人话说LightGBM
概述
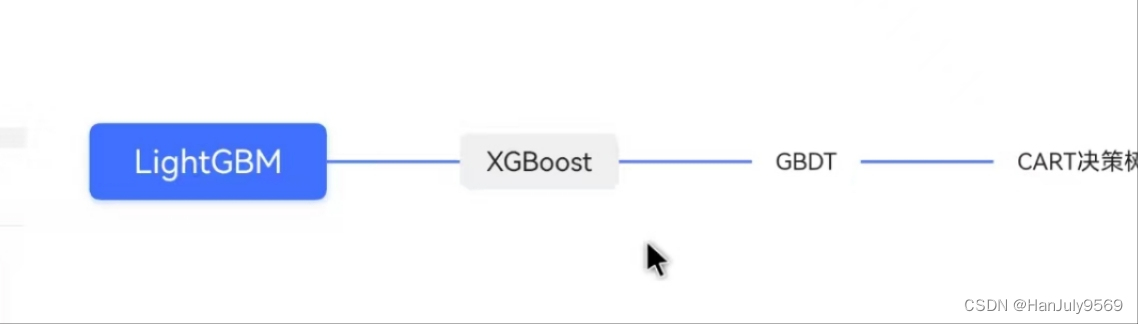
LightGBM 和 XGBoost 两种模型都是GBDT 这种概念的工程化的实现,
说人话就是你和你的兄弟姐妹有一些不同,但是都是你爸和你妈那套操作出来的。
GBDT 这种概念又是建立在cart 决策树上
Cart决策树
决策树
决策树是啥,你就简单的理解为:
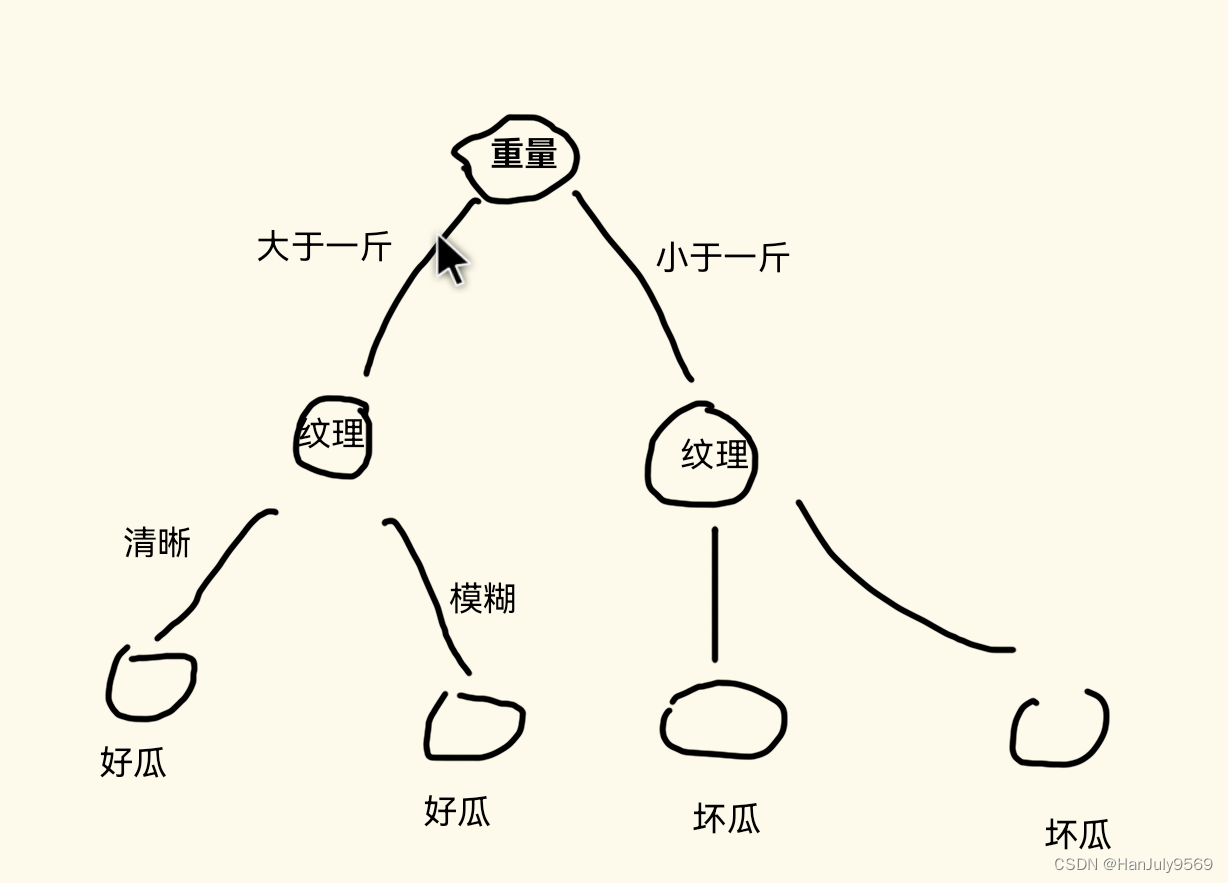
比如用一个决策树判断西瓜是否是好瓜
**
树的非叶子节点:西瓜的特点(特征),比如:纹理,重量
树的树干:西瓜特点的值,比如:纹理清晰,重量大于1斤
树的叶子节点:西瓜的判断结果,比如:好瓜,坏瓜
**
Cart决策树
假如让你用一堆西瓜,这堆西瓜有以下特征
1.重量
2.纹理
3.周长
4.瓜尾巴
让你来做一个树,用这些已有的西瓜来生成一颗树去预测新的瓜。
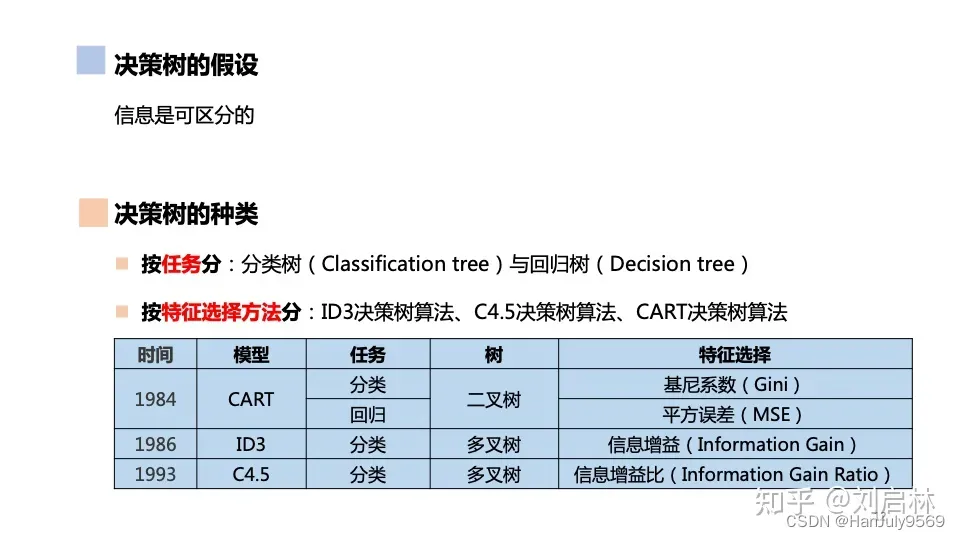
首先肯定要考虑这颗树怎么拆(特征选择),所以根据特征的选择方法就有以下的分类
cart决策树就是使用了基尼系数和平方误差定义为cart分类树和cart回归树
GBDT(梯度提升决策树)
GBDT 简单理解:梯度下降的方式去找提升决策树的最小值,这个树可以表达为一个函数,这个函数的最低点就是我们俗称的模型训练要达到的目的,即损失最小
梯度
简单的理解为,一个函数下降最快的那个方向的矢量
你可能会说,这个方向不就只有一个吗?No,机器学习中很多的函数都不是简单平面函数,所以在三维立体的函数里,你是需要去寻找这个梯度的
梯度下降
简单理解为,每一种机器学习模型都会搞出一个损失函数,这个函数的损失越小了,那模型就越好。那这个函数值的最小点就是我们要找的地方,而如果这个函数是个三维立体的函数,我就希望找它的梯度(下降最快),一步步的找到我们所认为的最小值,
因为在求解过中,我们是看不到函数图的,甚至根本画不出,所以找到这个最小点其实也不是真正的最小点,但已经足够了
提升树
简单理解:
1.你先训练出一颗树A
2.然后你A,然后计算他们与实际值误差
3.然后用训练A的方法,将这些误差视为新的数据再训练一颗树B
4.设最终的提升树为F,那F=A+B,简单理解就用两个树训练
5.重复上的过程后,可能会得到F=A+B+C+D…
6.多少颗树是认为决定的
LightGBM
LightGBM 跟 XGBoost都是将GBDT思想放羊光大,为了不引入过多概念,咱就不说
XGBoost了
LightGBM 也是用上面那种GBDT这种思维去训练树的,从上面GBDT的介绍中,并没有提及这个树怎么建立的问题。所以说他只是一个思想,具体怎么实现还要看具体的模型
LightGBM的实现方式如下:
怎么选取特征分割点
直方图选取分割点
1.将每个特征的所有值,切割为一个个的桶(bin)
比如:重量: b1 [一斤以下] ,b2 [一斤到两斤],b3[ 大于两斤]
纹理: b4[清晰],b5[模糊]
2.每个桶中有个两个值,当前样本梯度和S,样本数N
3.分别以当前bin作为分割点,累加器左边的梯度和样本数,并与父节点的总梯度和总样本数想减,即可得到右边的梯度和样本数,带入公式计算增益,在遍历过程中获取最大的,以此时的特征和bin的特征值作为分裂点
样本梯度和
公式
loss计算的公式入图

样本梯度
简单理解,将样本带入梯度的偏导函数里得到值
直方图怎么做差获得有节点

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- web开发学习笔记(14.mybatis基于xml配置)
- C例题测试1
- 算法练习——盛最多水的容器
- Mac OS 13+,Apple Silicon,删除OBS虚拟摄像头(virtual camera),
- 438. 找到字符串中所有字母异位词(滑动窗口,C解法)
- 存储器管理
- 【性能问题】如何解决MySQL索引失效带来的性能瓶颈这个棘手问题?
- 人工智能未来发展前景怎么样?
- c++输入输出流和文件操作总结
- springboot使用jasypt对配置文件加密,加密数据库连接