24、DHFormer :残差模块+Transformer,用了之后[腰不酸腿不疼了],世界一下子变得清晰了!
论文:
《DHFormer: A Vision Transformer-Based Attention Module for Image Dehazing》
本文由昌迪加尔大学于2023年12月15日发表于arXiv的《Computer Science》
链接:
[2312.09955] DHFormer: A Vision Transformer-Based Attention Module for Image Dehazing (arxiv.org)

1、Abstract:
雾气中的图像会受到降质的影响。去雾这样的图像是一个棘手且不恰当的问题。为了减轻雾气的影响并生成无雾图像,已经提出了许多基于先验和学习的策略。许多传统方法受到其对场景深度缺乏意识以及无法捕捉长程依赖性的限制。
在这篇论文中,提出了一种使用残差学习和视觉Transformer在注意力模块中结合的方法。该方法本质上包含两个网络:在第一个网络中,网络将雾图像的比例与近似传输矩阵估计残差图。第二个网络将这个残差图像作为输入,通过卷积层处理后,再将其叠加到生成的特征图上。然后通过全局上下文和深度感知Transformer编码器获得通道注意力。注意力模块在生成最终无雾图像之前推理空间注意力图。
实验结果,包括几个定量指标,证明了所建议方法的有效性和可扩展性。
2、Introduction:
在恶劣的天气中,常见的大气现象是雾气,它阻碍了自然场景的可视度(图1)。这源于光线在通过一系列微小的悬浮颗粒时发生吸收或散射。因此,观察到的场景具有降低的亮度、异常的对比度、色度和饱和度等人工制品。此外,这个问题由于它对复杂视觉任务模型性能的广泛影响,如卫星图像和自动驾驶,而引起了广泛关注。

不是,印度这大学挺有意思,发个论文还用咱们天安门的照片
这项工作的目的是近似给定其雾气的图像。通常,无雾图像是通过大气散射模型进行估计的。[4]。数学上表示为:
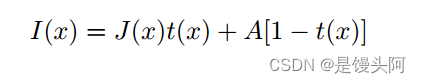
本工作提出了一种在注意力网络中结合卷积神经网络(CNN)和残差网络的图像去雾Transformer,其输出是无雾图像。输入到CNN的是受到雾影响的图像。该网络近似输出传输矩阵,其与受到雾影响的图像的比例作为残差网络的输入,输出是雾输入和潜在无雾图像之间的残差。
值得注意的是,这种网络不需要近似全局大气光A,因此对它引起的异常免疫。然后,注意力模块使用考虑图像全局上下文和场景深度的Transformer编码器来推理残差图像的通道属性。最后,空间注意力被近似,特征图被拼接以帮助估计最终的脱雾图像。
