[Python] PyTorch之数据集(Dataset)和数据加载器(DataLoader)介绍,使用场景和使用案例
发布时间:2024年01月07日
什么是数据集(Dataset)?
PyTorch的Dataset是一个抽象类,用于表示数据集。它提供了一些通用的方法,如__len__()和__getitem__(),分别用于获取数据集的大小和获取指定索引的数据样本。用户可以通过继承Dataset类并实现这些方法来自定义自己的数据集。
Dataset类:
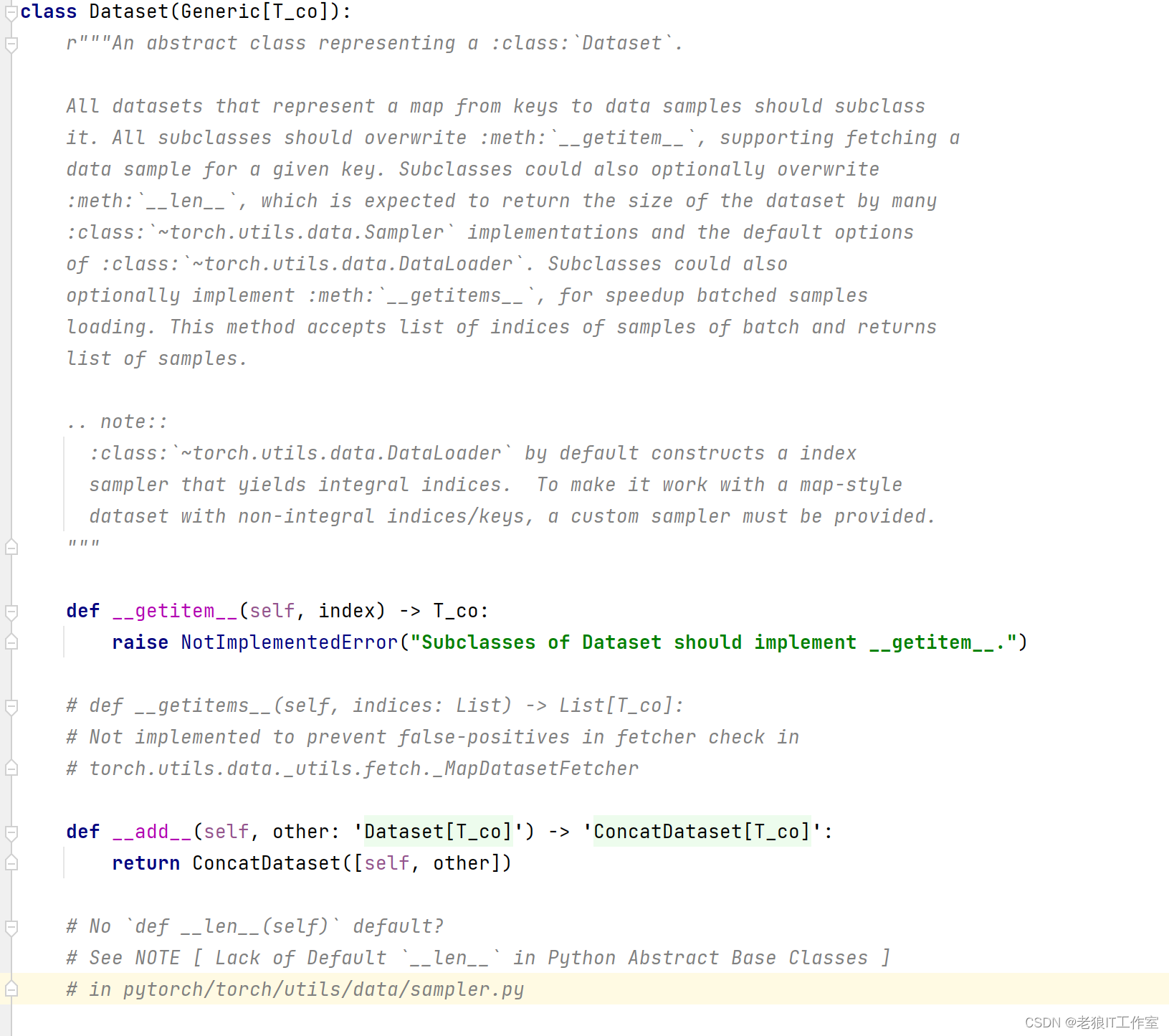
TensorDataset类:
 ?
