(2024,强化学习,扩散,奖励函数)扩散模型的大规模强化学习
Large-scale Reinforcement Learning for Diffusion Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
文本到图像扩散模型是一类深度生成模型,展示了令人印象深刻的高质量图像生成能力。然而,这些模型容易受到源自网络规模文本-图像训练对的隐含偏见的影响,可能不准确地建模我们关心的图像方面。这可能导致次优的样本、模型偏见以及与人类伦理和偏好不符的图像。在本文中,我们提出了一种有效的可扩展算法,使用强化学习(RL)改进扩散模型,涵盖人类偏好、组成性和公平性等多种奖励函数,涉及数百万张图像。我们说明了我们的方法如何显著优于现有方法,使扩散模型与人类偏好保持一致。我们进一步说明了如何显著改进预训练的稳定扩散(SD)模型,生成被人类喜爱的样本,比基础 SD 模型的样本被人类喜爱的时间多 80.3%,同时提高了生成样本的组成和多样性。
项目网站:https://pinterest.github.io/atg-research/rl-diffusion/
3. 方法
在这一部分,我们描述了我们应用大规模强化学习(RL)训练到扩散模型的方法。我们的目标是微调现有扩散模型的参数 θ,以最大化从采样过程中生成的图像的奖励信号 r:
![]()
其中,p(c) 是上下文分布,pθ(x0|c) 是样本分布,而 r(x0, c) 是应用于最终样本图像的奖励函数。?
3.1. 使用多步骤 MDP 的策略梯度
在遵循 Black 等人的方法 [5] 的基础上,我们重新构思了扩散模型的迭代去噪过程,将其视为多步骤马尔可夫决策过程(Markov decision process,MDP),其中在每个时间步 t,策略、动作、状态和奖励定义如下:

我们将扩散模型的反向采样过程 p_θ(x_(t?1) | x_t, c) 视为策略。从采样的初始状态 x_T 开始,策略在任何时间步t的动作是产生下一个时间步x_(t?1) 的更新。奖励在最终时间步被定义为 r(x0, c),在其他情况下为 0。
策略梯度的估计可以使用似然比方法(也称为 REINFORCE)[33, 48] 进行:

我们还应用重要性采样以便从旧策略收集样本来提高训练效率,并结合剪切的信任区域,以确保新策略不会偏离旧策略太远 [41] 。最终剪切的替代目标函数可以写成:?
![]()
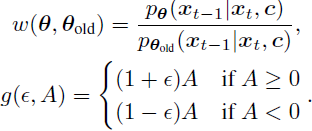
这里 ? 是确定剪切区间的超参数,而 ^A(x0, c) 是样本的估计优势(estimated advantage)。为了进一步防止对奖励函数的过度优化,我们还将原始扩散模型目标作为损失函数的一部分纳入考虑。因此,我们的完整训练目标是:?
![]()
![]()
一个额外的细节是,在梯度更新过程中,通常将奖励值归一化为零均值和单位方差,以提高训练稳定性。在基于策略的强化学习中,一种通用的方法是从奖励中减去基线状态值函数,以得到优势函数 [45]:

在 DDPO 的原始实现中,Black 等人通过独立跟踪每个提示的运行均值和标准差,在每个上下文的基础上对奖励进行归一化 [5]。然而,如果训练集大小是无界的或不固定的,这种方法仍然不切实际。
与他们有限的训练提示大小(最多只有 398 个)形成对比,我们的大规模微调实验涉及数百万个训练提示。我们改为使用每个 batch 的均值和方差,在批次的基础上对奖励进行归一化。
3.2. 基于分布的奖励函数
在先前概述的扩散 MDP 公式中,每一次生成被视为独立的,因此由生成样本产生的奖励彼此独立。这种公式对于只关心单个图像的内容的奖励函数是自然的选择,比如图像质量或文本图像对齐。然而,有时我们关心的不是任何特定图像的内容,而是扩散模型整体的输出分布。例如,如果我们的目标是确保模型生成多样化的输出,仅考虑单个生成是不够的——我们必须考虑所有输出,以了解我们模型的这些分布属性。
为此,我们还研究了在扩散模型强化学习中使用基于分布的奖励函数。然而,构建真实生成分布是不可行的。因此,我们通过在强化学习过程中跨小批次计算的经验样本来近似奖励。在训练期间,获得的奖励在每个小批次上计算,然后小批次奖励通过样本进行反向传播,以执行模型更新。在第4.2 节中,我们通过学习基于分布的奖励函数,优化生成样本中的公平性和多样性,验证了这种方法。
3.3. 多任务联合训练
我们还进行多任务联合训练,同时优化单一模型以实现多样的目标。如下一节详细说明,我们将来自人类偏好、肤色多样性、目标组合的奖励函数全部纳入联合优化。由于每个任务涉及不同分布的训练提示,在每次训练迭代中,我们从所有任务中随机抽取多个提示,并独立运行采样过程。每个奖励模型都应用于相应提示的样本图像。然后,对每个任务依次执行方程 7 中的梯度步骤。我们在附录 A 中提供了可用的超参数,并在算法 1 中概述了训练框架。

4. 奖励函数和实验?
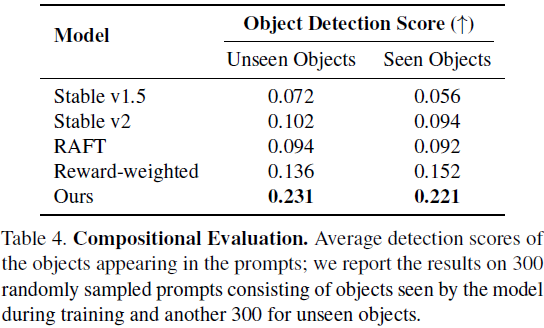
为了在各种设置中验证我们的方法,我们进行了三个独立的奖励函数的实验:人类偏好、图像组合以及多样性和公平性。





本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (Java企业 / 公司项目)配置Gateway + Nacos应用名路由转发?
- 堆排序算法
- 简历时态:简历应该用过去时还是现在时?
- RTX 4090D解禁真香警告?核心阉割性能“只下降”了5%
- 《微信小程序开发从入门到实战》学习五十五
- 如何搭建一个买衣服的微信小程序商城
- python读取excel文件数据并且画折线图
- Axios 中的文件上传 File对象的方法
- RAM读写测试
- 55、Flink之用于外部数据访问的异步 I/O介绍及示例