【面试题】消息堆积解决方案
发布时间:2024年01月06日
📝作者简介:
大家好,我是CBeann,CSDN博客专家,阿里云专家博主。
22届校招进入阿里广告部门从事Java开发工程师。
平时有空会帮大家解决问题,模式面试和日常答疑,并且提供免费云服务器使用。
有一起卷的可以加我的微信:CHAI956056312,大家一起学习,一起进步。
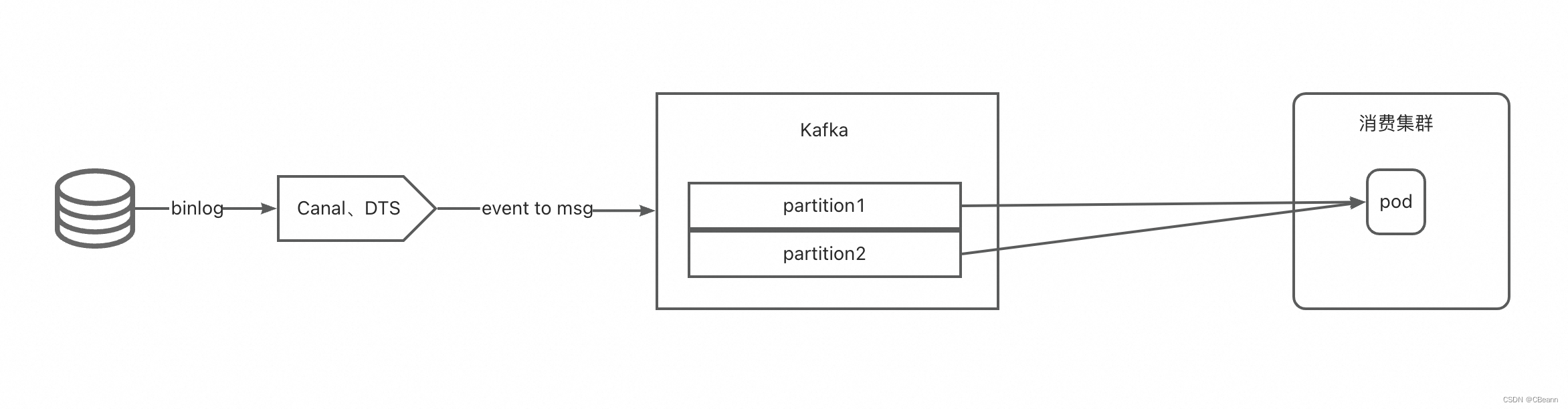
1、背景
临近双十一了,产品找到开发的同学帮忙把某些广告主的广告投放时间延长两个月并重新送审风控审核,所以开发要订正数据,直接改库并设置广告的标志为是送审风控。此时数据库有大量的送审binlog消息到kafka,从而出现了消息量剧增,下游消费延迟报警。
