【面试总结】Java面试题目总结(一)
(以下仅为个人见解,如果有误,欢迎大家批评并指出错误,谢谢大家)
1.项目中的验证码功能是如何实现的?
- 第一步:在项目的
pom.xml文件中导入EasyCaptcha的依赖;
<dependency>
<groupId>com.github.penggle</groupId>
<artifactId>easy-captcha</artifactId>
<version>2.6.2</version>
</dependency>
- 第二步:
Controller层写一个captcha接口,接收前端请求
@Controller
public class CaptchaController {
@RequestMapping("/captcha")
public void captcha(HttpServletRequest request, HttpServletResponse response) throws Exception {
CaptchaUtil.out(request, response);
}
}
- 第三步:前端页面定义接口
<img src="/captcha" width="130px" height="48px" />
不要忘了把`/captcha路径从拦截器中排除
2.怎么自己实现一个验证码功能?从生成到回显到验证,怎么设计?
- 生成验证码:
创建一个生成验证码的类,这个类专门负责生成随机的验证码字符串,并且生成对应的验证码图片;
可以使用Java的 BufferedImage 类来创建验证码图片,并在图片上绘制生成的验证码文字。
- 回显验证码到前端页面:
将生成的验证码图片以 Base64 编码字符串的形式返回给前端页面,或者直接生成一个验证码图片的 URL 地址,让前端页面可以通过这个 URL 获取验证码图片进行展示。
下面是一个小Demo:
// 验证码生成器类
public class CaptchaGenerator {
public static Captcha generateCaptcha() {
// 在这里使用你选择的验证码生成库,例如 EasyCaptcha 或者其他验证码生成工具
// 生成验证码并返回
}
}
// Controller 类
@RestController
public class CaptchaController {
// 生成验证码图片并返回给前端
@GetMapping("/captchaImage")
public ResponseEntity<String> getCaptchaImage() {
Captcha captcha = CaptchaGenerator.generateCaptcha();
String base64Image = captcha.getBase64Image(); // 获取验证码图片的 Base64 编码字符串
return ResponseEntity.ok(base64Image);
}
3.==和equals的区别?
==操作符用于比较两个对象的引用是否相同,即它们是否指向内存中的同一块地址。
对于基本数据类型,==用于比较它们的数值是否相等。
当使用==操作符比较两个对象时,如果两者指向内存中的相同对象,则返回 true;否则返回 false。
equals 方法是 Object 类中定义的方法,用于比较两个对象的内容是否相等。
在 Object 类中,equals 方法默认实现是与 == 相同的,即比较两个对象的引用是否相同。
通常情况下,我们会在自定义类中重写 equals 方法,以便根据对象的内容来判断是否相等。
总结起来,== 用于比较两个对象的引用是否相同,而 equals 方法用于比较两个对象的内容是否相同。
4.重写equals要重写什么?为什么?
???????在Java中,对象的hashCode方法用于计算对象的哈希码,而哈希码在哈希表中用于快速查找对象。当我们将自定义对象用作哈希表的键时,需要确保对象的hashCode方法返回的哈希码能够与equals方法一致。
???????哈希表在查找键值对时,首先会根据键的哈希码找到对应的桶,然后在桶中使用equals方法进行比较来找到对应的值。如果equals方法被重写,hashCode方法没有被重写,那么在哈希表中查找时,可能无法正确地找到对应的值。
???????根据Java规范,如果两个对象根据equals方法是相等的,那么它们的hashCode方法应该返回相同的值。所以在重写equals方法时,为了保证对象的一致性,必须同时重写hashCode方法,以确保相等的对象具有相等的哈希码,从而在哈希表中正确地进行查找。
5.见过哪些重写equals的类?
- String类:String类重写了equals方法,用来比较字符串的内容是否相等。
- Integer类:Integer类重写了equals方法,用来比较两个整数对象的值是否相等。
- Boolean类:Boolean类重写了equals方法,用来比较两个布尔值对象是否相等。
- Date类:Date类重写了equals方法,用来比较两个日期对象是否代表同一时刻。
- 自定义类:在自定义的类中,如果需要自定义相等性判断逻辑,通常会重写equals方法。比如,你可以在自定义的Person类中重写equals方法,根据姓名和年龄来判断两个人是否相等。
6.两个对象的Hashcode相等,这两个对象相同吗?