3、Related Work
本节讨论了与图像去雾相关的方法的简洁概述。它广泛地分为依赖于先验和基于学习的方法。
基于先验的方法关注于计算传输矩阵和全局大气光,并假定场景,使用手动定制的先验。Tang等人试图研究有助于去除雾气的最佳特征。他们得出结论,在去雾过程中,暗通道特征是最重要的特征。尽管训练模型是基于合成图像的块,但在实际数据上,模型表现良好。He等人估计了一个暗通道先验,并结合成像模型来估计单张图像中的雾深及其后续的去雾。这里的一个关键学习是,在雾气图像的一个或几个颜色通道中,存在像素低强度。作者还展示了块大小如何显著影响输出。Fattal等人提出了一种新的去雾模型,除了传输图外,还考虑了表面阴影,基于假设它们是正交的。
类似假设用于确定雾气的色度。尽管使用了来自不同来源的图像,但模型在去雾输出上的平均绝对误差小于7%。Meng等人利用传输图的边界极限以及基于L1范数的上下文正则化来建模图像去雾的优化问题。此外,这个函数基于对场景的少量假设进行建模,使其更具容错性。Zhao等人将雾气图像分成较小的块,然后按块进行传输图的局部估计。进一步优化结果在输出图像中实现了更精细的细节和明确的边缘。值得注意的是,由于这些方法依赖于手工制作的先验和场景约束,它们表现出较少的容错性和灵活性。
深度学习在图像去雾任务中的应用取得了显著的结果。在这些基于学习的方法中,模型在训练图像时学习一组参数和输入-输出映射,然后使用学习到的参数去雾其余图像,通常通过估计一个介质传输图。在Ren等人[17]中,使用一个粗糙的传输图网络学习从单个雾气输入图像到相应传输矩阵的映射。然后,另一个神经网络帮助优化无雾输出。Cai等人[18]使用一个可训练的基于CNN的模块近似传输图,其层被设计成提取先验使用特征。最后,使用双边正则化线性单位(Bilateral Rectified Linear Unit)提高输出质量。Zhang等人[19]提出的具有端到端图像去雾模块,其中DenseNet启发式编码器-解码器帮助近似传输矩阵,同时与大气光和去雾任务共同推理。尽管进一步使用判别器可以提高无雾图像的质量,但生成的输出具有低对比度。Li等人[20]提出了一种基于残差学习的去雾网络。
