[软件工具]pdf多区域OCR识别导出excel工具使用教程
发布时间:2024年01月11日
首先我们打开软件,界面如下:
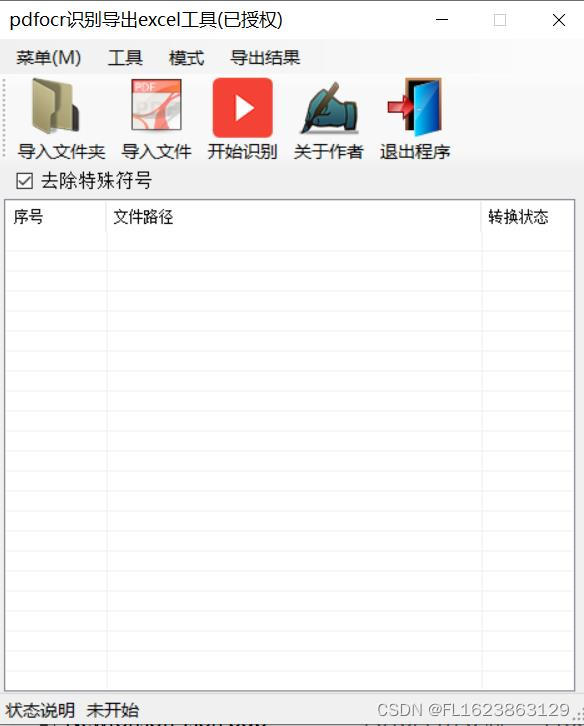
如上图,使用非常简单,步骤如下:
(1)选择工具-取模板选择一个pdf文件划定自己需要识别的区域,如果你选择第2页指定区域则软件统一识别所有pdf第2页指定区域,划定区域后需要添加区域,最后保存模板,这样下次启动软件无需再次取模板。
取模板截图:

(2)把含有pdf文件的文件夹拖拽到列表即可完成导入,之后点击开始识别就可以了,最后点击导出识别结果即可导出excel,文件为xlsx格式,操作非常简单。但是有几个问题需要注意:
第一:OCR识别和划定区域有关,识别效果依照实际情况确认,比如图像质量,模糊度已经场景复杂度,理论上背景简单计算机机打文字识别效果最好;
第二:不可能做到100%识别,目前不存在100%识别情况,即使业界最先进OCR算法也是不可能的,由于图像复杂性、多样性,光照、倾斜、模糊等,有的可能根本无法识别;
第三:为了防止软件在做低效运转,请尽量保持pdf页数越少越好
具体参考视频教程:
?
?
文章来源:https://blog.csdn.net/FL1623863129/article/details/135540016
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 源码开发实战:连锁餐饮数字化转型中的点餐小程序
- 刷题总结 1.24
- 助力工业焊缝质量检测,基于YOLOv8【n/s/m/l/x】全系列参数模型开发构建工业焊接场景下钢材管道焊缝质量检测识别分析系统
- QT程序第一次运行提示缺少某库的解决方法
- Linux 与 Shell
- 论文降重方法同义词替换的效果对比与评价 快码论文
- 初步理解多态
- 项目实战————苍穹外卖(DAY11)
- Linux的进程概念、进程标识符、进程状态
- leetcode.在链表中插入最大公约数