???????如果两个对象的hashcode相等,它们并不一定相同,这就是所谓的哈希冲突。因为哈希码值是通过对象的内容计算出来的,不同的对象可能会有相同的哈希码值。这种情况下,哈希表中就会出现冲突,需要使用equals方法进行进一步的比较。
???????当我们使用具有哈希表结构的集合类(例如HashMap、HashSet等)时,对象在存储和检索时会使用哈希码值。哈希表可以看做是一个数组,每个元素都是一个链表或红黑树。当我们向哈希表中添加元素时,系统会自动调用该元素的hashCode方法,计算出哈希码值,并将其插入到对应的位置上。当我们需要查找元素时,系统也会先使用hashCode方法计算出哈希码值,然后根据哈希码值找到对应的位置,最后使用equals方法进行比较,找到目标元素。
???????因此,如果两个对象的hashCode相等,只能说明它们存储在哈希表中的位置相同,但不能说明它们一定相同。只有在hashCode相等的情况下,再使用equals方法进行比较,才能判断两个对象是否相等。
7.介绍一下类加载器中的双亲委派?
???????类加载器(Class Loader)是负责加载Java类文件并将其转换为Java虚拟机(JVM)可识别的二进制格式的重要组件。在Java程序运行时,每个类加载器都会维护一棵类加载器层次结构。
???????双亲委派模型(Parent Delegation Model)是类加载器层次结构中的一个重要概念。它是指当类加载器收到一个类加载请求时,它首先会把这个请求委托给它的父类加载器去处理,如果父类加载器还存在父类加载器,则依次向上委托,直到顶层的启动类加载器。如果父类加载器可以完成类加载任务,就返回类加载结果;否则,子类加载器才会尝试自己去加载。
???????双亲委派模型的优势在于保证了Java类的安全性和稳定性。因为在一个类加载器的作用域中,相同名称的类只会被加载一次,而且这个类的加载是由顶层的启动类加载器来完成的。这样就能够避免不同的类加载器对同一个类的多次加载,从而确保了类的唯一性和一致性
8.重写和重载的区别?
- 重写是指继承关系中,子类继承了父类中同名同参同返回值的方法,但是访问修饰符的限制一定要大于或等于被重写方法的访问修饰符。重写是运行时多态。
- 重载是指在同一个类中,方法名相同,但是参数列表不同,如参数个数、类型和顺序等。重载是编译时多态。
9.Java多线程中int i进行i++操作会有什么问题吗?如何解决?
- 在Java多线程中,对一个整型变量 int i 执行 i++ 操作可能会引发线程安全性问题。这是因为 i++ 操作并不是原子操作,它包括读取 i 的当前值、对其进行加一操作、然后将结果写回 i。在多线程环境下,如果有多个线程同时对 i 执行 i++ 操作,就可能导致竞态条件和数据不一致的问题。
为了解决这个问题,可以采取以下几种方法来保证对 i 的操作是线程安全的:
-
使用synchronized关键字:
???????可以使用synchronized关键字来保护对 i 的操作,确保同一时刻只有一个线程可以执行 i++ 操作。例如:synchronized (this) { i++; } -
使用AtomicInteger类:
???????可以使用java.util.concurrent.atomic.AtomicInteger类来代替普通的 int 类型,它提供了一系列原子操作,可以保证对 i 的操作是线程安全的。例如:AtomicInteger atomicI = new AtomicInteger(0); atomicI.incrementAndGet(); -
使用volatile关键字:
???????使用volatile关键字修饰 i 变量,可以确保多个线程看到的是同一个变量副本,从而避免一些可见性问题。但这并不能解决i++操作的原子性问题,仍需要额外的手段来保证原子性。 -
使用ReentrantLock:
???????可以使用显式的锁来保护对 i 的操作,例如java.util.concurrent.locks.ReentrantLock。通过获取锁之后执行 i++ 操作,然后释放锁,来保证操作的原子性和线程安全性。
10.Redis中有很多Key同时过期,会发生什么现象?在项目业务中会有什么影响?
