual-machine-architecture-in-java/
程序计数器
Program Counter Register 程序计数器(是通过寄存器实现的),用于保存JVM中下一条所要执行的指令的地址。
PC 寄存器用来存储指向下一条指令的地址,即将要执行的指令代码。由执行引擎读取下一条指令。

左边是二进制字节码,右边是Java编译后的代码,程序计数器就是用于记住下一条jvm指令的执行地址,比如现在是“0”,那他就会记住“3”,因为“3”在“0”的下面,而JVM会将指令 交给 解释器,解释器再将转为 机器码,交于CPU执行。
特点:
- 是线程私有的:
- CPU会为每个线程分配时间片,当当前线程的时间片使用完以后,CPU就会去执行另一个线程中的代码
- 程序计数器是每个线程所私有的,当另一个线程的时间片用完,又返回来执行当前线程的代码时,通过程序计数器可以知道应该执行哪一句指令
- 不会存在内存溢出
虚拟机栈
Java Virtual Machine Stacks (Java 虚拟机栈),栈:先入后出
- 每个线程运行需要的内存空间,称为虚拟机栈
- 每个栈由多个栈帧组成,对应着每次方法调用时所占用的内存空间(参数、局部变量、返回地址)
- 每个线程只能有一个活动栈帧,对应当前正在执行的那个方法
IDEA中的虚拟机栈:
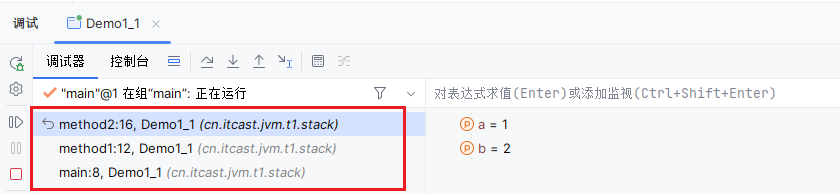
常见问题
- 垃圾回收是否涉及栈内存?
不需要。因为虚拟机栈中是由一个个栈帧组成的,在方法执行完毕后,对应的栈帧就会被弹出栈。所以无需通过垃圾回收机制去回收内存。
- 栈内存分配越大越好吗?
不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
使用
-Xss可以设置栈内存大小,比如物理内存是100Mb,当栈内存为1Mb时,可以同时有100个线程,而当栈内存为2Mb时,最多同时只有50个线程了。
- 方法内的局部变量是否线程安全?
如果方法内部局部变量没有逃离方法的作用访问,它是线程安全的
如果是局部变量引用了对象,并逃离方法的范围,需要考虑线程安全问题
public class main1 {
public static void main(String[] args) {
}
//下面各个方法会不会造成线程安全问题?
//不会
public static void m1() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
//会,可能会有其他线程使用这个对象
public static void m2(StringBuilder sb) {
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
//会,其他线程可能会拿到这个线程的引用
public static StringBuilder m3() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
return sb;
}
}
栈内存溢出
Java.lang.stackOverflowError:栈内存溢出
导致栈内存溢出的情况:
- 栈帧过多导致栈内存溢出
- 栈帧过大导致栈内存溢出

线程运行诊断
Linux环境下运行某些程序的时候,可能导致CPU的占用过高,使用 top 命令可以查看CPU的使用情况:
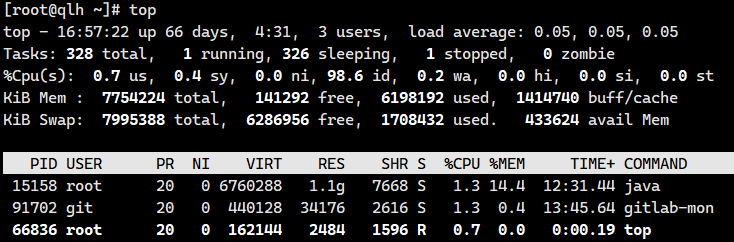
ps H -eo pid,tid,%cpu | grep 进程id ,刚才通过top查到的进程号,用ps命令进一步定位是哪个线程引起的cpu占用过高:

jstack 进程id ,通过ps命令看到的tid来对比定位,注意jstack查找出的线程id是16进制的,需要转换
这样就知道那个线程占用过多的CPU了,进一步定位到问题代码的源码行数
还可以展示出死锁的信息

