PyTorch基础操作
一、Tensor
在 PyTorch 中,张量(Tensor)是一个核心概念,它是一个用于存储和操作数据的多维数组,类似于 NumPy 的 ndarray,但与此同时,它也支持 GPU 加速,这使得在大规模数据上进行科学计算变得更加高效。
在 PyTorch 中,张量的基本特性和功能包括:
-
多维数组:PyTorch 张量可以有多个维度,允许你存储和处理高维数据集,如图像(通常是 3 维:高度、宽度和颜色通道),视频(4 维:时间、高度、宽度和颜色通道)等。
-
数据类型:PyTorch 张量支持不同的数据类型,如 float32、float64、int8、int16、int32、int64 等。
-
设备兼容性:张量可以存储在 CPU 或 GPU 上,这意味着你可以利用 GPU 进行高效的数值计算。
-
自动微分:PyTorch 的一个关键特性是它的自动微分引擎(Autograd),这允许你自动计算张量的梯度,这对于训练神经网络非常重要。
-
与 NumPy 互操作性:PyTorch 张量可以轻松地与 NumPy 数组进行转换,使得在这两个库之间切换变得简单。
-
API 富集性:PyTorch 提供了丰富的 API 来创建和操作张量,包括数学运算、线性代数、统计和随机抽样等功能。
-
动态计算图:PyTorch 使用动态计算图(称为动态计算图),这允许在运行时构建计算图,为模型构建提供更大的灵活性。
1.1Tensor初始化
一些初始化的方法:
torch.empty(size): 创建一个未初始化的张量。这意味着张量中的数据可能是任何值,包括非常大或非常小的数字。
torch.zeros(size): 创建一个指定大小的张量,并用 0 填充。
torch.ones(size): 创建一个指定大小的张量,并用 1 填充。
torch.rand(size): 创建一个指定大小的张量,并用区间 [0, 1) 内的均匀分布的随机数填充。
torch.randn(size): 创建一个指定大小的张量,并用标准正态分布(均值为0,方差为1)的随机数填充。
torch.arange(start, end, step): 创建一个一维张量,包含从 start 到 end 的序列,间隔为 step。
torch.linspace(start, end, steps): 创建一个一维张量,包含从 start 到 end 的等间隔的 steps 个点。
torch.eye(n): 创建一个 n x n 的单位矩阵。
torch.full(size, fill_value): 创建一个指定大小的张量,并用 fill_value 填充。
torch.tensor(data): 从 data (例如列表、数组)创建张量。
torch.clone(): 克隆一个张量,新的张量与原始张量有相同的大小和数据,但存储在不同的内存地址。
torch.from_numpy(ndarray): 从 NumPy 数组创建张量。
?几个示例:
import torch
# 创建一个 3x3 的张量,其中所有元素都是 0。
# 这在初始化权重或清除数据时非常有用。
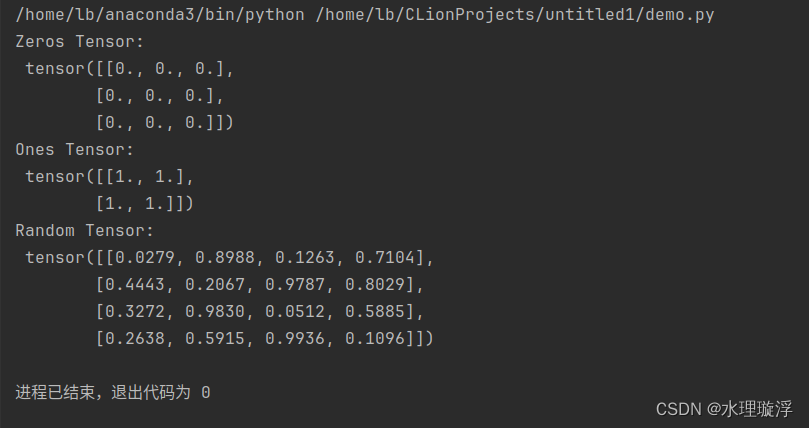
zeros_tensor = torch.zeros(3, 3)
print("Zeros Tensor:\n", zeros_tensor)
# 创建一个 2x2 的张量,其中所有元素都是 1。
# 这在创建初始权重或需要所有元素都是1的情况下非常有用。
ones_tensor = torch.ones(2, 2)