???????在Redis中,如果有很多Key同时过期,会导致Redis的性能下降,并且可能会引发一些问题,例如:
- Redis CPU 占用率上升:当有大量Key同时过期时,Redis会将其从内存中删除。这个操作可能会消耗大量的CPU资源,导致Redis的CPU占用率上升,影响Redis的性能和稳定性。
- 缓存穿透: 如果很多Key同时过期,并且这些Key都是热点数据,那么这些数据在被重新加载到Redis之前,如果有大量请求访问这些数据,就会导致缓存穿透问题,使得请求直接打到后端数据库,增加了数据库的负载。
- 缓存雪崩: 如果很多Key同时过期,那么这些Key在过期之后,如果都同时被请求到,就会导致缓存雪崩问题,使得请求都打到后端数据库,增加了数据库的负载。
- 数据丢失:如果Redis中的Key同时过期,并且没有进行持久化存储,那么这些过期的数据将会被永久删除。如果这些数据是重要的业务数据,可能会导致数据丢失的问题。
11.Redis中只知道某些数据的前缀,如何查找这一类数据?
在Redis中,可以使用KEYS命令来查找符合特定模式的Key。如果我们只知道某些数据的前缀,可以使用通配符*来匹配后面的字符,从而查找这一类数据。
例如,如果我们想查找所有以"foo_"为前缀的Key,可以使用以下命令:
KEYS foo_*
这个命令会返回所有以"foo_"为前缀的Key列表。需要注意的是,KEYS命令会扫描Redis中的所有Key,如果数据量很大,可能会对Redis的性能产生影响。因此,应该尽量避免频繁地使用KEYS命令。
12.Redis中Keys和Scan的区别?你推荐用哪一个?
Keys和Scan都是Redis中用于查找Key的命令,但它们在实现方式和使用场景上有所不同。
Keys命令会扫描Redis中所有的Key,返回符合特定模式的Key列表。这个命令简单易用,但如果Redis中的Key数量很大,就可能会对Redis的性能产生影响。因此,不建议在生产环境中频繁使用Keys命令。- 相比之下,
Scan命令更加高效和安全。Scan命令通过游标分步扫描整个数据库,每次返回一部分数据,直到遍历完整个数据库。这种方式可以避免在一次操作中对整个数据库进行扫描,从而减轻Redis的负担,提高命令的执行效率。此外,Scan命令还支持并发修改和过期Key的情况,可以保证在执行期间不会出现数据丢失或重复访问的问题。
13.MySQL数据库中int(5),存储1,查询结果是?
???????在MySQL中,对于int(5)来说,括号中的数字只表示显示宽度,并不会影响存储或数据类型的范围。所以存储值为1时,查询结果仍然会返回整数1,后面不会出现乱码。
???????这种情况与char和varchar是不同的。对于char和varchar类型,指定的长度是用于限制存储的实际字符数量,而int(5)中的5只是用于指定展示宽度,并不影响实际存储的值。
14.char和Varchar的区别?
char:char类型是一种固定长度的字符类型,需要指定存储的最大字符数量。存储的值会被固定在指定长度内,如果存储的值超过了定义的长度,会发生截断。如果不足指定长度,会在末尾用空格进行填充;varchar:varchar类型是一种可变长度的字符类型。它也需要指定存储的最大字符数量。但是varchar类型存储的值会根据实际长度动态调整占用的存储空间,不会进行填充或截断。只占用实际需要的存储空间。
15.id = 1 ,怎么给他加一个查询锁?
???????在MySQL中,可以通过使用SELECT ... FOR UPDATE语句为特定的行添加查询锁。这样做可以确保在当前事务中对该行的读取操作不会被其他事务所修改。
SELECT * FROM your_table WHERE id = 1 FOR UPDATE;
16.如何给name字段加一个索引。
???????可以在已经存在的表上为需要优化查询的字段创建索引:
CREATE INDEX idx_name ON your_table (name);
17.索引列有null值会对索引列有影响吗?
