Kafka-服务端-KafkaController
Broker能够处理来自KafkaController的LeaderAndIsrRequest、StopReplicaRequest、UpdateMetadataRequest等请求。
在Kafka集群的多个Broker中,有一个Broker会被选举为Controller Leader,负责管理整个集群中所有的分区和副本的状态。
例如:当某分区的Leader副本出现故障时,由Controller负责为该分区重新选举新的Leader副本;
当使用kafka-topics脚本增加某Topic的分区数量时,由Controller管理分区的重新分配;
当检测到分区的ISR集合发生变化时,由Controller通知集群中所有的Broker更新其MetadataCache信息。
为了实现Controller的高可用,一个Broker被选为Leader之后,其他的Broker都会成为Follower(不加特殊说明的情况下,本文的“Leader/Follower”指的都是KafkaController的Leader/Follower,请不要与副本机制中的Leader副本和Follower副本混淆),会从剩下的Follower中选出新的Controller Leader来管理集群。
选举Controller Leader依赖于ZooKeeper实现,每个Broker启动时都会创建一个KafkaController对象,但是集群中只能存在一个Controller Leader来对外提供服务。
在集群启动时,多个Broker上的KafkaController会在指定路径下竞争创建节点,只有第一个成功创建节点的KafkaController才能成为Leader,而其余的KafkaController则成为Follower。
当Leader出现故障后,所有的Follower会收到通知,再次竞争在该路径下创建节点从而选出新的Leader。这也是ZooKeeper的一种常见用法。
在Kafka早期版本中并没有采用KafkaController的设计来对分区和副本状态进行管理,而是依赖于ZooKeeper的Watcher和队列。
在早期版本的设计中,每个Broker都会在ZooKeeper上注册Watcher,ZooKeeper上就会出现大量Watcher,当分区或副本状态变化时会唤醒很多不必要的Watcher,这种严重依赖ZooKeeper的设计出现了“脑裂”、“羊群效应”以及ZooKeeper集群过载的情况。
