学习笔记:R语言基础
文章目录
一、R语言简介
- R语言是一种开源的统计计算和图形制作环境,它不仅提供了全面的数据处理能力,还具备强大的数组运算工具,尤其在向量和矩阵运算上表现出色。此外,R语言内置了丰富的统计分析方法,并拥有卓越的统计图表绘制功能。更关键的是,R语言提供了一种灵活且功能强大的编程语言,使得用户能够自由地进行数据操作、输入输出控制以及自定义函数,以满足各种复杂的数据分析需求。
二、选择R的原因
- 尽管R语言在处理大数据集时性能受限,不适合直接处理大规模数据,但它作为教学与实验工具的价值不容忽视。在教学中,R语言因其清晰易懂的算法模型展示及直观的绘图功能而广受欢迎,便于学生深入理解统计学原理。当面临大数据挑战时,可通过抽样或结合Hadoop、Spark等并行计算框架来解决。此外,通过学习R语言中的数据分析方法和模型原理,用户可以快速迁移到其他大数据处理工具上,实现无缝衔接。
三、R基本数据对象
(一)向量
- R语言中的向量是一种基本且重要的数据结构,它是一维的有序元素序列,可以包含整数、实数、字符、逻辑值或复数等同类型数据。通过
c()函数创建,例如vec <- c(1, 2, 3, "a", TRUE)。向量在R中是处理和分析数据的基础,许多高级数据结构如矩阵、数组和列表都是基于向量构建的。
(二)矩阵
- 在R语言中,矩阵是一个二维数组,用于存储相同类型(如数值、字符)的数据。通过
matrix(data, nrow, ncol, byrow=FALSE, dimnames=NULL)函数创建,其中data是向量数据源,nrow和ncol定义行数和列数,byrow参数决定是否按行填充,若为TRUE则按行填充,FALSE则按列;dimnames可为矩阵添加行名和列名。矩阵支持各种数学运算,可通过索引进行元素访问和修改。
(三)数组
- 在R语言中,数组是一种多维数据结构,用于存储同一类型的数据。通过
array()函数创建,它接受一个向量作为基础数据,并通过dim参数指定各维度大小来形成更高维度的集合。例如,可以创建包含多个矩阵的三维数组,每个元素都具有相同的类型。数组是向量和矩阵的扩展,可用来处理更复杂、多层面的数据组织。
(四)因子
- 在R语言中,因子(factor)是一种特殊的数据类型,用于表示分类或有序类别数据。它将名义变量或有序变量的各个类别值编码为整数,并存储一个映射表,将这些整数对应到原始类别标签。因子是统计分析和可视化时的关键对象,能确保分类变量在模型构建、假设检验(如卡方检验)以及各类回归分析、ANOVA等过程中得到正确处理。创建因子使用
factor()函数,可自定义级别顺序和标签。
(五)列表
- R语言中的列表是一种灵活且强大的数据结构,它是一个有序的、可变长度的集合,能够容纳不同类型(如数值、字符、逻辑甚至其他数据结构如向量、矩阵、数组或数据框等)的对象。通过
list()函数创建,列表允许将多个元素聚合为单个对象,便于管理和操作多组不同性质的数据。例如,可以创建一个包含字符串、数值向量和逻辑矩阵的列表,每个成分都可以独立存取和修改。
(六)数据框
- R语言中的数据框(data frame)是一种特殊的数据结构,它将表格形式的数据组织成列向量的集合。每一列代表一个变量,可以是不同数据类型(如数值、字符或逻辑型),而每行则表示观测样本。数据框可通过
data.frame()函数构建,其各列必须具有相同长度。数据框常用于统计分析和数据可视化,类似于电子表格,且能灵活处理多元统计中异质类型的数据集。
(七)函数
- 在R语言中,函数是执行特定任务的可重复使用的代码块。用户通过定义函数名、参数列表和函数体来创建函数,函数能接收输入(参数),经过一系列计算或逻辑处理后,返回一个结果。例如,
mean()是一个内置函数,用于计算向量或数组的平均值;用户也可自定义函数,如myFunction(x, y) <- {x + y}实现两数相加的功能。函数有助于模块化编程,提高代码复用性和组织性。
四、基本函数应用示例
-
创建向量:在R中,通过
c()函数可以创建一维向量。例如,x <- c(10.4, 5.6, 3.1, 6.4, 21.7)将一系列数值组合成名为x的浮点数向量。赋值符号可以用<-或=, 这里所有元素自动转换为一致的数据类型(在这个例子中是数值型)。 -