索引列有
NULL值会对索引的效率和查询结果产生影响。
- 在
B-Tree索引中,NULL值被视为一个特殊值,与其他值分开存储。如果索引列包含NULL值,则在索引中将为每个NULL值保存一个指针。这样,当查询需要查找NULL值时,它会使用这些指针来定位匹配的行。 - 然而,由于
NULL值不是实际的值,因此它们无法进行比较运算。因此,在使用索引进行排序或范围查询时,包含NULL值的列通常不会被使用。 - 另外,当查询条件中包含索引列时,如果列包含
NULL值,那么索引可能无法使用。例如,如果查询条件是WHERE index_column = 5,并且索引列包含NULL值,那么索引可能无法使用,因为索引无法判断NULL值是否等于 5。 - 需要注意的是,如果索引列中包含大量的
NULL值,那么它可能会影响索引的性能和空间占用。因此,在设计索引时,需要考虑到数据的实际情况和查询需求,适当地处理NULL值。例如,可以使用部分索引或过滤条件来排除NULL值。
18.复合索引中有NULL值有影响吗?
???????在复合索引中,NULL 值对索引的影响是需要注意的。复合索引是由多个列组成的索引,用于加快查询的速度。当涉及到 NULL 值时,以下情况需要考虑:
-
NULL值的位置:
???????如果复合索引中的某个列包含NULL值,那么整个索引的键值也将是NULL。在这种情况下,该索引项将不会包含具体的值,只会标识为NULL。因此,在使用复合索引进行查询时,如果需要匹配到具有NULL值的列,那么该索引就会被使用。 -
匹配
NULL值:
???????如果查询条件中涉及到了包含NULL值的列,那么复合索引可能会被使用来筛选满足条件的行。 -
不匹配
NULL值:
???????当查询条件排除了NULL值时,复合索引可能无法使用,因为索引中的键值包含NULL值。此时,数据库可能会选择其他索引或执行全表扫描来满足查询条件。
???????需要注意的是,复合索引中的 NULL 值并不会影响索引的创建和维护。它主要会影响到查询时的索引使用情况。
???????总结起来,复合索引中的 NULL 值对索引的影响取决于具体的查询条件。如果查询需要匹配或排除包含 NULL 值的列,那么复合索引可能会被使用。而当查询条件不涉及 NULL 值时,NULL 值对索引的影响较小,可能会导致索引无法使用。因此,在设计复合索引时需要考虑到数据的特点和实际查询需求。
19.NOT IN 和 NOT EXISTS的区别?
NOT IN和NOT EXISTS都是用于条件查询中的否定操作符,用于筛选出不满足指定条件的结果。尽管它们可以达到相同的效果,但它们在实现方式和性能方面存在一些区别。
NOT IN是一个子查询操作符,用于从一个查询结果中排除满足给定条件的行。它通常与子查询结合使用,将子查询结果与外部查询进行比较,并返回不匹配条件的结果。
NOT EXISTS:NOT EXISTS也是一个子查询操作符,用于检查子查询的结果是否为空。如果子查询返回空集,则NOT EXISTS为真,否则为假。它常用于判断某个条件下是否存在符合要求的数据。
NOT IN使用一个子查询来获取比较值,而NOT EXISTS只需确定子查询是否返回结果。NOT IN适用于对单个列进行比较,而NOT EXISTS可以使用子查询中的任意条件进行比较。- 从性能角度来看,
NOT EXISTS在某些情况下可能更有效,因为它只需确定子查询是否返回结果,而NOT IN需要将所有结果加载到内存中进行比较。
20.请自己设计一个算法实现字符串的反转?
