MapReduce概述
1. 分布式系统的驱动力和挑战
分布式系统的核心是通过网络来协调,共同完成一致任务的一些计算机。
构建分布式系统的目的:
- 高性能
- 容错
- 一些问题天然在空间上是分布的。例如银行转账。
- 构建分布式系统来达成一些安全的目标。
这门课程中,我们主要会讨论前两点:性能和容错。
分布式系统的问题(挑战)在于:
- 系统中存在很多部分,这些部分又在并发执行,你会遇到并发编程和各种复杂交互所带来的问题。
- 分布式系统有多个组成部分,再加上计算机网络,你会会遇到一些意想不到的故障。
- 人们设计分布式系统的根本原因通常是为了获得更高的性能,比如说一千台计算机或者一千个磁盘臂达到的性能。但是实际上一千台机器到底有多少性能是一个棘手的问题,这里有很多难点。
2. 分布式系统的抽象和实现工具
我们课程中主要介绍的一些基础架构。基础架构的类型主要是存储,通信(网络)和计算。我们会讨论包含所有这三个部分的基础设施,但实际上我们最关注的是存储,因为这是一个定义明确且有用的抽象概念,并且通常比较直观。我们希望构建一个接口,它看起来就像一个非分布式存储和计算系统一样,但是实际上又是一个有极高的性能和容错性的分布式系统。
当我们在考虑这些抽象的时候,第一个出现的话题就是实现。人们在构建分布系统时,使用了很多的工具,例如:
- RPC(Remote Procedure Call)。RPC的目标就是掩盖我们正在不可靠网络上通信的事实。
- 另一个我们会经常看到的实现相关的内容就是线程。
- 因为我们会经常用到线程,我们需要在实现的层面上,花费一定的时间来考虑并发控制,比如锁。
3. 可扩展性、可用性、一致性
可扩展性:
我们希望可以通过增加机器的方式来实现扩展,但是现实中这很难实现,需要一些架构设计来将这个可扩展性无限推进下去。
可用性:
大型分布式系统中有一个大问题,那就是一些很罕见的问题会被放大。因为错误总会发生,必须要在设计时就考虑,系统能够屏蔽错误,或者说能够在出错时继续运行。
除了可用性之外,另一种容错特性是自我可恢复性(recoverability)。这里的意思是,如果出现了问题,服务会停止工作,不再响应请求,之后有人来修复,并且在修复之后系统仍然可以正常运行,就像没有出现过问题一样。这是一个比可用性更弱的需求。
为了实现这些特性,有很多工具。其中最重要的有两个:
- 一个是非易失存储(non-volatile storage,类似于硬盘)。这样当出现类似电源故障,甚至整个机房的电源都故障时,我们可以使用非易失存储,比如硬盘,闪存,SSD之类的。
- 对于容错的另一个重要工具是复制(replication),不过,管理复制的多副本系统会有些棘手。现在的关键问题在于,这两个副本总是会意外的偏离同步的状态,而不再互为副本。对于任何一种使用复制实现容错的系统,我们都面临这个问题。
一致性:
从性能和容错的角度来说,我们通常会有多个副本。假设服务器有两个副本,那么他们都有一个key-value表单,两个表单中key 1对应的值都是20。现在某个客户端发送了一个put请求,并希望将key 1改成值21。之后会发送给第二台服务器,因为相同的put请求需要发送给两个副本,这样这两个副本才能保持同步。但是就在客户端准备给第二台服务器发送相同请求时,这个客户端故障了,可能是电源故障或者操作系统的bug之类的。所以,现在我们处于一个不好的状态,我们发送了一个put请求,更新了一个副本的值是21,但是另一个副本的值仍然是20。如果现在某人通过get读取key为1的值,那么他可能获得21,也可能获得20,取决于get请求发送到了哪个服务器。即使规定了总是把请求先发送给第一个服务器,那么我们在构建容错系统时,如果第一台服务器故障了,请求也会发给第二台服务器。