整个链路的demo如下图所示。
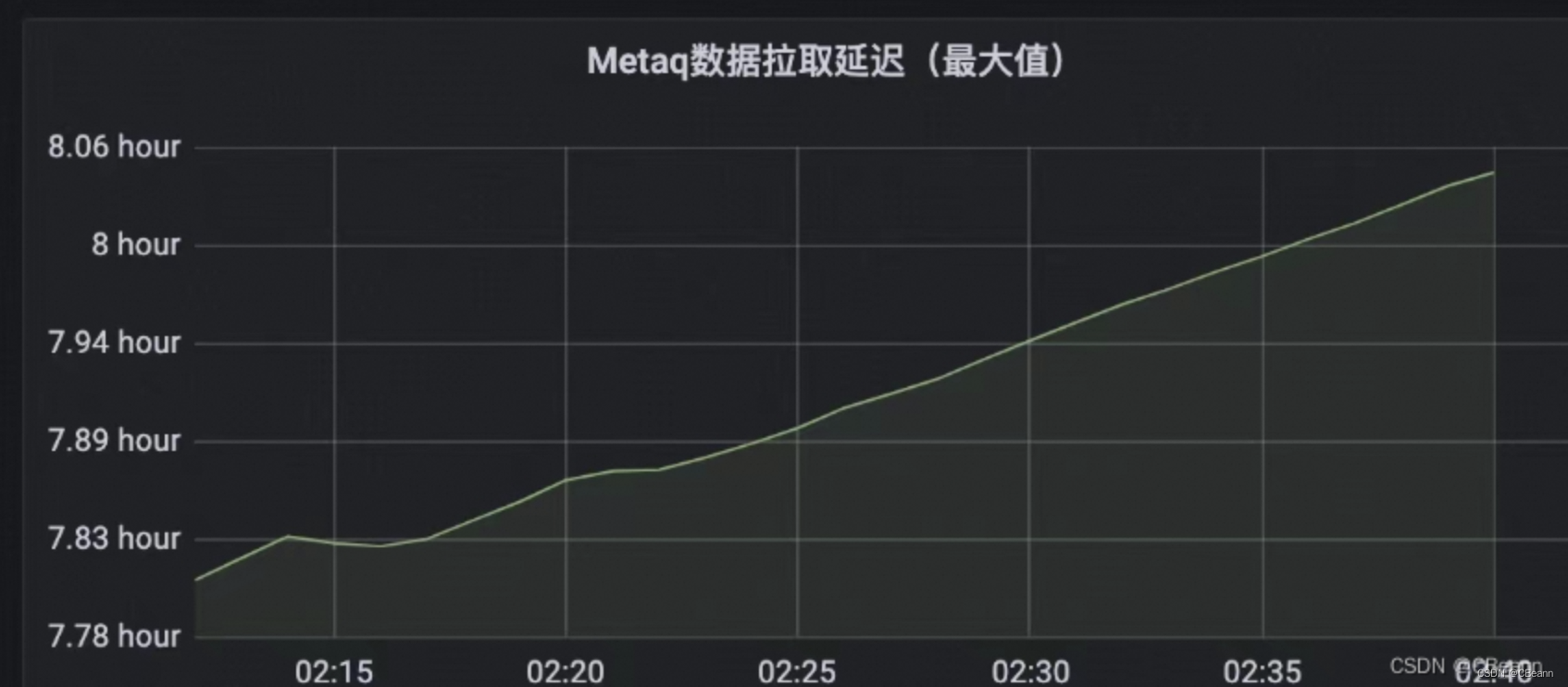
中间件监控如下图所示
2、解决方案
2.1、加机器
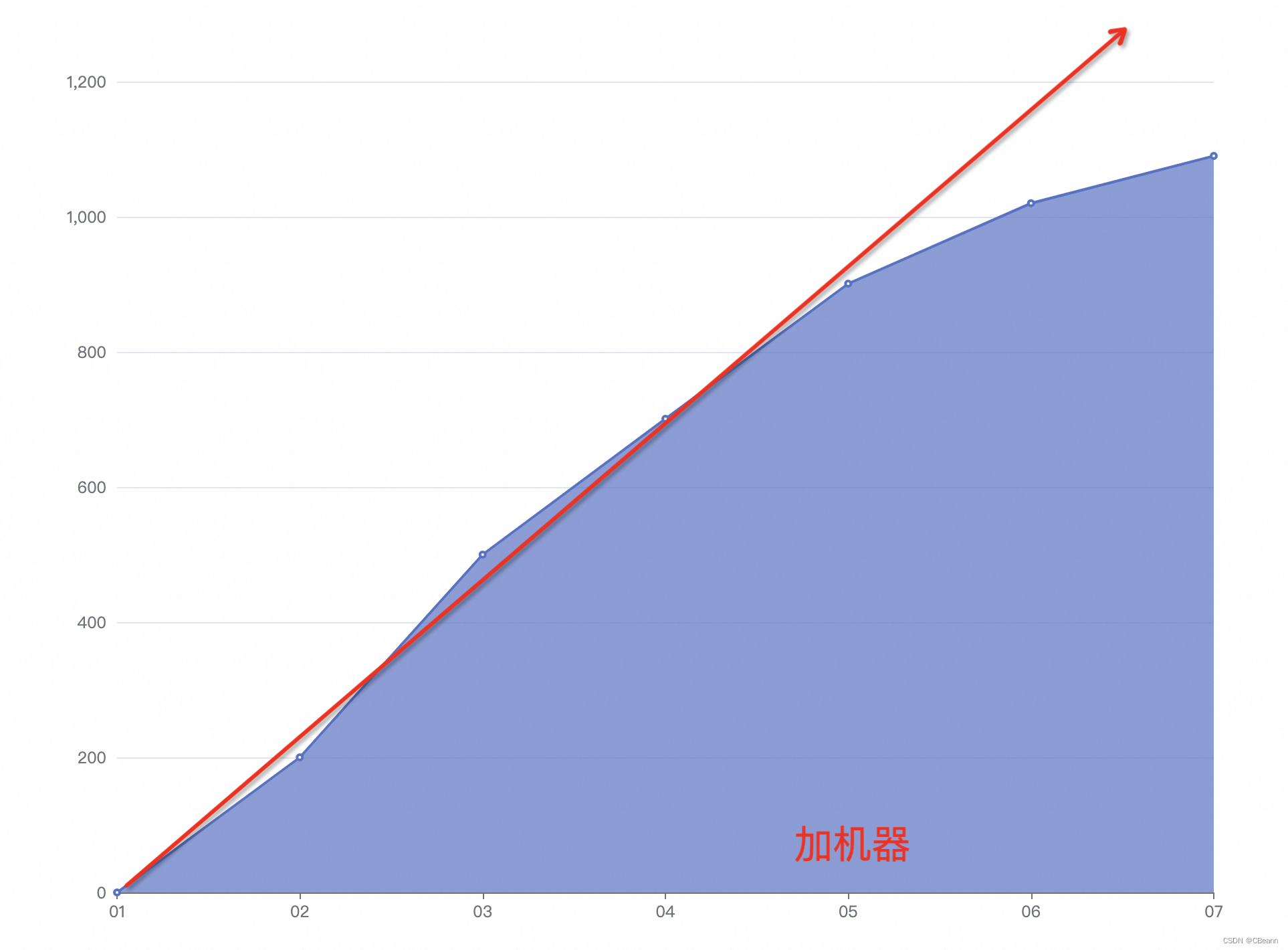
一开始以为偶尔出现的一波流量,加一台机器看看。所以整个链路如下图所示。机器总数小于分区总数。

观察了一段时间,发现延迟增长缓慢,说明有效果,如下图所示。但是还是延迟。
2.2、继续加机器
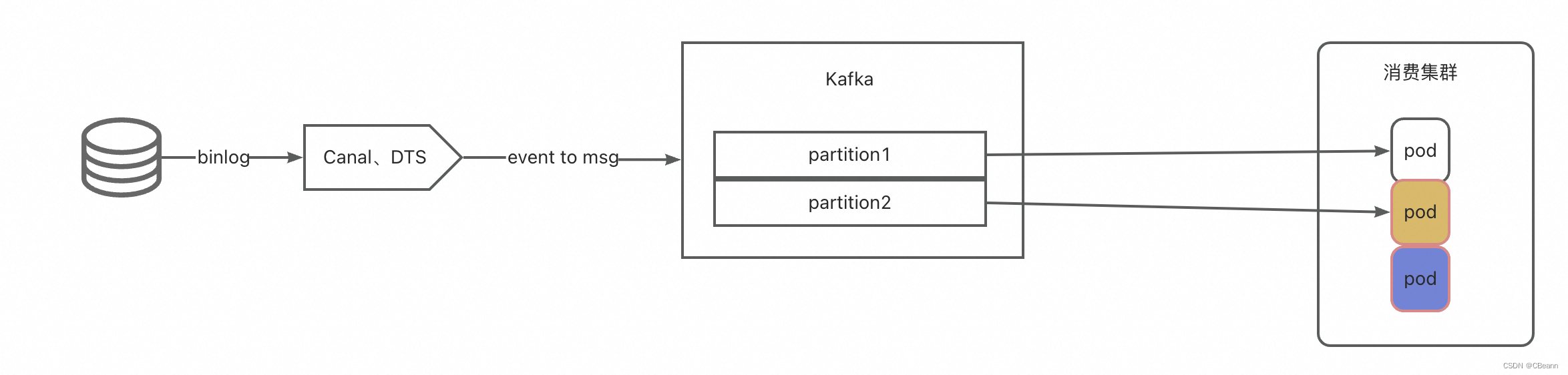
发现上面加机器有效果,继续加机器,如下图中的蓝色pod,此时延迟还是增长,不符合预期。此时我了解到当机器等于分区数时,再加机器没有效果。因此需要提高单台机器的消费能力。