方法一:可以使用双指针来实现字符串的反转
- 首先将字符串转换为字符数组;
- 使用双指针法,一个指向数组的头部,一个指向数组的尾部。
- 交换数组头部和尾部的元素。
- 将指针向中心靠拢,重复执行第3步,直到指针相遇。
源码如下:
package com.kfm;
import java.util.Scanner;
/**
* {class description}
*
* @author SWP
* @version 1.0.0
*/
public class StringReversal {
public static String reverseString(String s){
if (s == null || s.length() == 0) {
return s;
}
// 将字符串转换为字符数组
char[] arr = s.toCharArray();
int left = 0;
int right = arr.length - 1;
while (left < right){
char temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
left++;
right--;
}
// 将字符数组转换为字符串
return new String(arr);
}
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String s = sc.nextLine();
System.out.println("反转后的字符串为:" + reverseString(s));
}
}
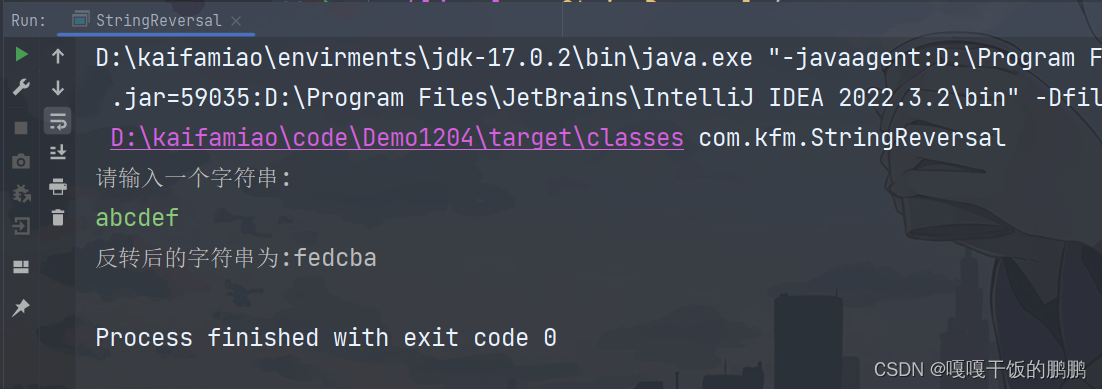
运行效果:
方法二:使用递归实现字符串的反转
源码如下:
package com.kfm;
import java.util.Scanner;
/**
* {class description}
*
* @author SWP
* @version 1.0.0
*/
public class StringReversal02 {
public static String reverseString(String s) {
// 递归结束的条件:当字符串长度为0或者1时,无需再反转字符串,直接返回字符串
if (s.length() <= 1) {
return s;
}
// 递归调用:将字符串分解为首字符和剩余部分,然后对剩余部分进行递归反转,并将首字符放在最后
return reverseString(s.substring(1)) + s.charAt(0);
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String s = sc.nextLine();
System.out.println("反转后的字符串为: "+ reverseString(s));
}
}
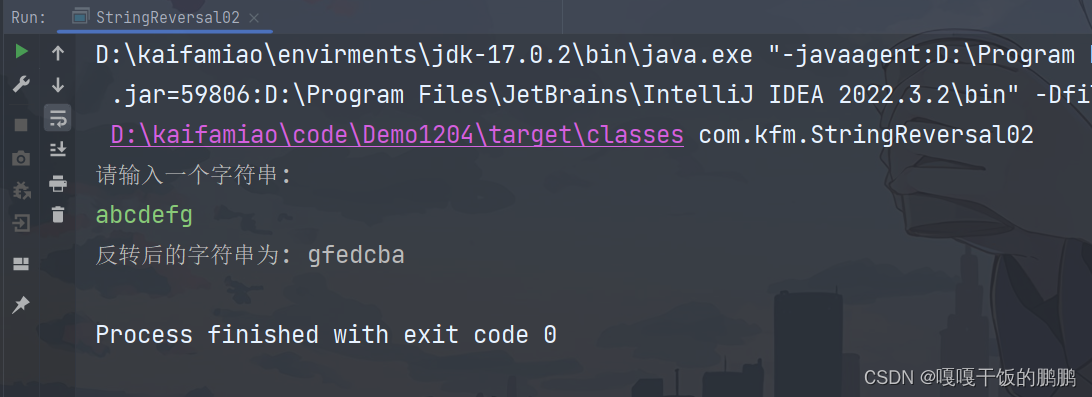
运行效果:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- IP 地址数据——IPv6 连接测试——你部署的网站安全吗。
- python实现定时访问web并点击按钮任务
- CH05_一致性
- YB75XXH系列是采用CMOS工艺制造,低功耗的高压稳压器
- Spring Boot学习随笔- 实现AOP(JoinPoint、ProceedingJoinPoint、自定义注解类实现切面)
- Postman接口测试工具最全实用教程
- Docker篇之修改docker默认磁盘占用目录
- pytorch04:网络模型创建
- 工具变量-ESG基金持股数据集(2008-2022年)
- 【踩坑记录】pytorch 自定义嵌套网络时部分网络有梯度但参数不更新