本地方法栈
Native Method Stacks
一些带有native关键字的方法就是需要JAVA去调用本地的C或者C++方法,因为JAVA有时候没法直接和操作系统底层交互,所以需要用到本地方法。
堆
Heap (堆),通过new关键字创建的对象都会使用堆内存
- 它是线程共享的,堆中对象都需要考虑线程安全的问题
- 有垃圾回收机制
堆内存溢出
java.lang.OutofMemoryError :java heap space :堆内存溢出
设置堆空间大小: -Xmx2m
/**
* 演示堆内存溢出 java.lang.OutOfMemoryError: Java heap space
* -Xmx8m ,最大堆空间的jvm虚拟机参数,默认是4g
*/
public class main1 {
public static void main(String[] args) {
int i = 0;
try {
ArrayList<String> list = new ArrayList<>();// new 一个list 存入堆中
String a = "hello";
while (true) {
list.add(a);// 不断地向list 中添加 a
a = a + a;
i++;
}
} catch (Throwable e) {// list 使用结束,被jc 垃圾回收
e.printStackTrace();
System.out.println(i);
}
}
}
堆内存诊断
jps 工具
查看当前系统中有哪些 java 进程

jmap 工具
查看堆内存占用情况 jmap - heap 进程id

jconsole 工具
图形界面的,多功能的监测工具,可以连续监测
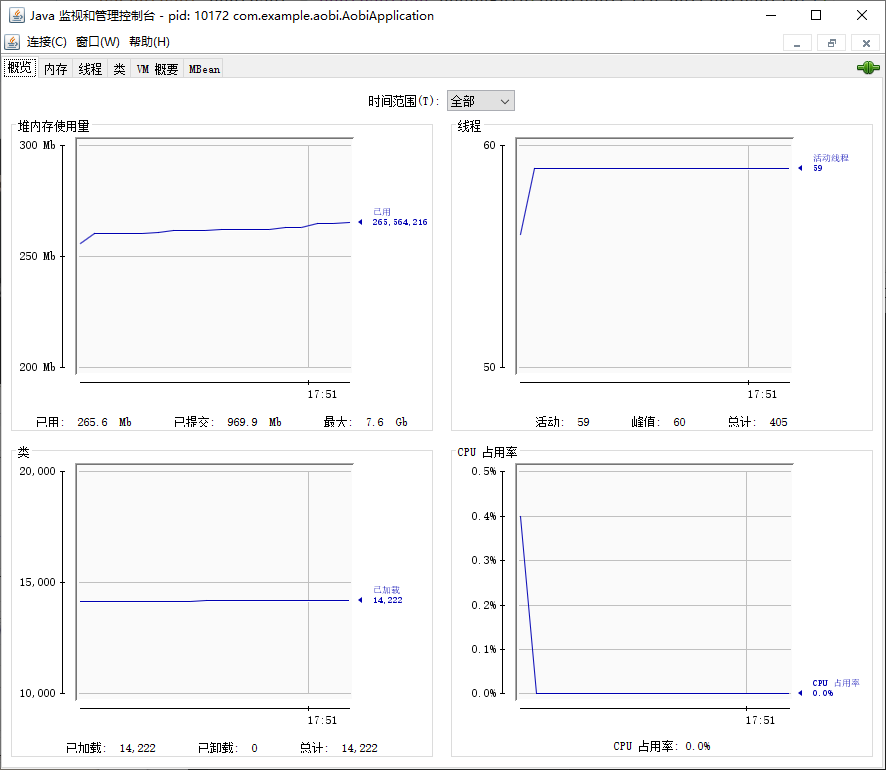
jvisualvm 工具
可视化的展示虚拟机的内容