在新版本设计中,只有Controller Leader在ZooKeeper上注册Watcher,其他Broker几乎不用再监听ZooKeeper中的数据变化。
旧版本中Broker之间传递事件依赖于ZooKeeper的设计比较低效,在新版设计中ControllerLeader直接与Broker交互。旧版本的设计毕竟已经废弃,在设计分布式系统时要适度依赖ZooKeeper集群,合理利用ZooKeeperWatcher,否则就会出现上述问题。
我们先通过图了解ZooKeeper中与KafkaController相关的路径以及该路径中记录的内容的含义。
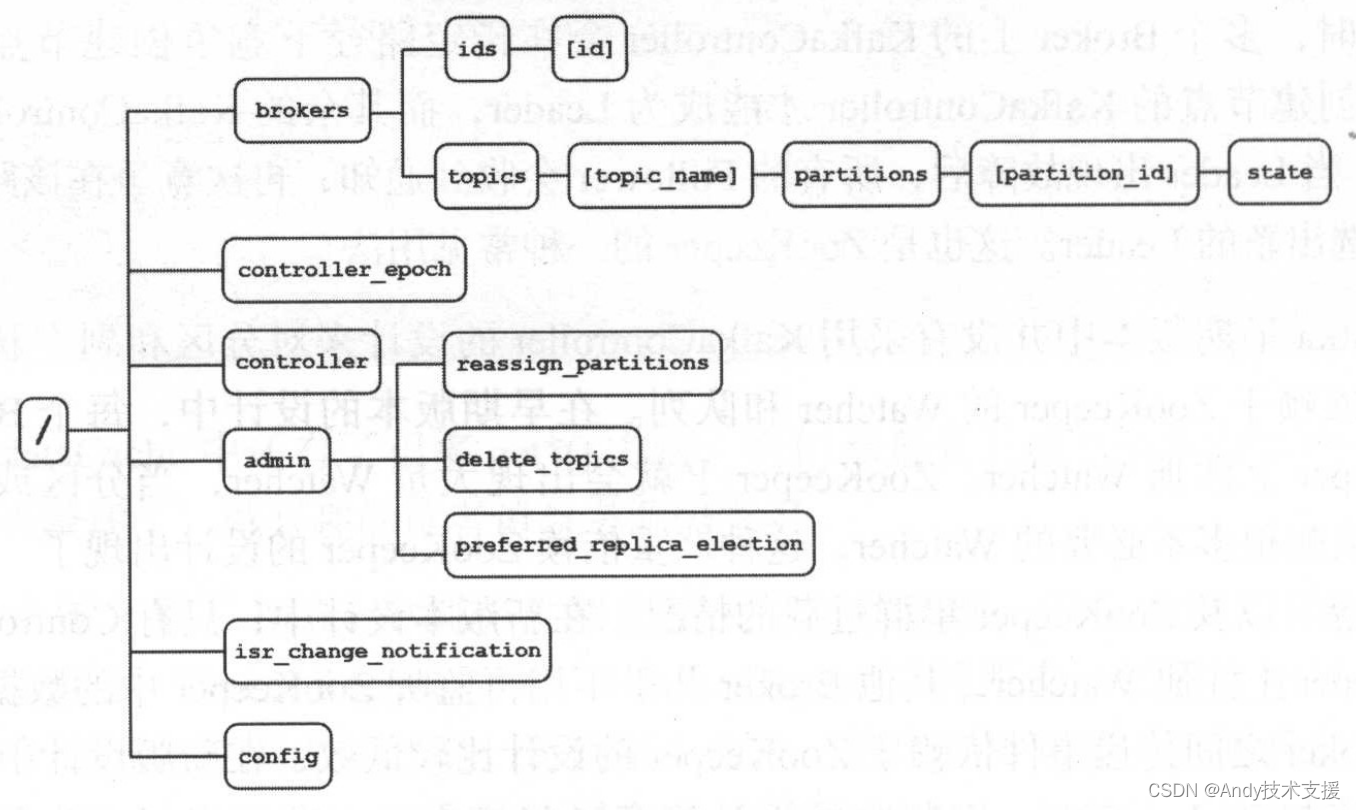
- /brokers/ids/[id]:记录了集群中可用Broker的id。
- /brokers/topics/topic]partitions:记录了一个Topic中所有分区的分配信息以及AR集合信息。
- /brokers/topics/topic/partitions/[partitionid/state:记录了某Partition的Leader副本所在Brokerld、lead_epoch、ISR集合、ZKVersion等信息。
- /controller_epoch:记录了当前Controller Leader的年代信息。
- /controller:记录了当前Controller Leader的Id,也用于Controller Leader的选举。
- /admin/reassign partitions:记录了需要进行副本重新分配的分区。
- /admin/preferred_replica_election:记录了需要进行“优先副本”选举的分区。“优先副本”是在创建分区时为其指定的第一个副本。
- /admin/delete_topics:记录了待删除的Topic。
- /isr_change_notification:记录了一段时间内ISR集合发生变化的分区。
- /config:记录了一些配置信息。
在详细介绍KafkaController的相关组件之前,先从整体上了解KafkaController的设计,以及组件之间的依赖关系如图所示。
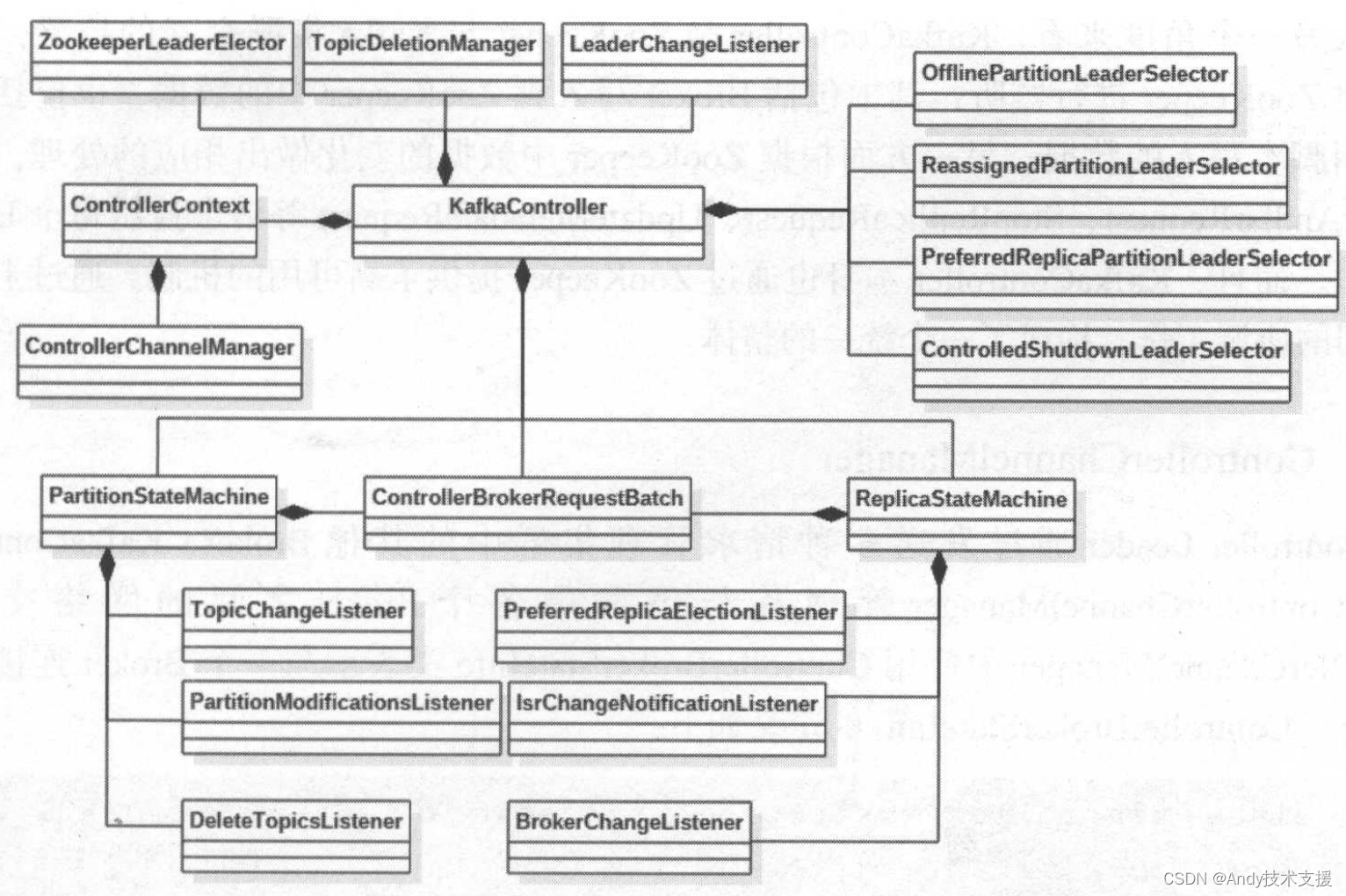
- KafkaController组织并封装了其他组件,对外提供API接口。
- ZookeeperLeaderElector主要用于Controller Leader的选举。
- ControllerContextKafkaController的上下文信息,缓存了ZooKeeper中记录的整个集群的元信息,例如,可用Broker、全部的Topic、分区、副本的信息。