生成序列:使用
seq()函数可以生成一系列连续数值。如seq(2, 10)默认步长为1生成2到10的整数序列;指定步长为2用seq(1, 10, by = 2);步长为0.2则为seq(1, 5, by = 0.2);从2开始,步长为3产生4个数:seq(2, 8, by = 3);在区间[-5,5]生成100个数:seq(-5, 5, length.out = 100)。 -
重复序列:
rep()用于复制向量或生成重复序列。比如rep(c(1, 2, 3), times = 3)会将整个向量重复3次;而rep(x, each = 2)会将向量x中的每个元素分别复制2次形成新序列并赋值给data。 -
拼接函数:
paste()结合多个数据项为一个字符串。如paste("Hello", "World")得到"Hello World";添加分隔符:paste(c("A", "B", "C"), collapse = ", ")结果为"A, B, C";拼接与序列结合实例:paste(seq(1, 3), "apple")生成"1 apple", “2 apple”, “3 apple”。 -
数据子集选择与修改:通过索引操作符
[]选取向量元素,如data[3:5]获取向量data第3至第5个元素;条件选择:data[data > 300 & data < 400]选出data中300至400之间的元素,并统计其数量:sum(data > 300 & data < 400)。 -
汇总函数:
summary()提供对象的基本统计信息。对于向量,输出包括最小值、四分位数、中位数、均值和最大值等。例如,summary(data)查看向量data的相关统计指标。 -
因子函数:
factor()将字符向量转化为有序或无序因子,便于分类分析。如data <- factor(c("湖南","四川","四川","湖南","贵州","湖南","贵州")),levels(data)显示因子的类别。 -
矩阵函数:
matrix()创建矩阵,如matrix(c(4,-1,2,1,1,1,0,3,0,3,1,4), nrow = 4, ncol = 3)创建一个4行3列的矩阵。访问矩阵元素如A[2, 3];创建单位矩阵:diag(n);填充特定元素矩阵示例已给出。 -
矩阵转置函数:
t()实现矩阵转置,如t(A)将矩阵A转置。 -
矩阵维数函数:
dim()返回或设置矩阵维数,如dim(A)查询矩阵A的维度,dim(A) <- c(3, 4)更改A的维度为3行4列。 -
数组函数:通过
array()和dim参数定义多维数组,例如创建三维数组需指定每维大小。 -
列合并与行合并:
cbind()按列合并矩阵,如cbind(A, B);rbind()按行合并矩阵,如rbind(A, B)。 -
列表函数:列表是一种可包含不同类型元素的数据结构。要获取列表中属性值,如
list_data$attribute_name。例如,my_list <- list(name = "Mike", age = 25); my_list$name返回"Mike"。 -
数据帧函数:
data.frame()构造数据帧,各列可以是不同模式。如df <- data.frame(name = c("John", "Jane"), age = c(30, 28))创建一个数据帧。引用数据帧元素时通常使用$符号,如df$name。attach()和detach()函数用于简化数据框变量的引用,但不推荐频繁使用以避免命名冲突等问题。例如,attach(df)后可以直接用name引用列名,结束后用detach(df)解除关联。 -
read.table()函数:
read.table()是R语言中用于读取纯文本文件并将其中数据转换为数据帧的函数。该函数要求输入文件的第一行包含变量名,后续行代表数据记录,每行按列对应各变量值。若无表头,则默认变量名为"v1", "v2"等;若有表头但无行索引,通过设置header=TRUE指明首行为列名。此外,可通过setwd()函数改变当前工作目录以便正确读取目标文件。- 创建文本文件
info.txt
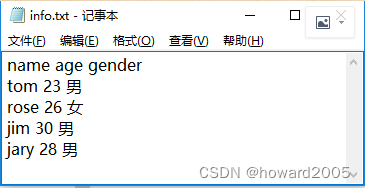
- 读取,表头采用默认变量