方法区
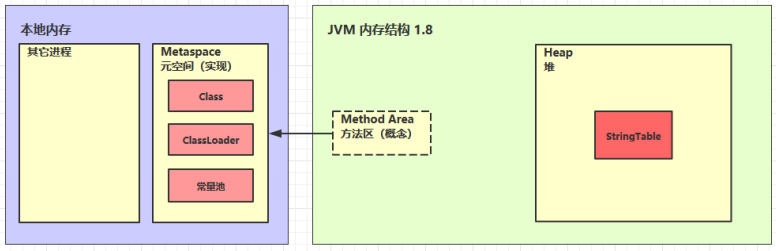
方法区(Method Area) 是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息(比如class文件)、常量、静态变量、即时编译器编译后的代码等数据。(什么是类信息:类版本号、方法、接口。)
官方对于方法区的定义:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html
- 1.6是永久代实现,使用的堆内存
- 1.8是元空间实现,使用的本地内存

方法区内存溢出
- 1.8以前会导致永久代内存溢出
java.lang.OutOfMemoryError: PermGen space- -XX:MaxPermSize=8m
- 1.8以后会导致元空间内存溢出
java.lang.OutOfMemoryError: Metaspace- -XX:MaxMetaspaceSize=8m
/**
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* -XX:MaxMetaspaceSize=8m
*/
public class Demo1_8 extends ClassLoader { // 可以用来加载类的二进制字节码
public static void main(String[] args) {
int j = 0;
try {
Demo1_8 test = new Demo1_8();
for (int i = 0; i < 10000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号, public, 类名, 包名, 父类, 接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回 byte[]
byte[] code = cw.toByteArray();
// 执行了类的加载
test.defineClass("Class" + i, code, 0, code.length); // Class 对象
}
} finally {
System.out.println(j);
}
}
}
运行时常量池
常量池:就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
运行时常量池:常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
通过使用 javap 命令反编译 class 文件后,可以得到类的一些信息:
常量池:

HelloWorld 方法:
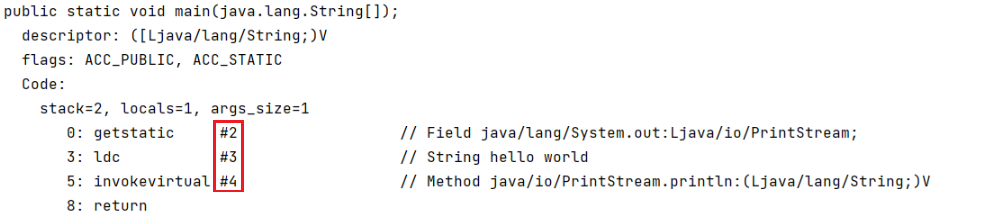
系统会在HelloWorld方法反编译后得到的指令,去常量池中查找,比如第0条指令,后面是
#2,则会在常量池中寻找,而常量池中的#2后面还有#6.#20也会依次寻找#6和#20。
StringTable
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是 StringBuilder(1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
- 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
- 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回
常量池与串池的关系
常量池中的信息,都会被加载到运行时常量池中,这时的 a b ab 都还是常量池中的符号(没有成为java对象),只有在被用到的时候(类似懒加载机制),并且**串池(hashtable结构 不可扩容)**中不存在,才会被存入串池中。
String s1 = "a";
String s2 = "b";
String s3 = "ab";

所以当这三行代码都执行了之后,**串池(StringTable)**中的数据应该为:["a", "b", "ab"]
字符串变量拼接(1.8)
字符串变量之间的拼接,底层使用的StringBuilder类
String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab")
System.out.println(s3 == s4); // false