2.3、多线程
提升单台机器的消费能力开多线程。拉取消息的时候批量拉,如下图所示,我拉三条消息,收到消息后抛到线程池(三个线程)中。此时系统消费能力提高三倍。
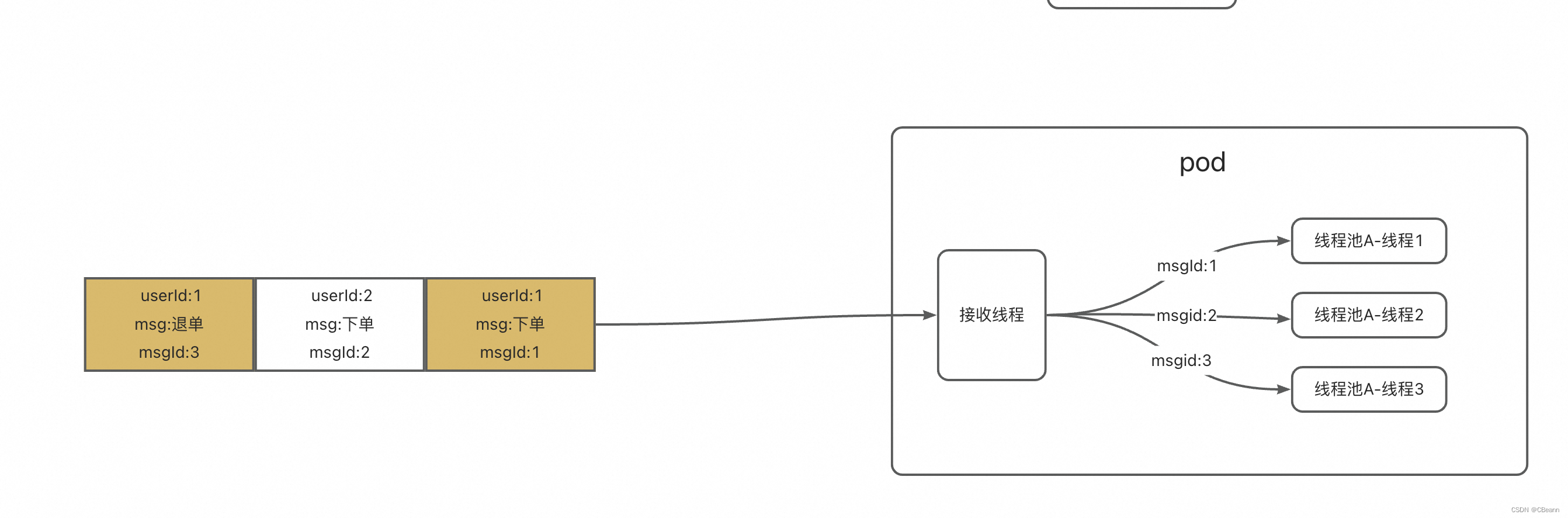
此时遇到不顺序消费问题,如上图所示,当我的消息需要顺序消费(同userld顺序)时,但是因为我把消息打平了,所以出现了不顺序消费的问题。
2.4、多线程-顺序消费
通过对消息中的业务key(本文中的userid)做路由,如下图中的接收线程中的hash,再路由到固定的线程,从而实现本批次的顺序消费。此处参考了Netty的Reactor模型(加分项)。