在这里,模型首先近似一个传输图,然后将其与输入图像的比例生成残差输出。此外,网络无需估计大气光的值。作者建议这种方法可以避免无效参数的影响。尽管如此,模型在处理速度上较慢,对天空明亮区域的去雾效果不佳。在[21]中,Gao等人使用CNN和视觉Transformer进行图像去雾。他们声称尽管CNN在先验方法中表现更好,但在详细信息检索方面落后于视觉Transformer。然而,他们没有考虑图像的全局特征,在暗场景和深度变化方面表现较弱。Li等人[22]提出了一种两阶段的图像去雾模块,其中第一阶段使用Swin Transformer和CNN,第二阶段提取局部特征,同时使用注意力机制。然而,去雾真实世界图像的计算成本很高。此外,网络的复杂性也会降低训练速度。
尽管基于学习的方法优于基于先验的方法,但用于进一步提高学习基网络性能的方法增加了网络的深度,导致添加更多的 Short-Cut ,从而增加网络复杂性,在某些情况下,也可能引入噪声。因此,通过包括残差网络,提出了一种可扩展的模型,当与视觉Transformer结合使用时,可以获得令人鼓舞的结果。
4、Methodology
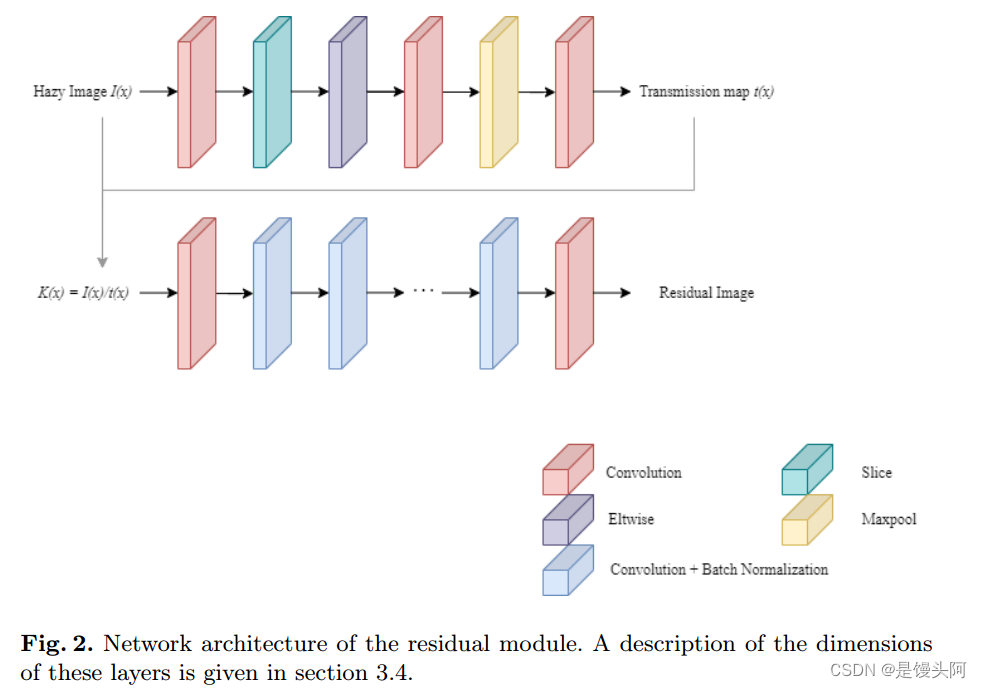
所提出的去雾方法的整体网络架构如图2和图3所示。该方法通过两个模块对输入图像进行去雾:第一个模块是残差网络,第二个模块是基于视觉Transformer的注意力模块。
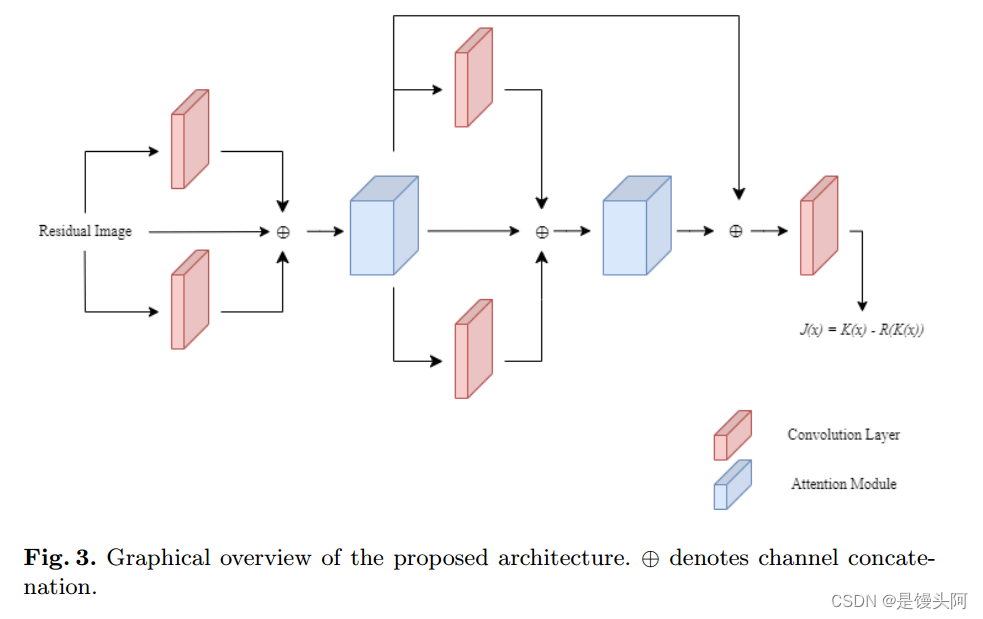
值得注意的是,尽管残差网络本身可以提供去雾图像,但由于输出并非完全无人工制品和颜色退化,因此结果令人不满意。此外,在本文中使用的质量指标上,该网络表现不佳。将其与注意力网络堆叠可以提高去雾性能,结果部分的各种质量指标将证明这一点。本文将讨论两个模块的工作原理和数据集描述。
4.1 Dataset
本文使用了NYU2深度数据集来训练模型,并使用SOTS和HSTS数据集来测试它。在实际应用中,存在大量雾气和去雾图像对的短缺,以便有效地训练去雾模型。特别地,由于NYU2数据集包含清晰的无雾图像及其深度图,使用这些深度图来获取传输矩阵,并将全局大气光赋予常数值,以最终生成所需的雾气数据集。作者将此应用于NYU2数据集中的1000张图像,并将其缩放到16 x 16 x 3,以便加快训练。
尽管训练和测试图像是在具有变化的室内场景中拍摄的,但模型在室外设置中也表现出色。为了测试模型,作者从[24]中分别选取了400和20张图像。其中,SOTS中的图像是在室内设置中拍摄的,而HSTS中的图像是在户外拍摄的。
4.2 The Residual Network
在此之前,图像去雾工作中对传输矩阵和全局大气光A的近似关注度增加。不稳定的场景条件使得这些变量的估计变得复杂。解决了方程(1),以便网络学习A和的传输矩阵值。这有助于避免由于对的错误估计而对网络架构造成的异常。