比如说get请求可以得到最近一次完成的put请求写入的值。这种一般也被称为强一致(Strong Consistency)。但是,事实上,构建一个弱一致的系统也是非常有用的。弱一致是指,不保证get请求可以得到最近一次完成的put请求写入的值。
人们对于弱一致感兴趣的原因是,虽然强一致可以确保get获取的是最新的数据,但是实现这一点的代价非常高。人们常常会使用弱一致系统,你只需要更新最近的数据副本,并且只需要从最近的副本获取数据。在学术界和现实世界(工业界),有大量关于构建弱一致性保证的研究。所以,弱一致对于应用程序来说很有用,并且它可以用来获取高的性能。
4. MapReduce基本工作方式
MapReduce是由Google设计,开发和使用的一个系统,相关的论文在2004年发表。Google当时面临的问题是,他们需要在TB级别的数据上进行大量的计算。
背景:当时Google需要一种框架,使得普通工程师也可以很容易的完成并运行大规模的分布式运算。工程师只需要实现应用程序的核心,就能将应用程序运行在数千台计算机上,而不用考虑如何将运算工作分发到数千台计算机,如何组织这些计算机,如何移动数据,如何处理故障等等这些细节。
MapReduce的思想是,应用程序设计人员和分布式运算的使用者,只需要写简单的Map函数和Reduce函数,而不需要知道任何有关分布式的事情,MapReduce框架会处理剩下的事情。
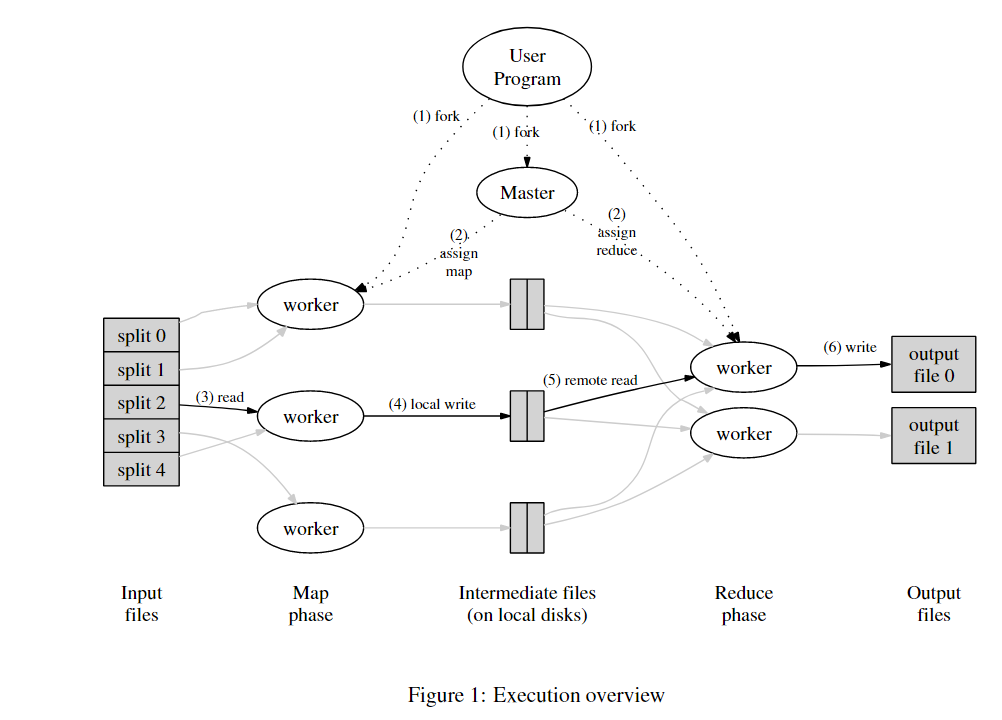
MapReduce假设有一些输入,这些输入被分割成大量的不同的文件或者数据块。MapReduce启动时,会查找Map函数。之后,MapReduce框架会为每个输入文件运行Map函数。
Map函数以文件作为输入,文件又是整个输入数据的一部分。Map函数的输出是一个key-value对的列表。假设我们在实现一个最简单的MapReduce Job:单词计数器。它会统计每个单词出现的次数。在这个例子中,Map函数会输出key-value对,其中key是单词,而value是1。Map函数会将输入中的每个单词拆分,并输出一个key-value对,key是该单词,value是1。最后需要对所有的key-value进行计数,以获得最终的输出。所以,假设输入文件1包含了单词a和单词b,Map函数的输出将会是key=a,value=1和key=b,value=1。第二个Map函数只从输入文件2看到了b,那么输出将会是key=b,value=1。第三个输入文件有一个a和一个c。
我们对所有的输入文件都运行了Map函数,并得到了论文中称之为中间输出(intermediate output),也就是每个Map函数输出的key-value对。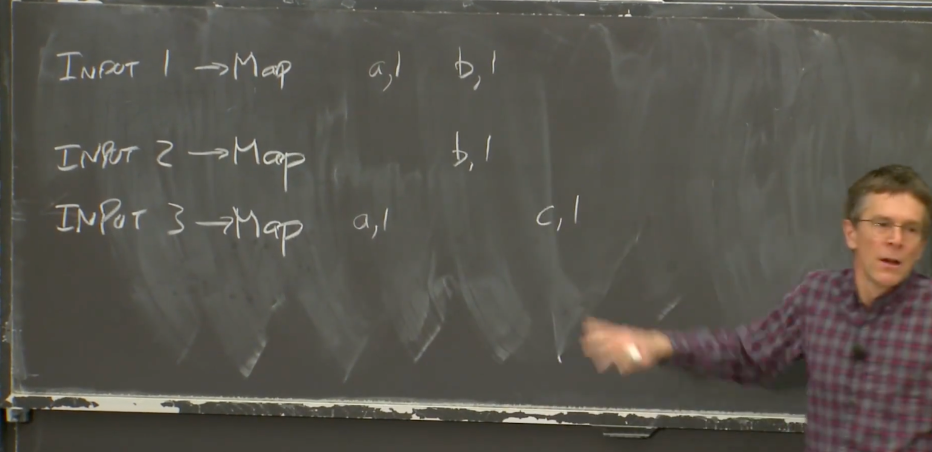
运算的第二阶段是运行Reduce函数。MapReduce框架会收集所有Map函数输出的每一个单词的统计。比如说,MapReduce框架会先收集每一个Map函数输出的key为a的key-value对。收集了之后,会将它们提交给Reduce函数。我们收集所有的b,并将它们提交给另一个Reduce函数。这个Reduce函数的入参是所有的key为b的key-value对。对c也是一样。所以,MapReduce框架会为所有Map函数输出的每一个key,调用一次Reduce函数。