print("Ones Tensor:\n", ones_tensor)
# 创建一个 4x4 的张量,其中所有元素都是 0 到 1 之间的随机数。
# 这在需要随机初始化数据时非常有用。
rand_tensor = torch.rand(4, 4)
print("Random Tensor:\n", rand_tensor)
结果:
1.2 tensor的属性
dtype: 表示Tensor中元素的数据类型,例如torch.float32, torch.int64等。
shape: Tensor的形状,即各个维度的大小。例如,一个3x4的矩阵将有一个形状为(3, 4)的Tensor。
device: Tensor所在的设备,如CPU或GPU。例如device='cuda:0'表示Tensor存储在第一个GPU上。
layout: 内存中Tensor的布局方式,如torch.sparse_coo_tensor
示例:
import torch
# 设置设备为CPU,后续声明为CUDA,但最终使用的是CUDA
dev = torch.device("cpu")
dev = torch.device("cuda")
# 创建一个包含两个元素[2, 2]的一维张量,数据类型为float32,存储在CUDA设备上
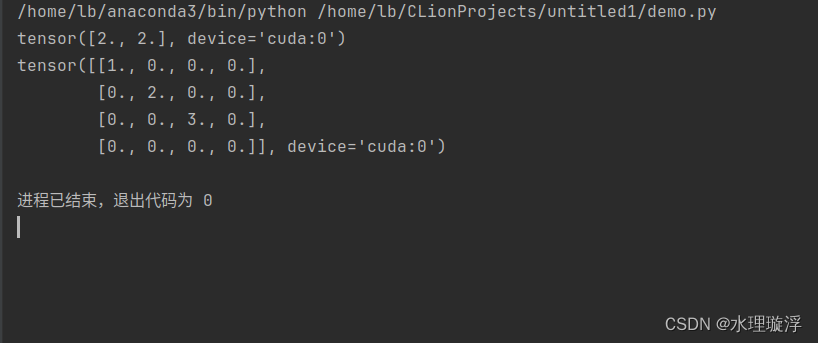
a = torch.tensor([2, 2], dtype=torch.float32, device=dev)
print(a)
# 创建一个二维张量,表示稀疏张量的坐标索引
i = torch.tensor([[0, 1, 2], [0, 1, 2]])
# 创建一个一维张量,表示稀疏张量在这些坐标位置的值
v = torch.tensor([1, 2, 3])
# 使用坐标索引和值创建一个4x4的稀疏张量,然后转换为密集张量
# 数据类型为float32,存储在CUDA设备上
a = torch.sparse_coo_tensor(i, v, (4, 4), dtype=torch.float32, device=dev).to_dense()
print(a)
结果:
- 密集张量:在密集张量中,每个元素(包括零值)都会被存储。例如,一个 3x3 的密集张量将存储所有 9 个元素。
- 稀疏张量:稀疏张量仅存储非零元素及其索引,这使得它们在处理大量包含零值的数据时更加高效。例如,如果一个 3x3 的矩阵大部分元素为零,稀疏张量只会存储非零元素及其位置信息。
1.3tensor的算术运算
1.3.1加法
c = a + b
c = torch.add(a,b)
a.add(b)
a.add_(b)前三个一样输出的都是a和b的和,不改变a,b的值
a.add_(b) 会把他们的和赋值给a
1.3.2乘法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 02 MyBatisPlus核心功能之基于Mapper接口CRUD+基于Service接口实现CRUD
- 排序算法-选择排序
- ffmpeg写YUV420文件碰到阶梯型横线或者条纹状画面的原因和解决办法
- Whale 帷幄创始人叶生晅荣获亿欧 2023 中国泛人工智能优秀人物 TOP 20
- 为什么在取消全局loading不生效了?
- 伦敦银对金融市场的影响
- SRC实战 | 某公司后台sql注入
- HCIP-BGP实验4
- 下一站,上岸@24考研er
- 数据结构学习 Leetcode300最长递增子序列