StringBuilder类的toString方法底层使用的是 new String(xxx) ,所以产生的对象是在堆中,而s3对象在串池中,所以 s3 和 s4 不相等。
编译期优化
String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为ab
System.out.println(s3 == s5); // ture
这里也能看到 s3 和 s5 指向的都是 #4,因为 "a" + "b" 是确定的,编译的时候会直接变成 "ab" 。
字符串加载延迟
System.out.println(); // 字符串个数 2256
System.out.print("1"); // 字符串个数 2257
System.out.print("2"); // 字符串个数 2258
System.out.print("3"); // 字符串个数 2259
System.out.print("4"); // 字符串个数 2260
System.out.print("1"); // 字符串个数 2260
System.out.print("2"); // 字符串个数 2260
System.out.print("3"); // 字符串个数 2260
System.out.print("4"); // 字符串个数 2260
字符串只有在被执行的时候,才会进入串池,如果串池中已经有了,就不会新添加。
intern方法(1.8)
将字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回。
- 如果串池中没有这个字符串,将字符串对象放入串池,也就是说,放入的和返回的是同一个对象
- 如果串池中有这个字符串,就直接返回串池中的对象,准备放入串池的对象和返回的不是同一个对象
String x = "ab";
String s = new String("a") + new String("b");
// 串池:ab, a, b
// 堆:new String("a"), new String("b"), new String("ab")
String s2 = s.intern(); // 因为ab已经在串池了,s对象放入串池失败,返回的s2是串池中的对象
System.out.println(s2 == x); // true
System.out.println(s == x); // false
// 如果没有x变量,则 "ab" = s = s2
intern方法(1.6)
将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回。
复制的对象和原对象不是同一个对象
- 如果串池中没有这个字符串,将字符串对象复制一份,复制的对象和原来的对象内存地址值是不一样的,放入的和返回的不是同一个对象
- 如果串池中有这个字符串,就直接返回串池中的对象,准备放入串池的对象和返回的不是同一个对象
String s = new String("a") + new String("b");
// 串池:a, b
// 堆:new String("a"), new String("b"), new String("ab")
String s2 = s.intern(); // s 拷贝一份,放入串池
String x = "ab"; // x 拿到的是串池中的对象
System.out.println(s2 == x); // false
System.out.println(s == x); // false
// 如果是jdk1.8,则不会拷贝, s = s2 = x
StringTable位置
- JDK1.6,StringTable是属于常量池的一部分。
- JDK1.8,StringTable是放在堆中的。
StringTable垃圾回收
StringTable在内存紧张时,会触发垃圾回收,回收那些没有被引用的字符串。
StringTable性能调优
串池的底层用的是HashTable,数组+链表的数据结构
使用 -XX:+PrintStringTableStatistics 参数可以打印串池的信息:
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 481491 = 11555784 bytes, avg 24.000
Number of literals : 481491 = 29750584 bytes, avg 61.788
Total footprint : = 41786472 bytes
Average bucket size : 8.023
Variance of bucket size : 8.084
Std. dev. of bucket size: 2.843
Maximum bucket size : 23
可以看到,默认的数组大小为 60013 个,串池中的字符串的数量为 481491 个。
如果系统中字符串用到的比较多的话,可以适当的将串池的数组长度调大:
-XX:StringTableSize=桶个数
桶个数应在1009以上。
当桶的个数变多时,Hash碰撞的几率就变小,链表的长度会变短,因为HashTable中的值是不重复的,链表变短后,校验字符串是否重复的时间会变短,从而提升效率。
可以通过intern方法减少重复入池,保证相同的字符串在StringTable中只存储一份:
List<String> address = new ArrayList<>();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(/* 此处读取文件... */)) {
String line;
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
address.add(line/*.intern()*/);
}
}
}
在这种情况下使用intern方法,占用内存的大小会比不使用intern方法占用内存的大小 小得多。
追溯到readLine底层,使用的是new String来构建字符串的,所以直接是存放在堆内存中,如果不使用intern方法,则所有的字符串对象都在堆内存中,而使用后剩余9次循环添加到集合的对象则是串池中的对象,理论上节约了十分之九的内存。
直接内存
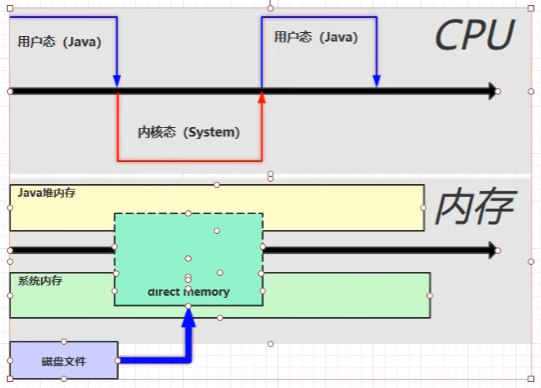
Direct Memory
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
普通的IO:
读入文件会先将文件放入系统的内存,再将文件放入Java的堆内存,Java才能读取,比较浪费时间、浪费性能。