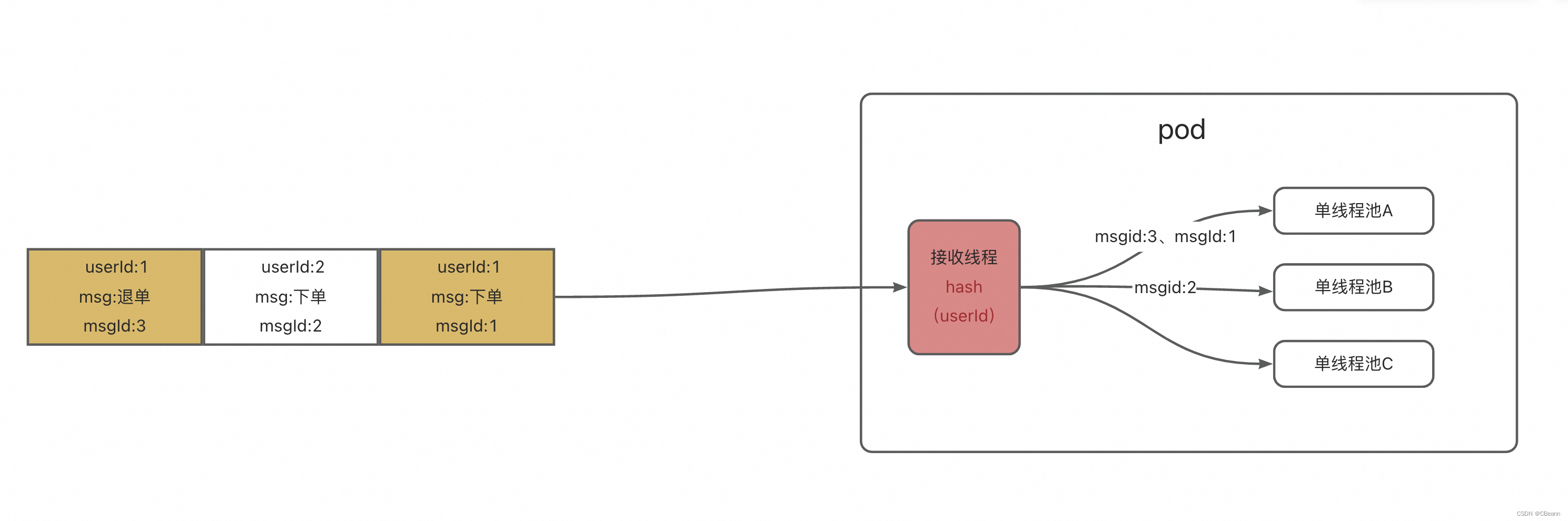
- 偏移量什么时候提交?
本批次全部消费完提交,不论失败与成功。使用CDL。 - 消费失败怎么办?
记录日志,人工接入。
3、案例拓展
- 大盘监控:完善的监控报警方案,早发现早治疗,别等用户反馈。老板喜欢看大盘。
- 变更通知:操作前一定要周知上下游,包括异步链路。
- 批次灰度:上一批观察一下兄弟团队反馈,没问题推下一批。
- 流量隔离:针对此方案,我们专门搭建了一个消费消费的分组或集群,能实现上述情况出现时不影响正常流量。

文章来源:https://blog.csdn.net/qq_37171353/article/details/135420317
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 算法的特性有哪些?
- 负债 1092.8 亿美元,苹果成全球负债第二多的科技公司丨 RTE 开发者日报 Vol.131
- Zookeeper源码剖析:深入理解Leader选举机制
- PHP Laravel 框架的 session cookie 的安全设置
- 商品销售数据爬取分析可视化系统 爬虫+机器学习 淘宝销售数据 预测算法模型 大屏 大数据毕业设计(附源码)?
- pycharm学生认证免费使用专业版
- 【GO语言卵细胞级别教程】02.GO变量和数据类型
- VSCode编辑器下载与安装
- 腾讯云新用户的定义及专属优惠活动汇总
- 乐优商城(四)商品规格管理