此外,残差学习的优势在于,当用于描述近似身份映射时,残差学习的影响优于直接学习。将方程(1)两边除以传输矩阵,作者得到:
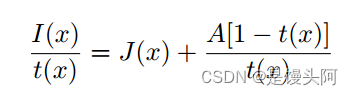
令
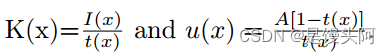
有
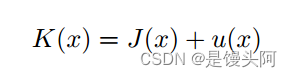
4.3 The Attention Module
本文提出的注意力网络灵感来自于CBAM,该网络依次推理通道和空间注意力。然而,为了生成这些注意力图,CBAM依赖于操作如最大池化和平均池化。用视觉Transformer来演示其有效性,推理空间注意力。使用注意力模块的目的是增强并进一步去雾残差网络的输出,同时考虑图像的全局上下文和场景深度。
在这里,Transformer作为输入,接受一维的 Token 序列。在前一步中连接输出的二维块被分割成分辨率为m*m的二维块,然后被展开成一维的 Token 。
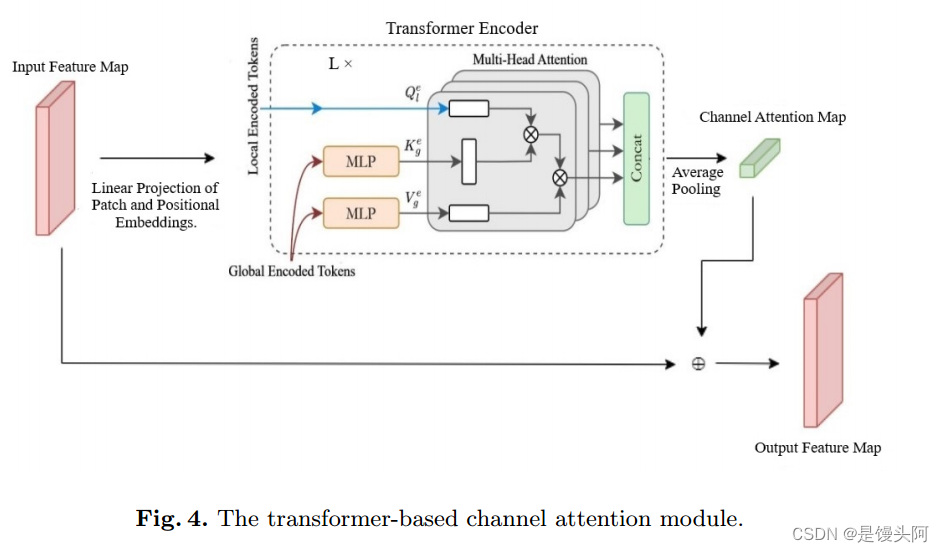
此外,为了保留这些块的位置信息,使用了可学习的位置嵌入Et。所使用的Transformer的详细架构如图4所示。转换器的最终输入向量是:
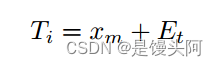
Transformer编码器包括多个头的自注意力(MHA)和多层感知机(MLP)模块,这些模块嵌入在相互交替的正则化(LN)层之间。对于第n个Transformer:
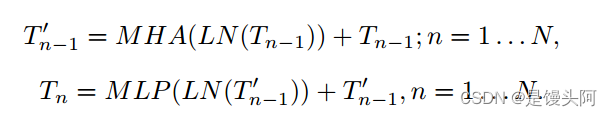
作者的方法利用全局上下文自注意力模块与传统的局部自注意力机制相结合,实现对空间交互的有效和高效建模,既包括长程范围,也包括短程范围。如图4所示,局部 Token 嵌入来自输入特征图的块投影。
为了生成全局 Token ,作者受到[26]的启发。网络然后利用局部 Query 进行通用的编码器操作,使用全局键和值。最后,对输出 Token 进行平均池化,得到通道注意力图。
5、 Results
所提出的架构在单个Nvidia RTX 3090 Ti GPU上训练了1000张来自NYU2数据集的图像,共150个周期,批处理量为16。
为避免过拟合,应用了随机裁剪,水平翻转和随机旋转等数据增强技术。对于测试模型,分别从SOTS和HSTS中选取了400和20张图像。与Fattal的[14],DehazeNet[18]和Gao等人[21]等许多最先进的图像去雾技术进行了对比。除了视觉结果外,还使用了PSNR,SSIM和FSIM等三个指标来评估恢复的脱雾图像的质量,并比较了不同方法的相对性能。这些指标的值越高,表示该恢复方法的性能越好。数学上,PSNR,SSIM和FSIM的定义如下:
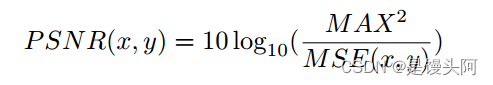
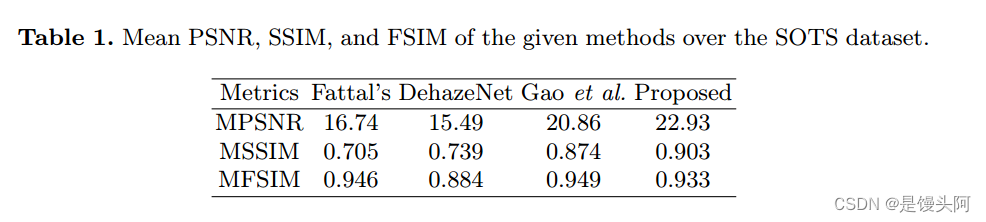
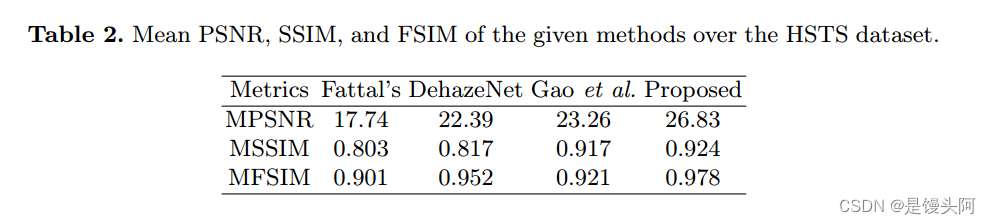
在HSTS数据集上的注意力模块。测试集被用来计算由这些结构形成的架构的平均SSIM和PSNR。所提出的模块报告的SSIM和PSNR比仅使用残差模块的模型提高了6.27%和11.43%。因此,这项研究证明了使用注意力网络和残差模块对于有效图像去雾的重要性。

6、Conclusion and Future Scope
本文提出了一种基于注意力模块的残差学习去雾网络。通常,获取无雾图像的工作依赖于从大气散射模型方程中近似传输矩阵和大气光。估计这些变量在问题欠定的情况下容易出错。在本文中,残差模块学习这些变量。通道注意力网络和Transformer池化的空间图进一步增强了残差 Backbone 网络的性能。
在NYU2,SOTS和HSTS数据集上的实验表明,所提出的方法的鲁棒性可以通过视觉结果和使用PSNR,SSIM和FSIM的定量评估进行验证。该方法不仅能够以很高的相似度估计与 GT 值的输出,而且还能做到不引入任何伪影。在未来,作者打算生成一个在室内和室外设置中捕捉的更大数据集,以便训练一个足够实时去雾的鲁棒网络。
7、有时觉得做个猫也挺好的

Professor Dog Egg Black is resting on his 300 square meter bed
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- NPDP证书,为什么这么多人考?
- JavaScript 删除数组中指定元素五种方法
- 基于猫群算法优化的BP神经网络实现数据预测
- Android Studio 安装和使用
- MySQL语法及IDEA使用MySQL大全
- win pip换源
- 无偿!全代码!增删改查+redis+token+mybatisplus 完整代码+讲解适合大一大二以及新手小白 Controller层讲解
- 【论文写作】新手科技论文写作:简介和摘要 绪论 方案 实验 总结 写作逻辑篇
- LabVIEW 智能化矿用定向钻机液压系统监测
- Java SE入门及基础(22)