NIO:
开辟一块系统和Java都能访问到的内存区域,无需将文件再次缓冲到Java的堆内存当中,提高效率。
直接内存也会导致内存溢出,比如运行下面的代码:
static int _100Mb = 1024 * 1024 * 100;
public static void main(String[] args) {
List<ByteBuffer> list = new ArrayList<>();
int i = 0;
try {
while (true) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);
list.add(byteBuffer);
i++;
}
} finally {
System.out.println(i);
}
}
可以看到下面的结果:

分配和回收原理
直接内存的回收不是通过JVM的垃圾回收来释放的,而是通过 unsafe.freeMemory() 方法来手动释放
import sun.misc.Unsafe;
Unsafe unsafe = getUnsafe(); // Java内部使用的对象,可以通过反射获取对象
// 分配内存 1Gb = 1024 * 1024 * 1024
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, 1024 * 1024 * 1024, (byte) 0);
// 释放内存
unsafe.freeMemory(base);
而NIO中的ByteBuffer类就是用到了该原理:
- 在DirectByteBuffer类(ByteBuffer的子类)的构造器中,使用了
unsafe.allocateMemory(size)来获取内存空间 - ByteBuffer的实现类内部,使用了Cleaner(虚引用类型)对象来监测ByteBuffer对象是否被回收
- 如果被回收,则会触发Cleaner对象的
clean()方法 clean()方法又会调用创建Cleaner时传入的Deallocator对象(该对象实现了Runnable接口,是一个单独的线程,用来调用unsafe.freeMemory(address)方法)
Demo:
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024 * 1024 * 1024);
System.out.println("分配完毕...");
System.out.println("开始释放...");
byteBuffer = null;
System.gc(); // 显式的垃圾回收,把byteBuffer对象回收掉,然后会自动触发Cleaner的clean()方法
System.in.read();
禁用显式回收对直接内存的影响
可以使用 -XX:+DisableExplicitGC 命令来显式的禁用代码中的 System.gc() 作用(使用该方法影响性能,不光要回收新生代,还有老年代)。
但是如果禁用掉,上面的Demo中的ByteBuffer对象则会长时间存在,程序占用的1Gb的直接内存也不会释放。
此时,建议使用Unsafe类的 freeMemory() 方法手动释放直接内存。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 企业招商与迅腾文化的“轻”理念:重塑品牌与消费者的沟通桥梁
- 从编程中思考:人的经历重叠带给我们的影响
- vue3中el-table实现表格合计行
- 【附完整项目代码】从一个社交分享平台入门MERN全栈开发
- 安泰ATA-2082高压放大器如何驱动超声探头进行无损检测
- 微信小程序如何自定义导航栏,怎么确定导航栏及状态栏的高度?导航栏被刘海、信号图标给覆盖了怎么办?
- 系统安装-VirtualBox-Ubuntu
- 基于SSM+Vue的随心淘网管理系统论文
- 将yolov8的检测框从正框修改为旋转框需要做那些修改?
- 【目标检测】YOLOv5算法实现(二):模型搭建