Reduce函数只需要统计传入参数的长度,甚至都不用查看传入参数的具体内容,因为每一个传入参数代表对单词加1,而我们只需要统计个数。最后,每个Reduce都输出与其关联的单词和这个单词的数量。所以第一个Reduce输出a=2,第二个Reduce输出b=2,第三个Reduce输出c=1。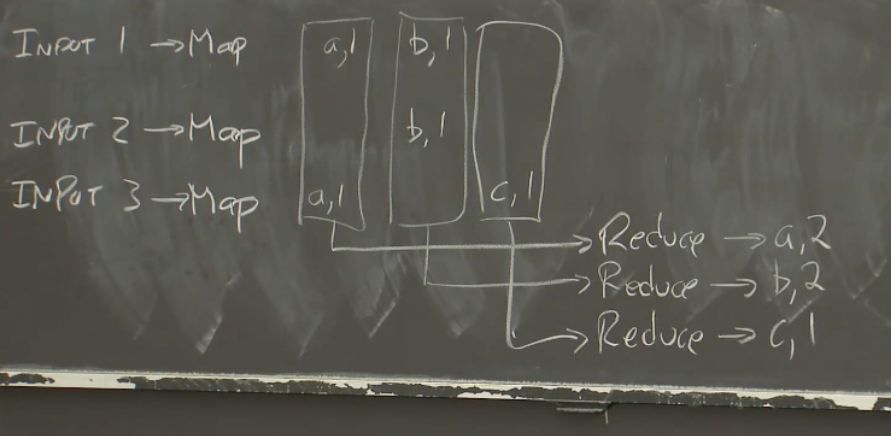
这就是一个典型的MapReduce Job。从整体来看,为了保证完整性,有一些术语要介绍一下:
- Job。整个MapReduce计算称为Job。
- Task。每一次MapReduce调用称为Task。
所以,对于一个完整的MapReduce Job,它由一些Map Task和一些Reduce Task组成。所以这是一个单词计数器的例子,它解释了MapReduce的基本工作方式。
5. Map函数和Reduce函数
Map函数使用一个key和一个value作为参数。入参中,key是输入文件的名字,通常会被忽略,因为我们不太关心文件名是什么,value是输入文件的内容。对于一个单词计数器来说,value包含了要统计的文本,我们会将这个文本拆分成单词。之后对于每一个单词,我们都会调用emit。emit由MapReduce框架提供,并且这里的emit属于Map函数。emit会接收两个参数,其中一个是key,另一个是value。在单词计数器的例子中,emit入参的key是单词,value是字符串“1”。这就是一个Map函数。Map函数中调用emit的效果是在worker的本地磁盘上创建文件,这些文件包含了当前worker的Map函数生成的所有的key和value。
Reduce函数的入参是某个特定key的所有实例。所以Reduce函数也是使用一个key和一个value作为参数,其中value是一个数组,里面每一个元素是Map函数输出的key的一个实例的value。对于单词计数器来说,key就是单词,value就是由字符串“1”组成的数组,所以,我们不需要关心value的内容是什么,我们只需要关心value数组的长度。Reduce函数也有一个属于自己的emit函数。这里的emit函数只会接受一个参数value,这个value会作为Reduce函数入参的key的最终输出。所以,对于单词计数器,我们会给emit传入数组的长度。这就是一个最简单的Reduce函数。一旦worker收集完所有的数据,它会调用Reduce函数,Reduce函数运算完了会调用自己的emit,这个emit与Map函数中的emit不一样,它会将输出写入到一个Google使用的共享文件服务中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- DP-背包问题
- Java版企业电子招标采购系统源码Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
- Windows11快速安装Android子系统
- Python之线程池设计实战
- django电子商务网站的设计与实现(程序+开题报告)
- 10-2 HNCST - 多线程4 - 线程同步Condition——python
- 在vue中使用高德地图点击打点,搜索打点,高德地图组件封装
- C++构建简单静态库实例(cmakelist)
- 数据特征工程 | PSO粒子群算法的特征选择原理及python代码实现
- H5网页漫画小说苹果cms模板系统源码+支持对接公众号+支持三级分销+内置火车头自动采集