- 读取,采用文件首行做表头

- 使用
attach()函数简化对info的数据引用

- 创建文本文件
五、自定义函数
(一)自定义函数定义
- 在R语言中,用户通过
function()关键字定义自定义函数,例如:myFunction <- function(arg1, arg2) {expression},其中arg1和arg2为输入参数,expression是基于这些参数进行计算或处理的代码块。
(二)自定义函数示例
1、求和函数

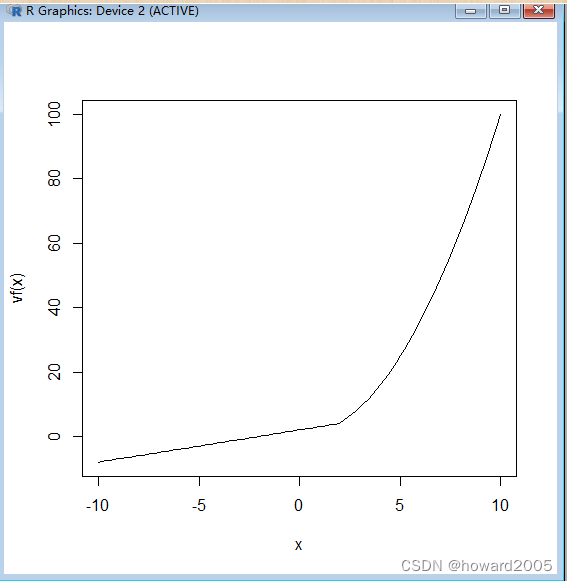
2、分段函数
f ( x ) = { x + 2 ( 1 ) x 2 ( 2 ) f(x)=\begin{cases} x+2 &(1)\\ x^2 &(2)\\ \end{cases} f(x)={x+2x2?(1)(2)?
- 定义函数,并绘制图像

六、结束语
- 总之,R语言作为开源统计计算和图形制作的首选工具,凭借其全面的数据处理能力、强大的数组运算以及丰富的内置统计模型和可视化功能,在全球数据分析领域占据重要地位。尽管在处理超大规模数据时面临性能挑战,但通过合理抽样或结合分布式计算框架,R语言依然能够胜任复杂的数据分析任务。从基础数据对象如向量、矩阵到更高级的数据结构如数组、因子、列表和数据框,R语言提供了一套完整且灵活的数据组织方式,满足各种类型数据的存储与操作需求。而函数的运用则大大提升了代码复用性和程序结构化程度,无论是利用内置函数进行快速统计分析,还是自定义函数解决特定问题,都彰显了R语言在实现高效数据分析流程上的优越性。掌握R语言的基本语法和核心功能,无疑将助力用户深入探索数据背后的规律,提升解决问题的能力,并在实际应用中发挥关键作用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 背单词——冰雹猜想
- uniapp 安装插件 uView (多平台快速开发的UI框架)
- 【设计模式】腾讯面经:原型模式怎么理解?
- 音视频编码基础知识
- 【计网】第一章-计网体系结构
- 编曲小白如何选择DAW?一款免费好用的调音台推荐
- python深入与提高
- [pasecactf_2019]flask_ssti proc ssti config
- 在 Nvidia Docker 容器编译构建显存优化加速组件 xFormers
- 魔法少女优化修改