- ControllerChannelManager维护了Controller Leader与集群中其他Broker之间的网络连接,是管理整个集群的基础。
- TopicDeletionManager用于对指定的Topic进行删除。
- PartitionStateMachine用于管理集群中所有Partition状态的状态机。
- ReplicaStateMachine用于管理集群中所有副本状态的状态机。
- ControllerBrokerRequestBatch实现了向Broker批量发送请求的功能。
- *PartitionLeaderSelector实现了多种Leader副本选举策略。
- *Listener是ZooKeeper上的监听器,实现了对ZooKeeper上某些节点中的数据、子节点或ZooKeeper Session状态的监听,被触发后调用相应的业务逻辑。
从另一个角度来看,KafkaController是ZooKeeper与Kafka集群交互的桥梁:
它一方面对ZooKeeper进行监听,其中包括Broker写入到ZooKeeper中的数据,也包括管理员使用脚本写入的数据;
另一方面根据ZooKeeper中数据的变化做出相应的处理,通过LeaderAndlsrRequest、StopReplicaRequest、UpdateMetadataRequest等请求控制每个Broker的工作。
而且,KafkaController本身也通过ZooKeeper提供了高可用的机制。通过上述组件之间的协调工作,构成了一个统一的整体。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【阅读笔记】LoRAHub:Efficient Cross-Task Generalization via Dynamic LoRA Composition
- 设置Linux用户的最大进程数和最大打开文件描述符数
- Oracle扩展ASM存储
- Python Django Suit:构建现代化的Django后台管理
- LC674. 最长连续递增序列
- 全球十大知名黄金外汇交易平台最新排名榜单(综合版)
- [卷积神经网络]FCOS--仅使用卷积的Anchor Free目标检测
- Java实现医院门诊预约挂号系统 JAVA+Vue+SpringBoot+MySQL
- LOCK&&synchronized
- 大数据---35.HBase 常用的api的具体解释