?
此外,在torchvision库中,针对视觉处理,提供了继承自Dataset的VisionDataset类作为机器视觉数据集的基础类,目前实现了VisionDataset类的子类有74个数据集(比如CIFAR*, MNIST)。
 ?
?
 ?
?
数据集(Dataset)使用场景
数据集(Dataset)使用场景如下:
- 机器学习项目中需要处理大量数据时,可以使用PyTorch的Dataset来组织和管理数据。
- 需要对数据进行预处理、增强或归一化等操作时,可以使用PyTorch的Dataset来方便地实现这些功能。
- 需要将数据集加载到内存中时,可以使用PyTorch的Dataset来实现高效的数据读取和缓存。
什么是数据加载器(DataLoader)?
PyTorch的DataLoader是一个用于加载数据的工具,它可以将数据集分批次地加载到内存中,并支持多线程并行处理。使用DataLoader可以方便地实现小批量训练、分布式训练和数据增强等操作。

参数说明:
dataset:要加载的数据集对象,必须是torch.utils.data.Dataset的子类。batch_size:每个批次的大小,默认为1。shuffle:是否在每个epoch开始时打乱数据顺序,默认为False。sampler:用于指定从数据集中抽取样本的策略,可以是torch.utils.data.Sampler或其子类的对象。batch_sampler:与sampler类似,但是用于指定从数据集中抽取批次的策略,可以是torch.utils.data.BatchSampler或其子类的对象。num_workers:用于数据加载的子进程数,默认为0,表示不使用多进程加载数据。collate_fn:用于将多个样本组合成一个批次的函数,默认为torch.utils.data.dataloader.default_collate。pin_memory:是否将数据存储在固定内存中,默认为False。drop_last:如果为True,则丢弃最后一个不完整的批次,默认为False。timeout:从工作进程中获取数据的超时时间,默认为0,表示无限等待。worker_init_fn:用于初始化工作进程的函数,默认为None。multiprocessing_context:用于指定多进程上下文的类型,默认为None。?
数据加载器(DataLoader)使用场景
DataLoader使用场景:
- 机器学习项目中需要处理大量数据时,可以使用DataLoader来组织和管理数据。
- 需要对数据进行预处理、增强或归一化等操作时,可以使用DataLoader来方便地实现这些功能。
- 需要将数据集加载到内存中时,可以使用DataLoader来实现高效的数据读取和缓存。
- 需要进行小批量训练时,可以使用DataLoader来实现数据的小批量加载。
- 需要进行分布式训练时,可以使用DataLoader来实现数据的分布式加载和处理。
数据集(Dataset)和数据加载器(DataLoader)使用案例
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()
print('model:', model)
# 创建数据集
x = torch.randn(1000, 1) # 生成1000个样本,每个样本有1个特征
print('x.size:', x.size())
noise = torch.from_numpy(np.random.normal(0, 0.1, (1000, 1))).float() # 生成1000 x 1个数值在0~0.1之间噪音
y = 3 * x + 2 + noise # 生成1000个标签 + 其中包含了噪音
print('y.size:', y.size())
dataset = TensorDataset(x, y) # 将数据和标签封装成TensorDataset对象
print('dataset:', dataset)
# 创建数据加载器
batch_size = 100 # 每个批次的大小
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True) # 创建DataLoader对象,用于批量加载数据
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降,学习率为0.01
# 训练模型
num_epochs = 1000
for epoch in range(0,num_epochs):
# 遍历数据集
for i, (inputs, labels) in enumerate(dataloader):
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.6f}'.format(epoch+1, num_epochs, i+1, len(dataloader), loss.item()))
文章来源:https://blog.csdn.net/u011775793/article/details/135423162
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 仓储13代电子标签接口文档-V1.2
- 初阶:第二部分Python语句和语法(程序结构)的知识框架思维导图
- 开启AI创作新纪元:OpenAI GPTs 商店用户必读
- 计算机组成原理-CPU的功能与结构
- 基于Java开发的工作流审批系统,自定义工作流,表单绑定
- 掌握JWT:解密身份验证和授权的关键技术
- 念念不忘智能编程,必有回响CodeArts Snap
- 70、C++ - 仓库目录结构介绍
- Vue和React的运行时,校验引入包的上下文差异
- Paimon教程