【深度强化学习】目前落地的挑战与前沿对策
到目前为止,深度强化学习最成功、最有名的应用仍然是 Atari 游戏、围棋游戏等。即使深度强化学习有很多现实中的应用,但其中成功的应用并不多。为什么呢?本文总结目前的挑战。
所需的样本数量太大
深度强化学习一个严重的问题在于需要巨大的样本量。
用 Rainbow DQN 玩 Atari 游戏,达到人类玩家水平,需要至少1800万帧,且超过1亿帧还未收敛。(已经调优了多种超参数)
AlphaGo Zero 用了2900万局自我博弈,每一局约有100 个状态和动作。
TD3算法在MuJoCo物理仿真环境中训练Half-Cheetah、 Ant、 Hopper等模拟机器人,虽然只有几个关节需要控制,但是在样本数量100万时尚未收敛。甚至连Pendulum,Reacher这种只有一两个关节的最简单的控制问题,TD3也需要超过10万个样本。
现实的问题远远比Atari和MuJoCo复杂,其状态空间和动作空间都远大于Atari和MuJoCo,对于简单问题RL尚需要百万、千万级的样本,那对于现实复杂问题,可想样本量的恐怖。而且,在游戏中获取亿万样本并不困难,但是在现实中每获取一个样本都比较困难。举个例子,用机械手臂抓取一个物体至少需要几秒钟时间,那么一天只能收集一万个样本;同时用十个机械手臂,连续运转一百天,才能收集到一千万个样本,未必够训练一个深度强化学习模型。强化学习所需的样本量太大,这会限制强化学习在现实中的应用。
?
探索阶段代价太大
强化学习要求智能体与环境交互,用收集到的经验去更新策略。在交互的过程中,智能体会改变环境。在仿真、游戏的环境中,智能体对环境造成任何影响都无所谓。但是在现实世界中,智能体对环境的影响可能会造成巨大的代价。
在强化学习初始的探索阶段,策略几乎是随机的。
如果应用到推荐系统中,上线一个随机的推荐策略,那么用户的体验会极差,很低的点击率也会给网站造成收入的损失。
如果应用到自动驾驶中,随机的控制策略会导致车辆撞毁。
如果应用到医疗中,随机的治疗方案会致死致残。
在物理世界的应用中,不能直接让初始的随机策略与环境交互,而应该先对策略做预训练,再在真实环境中部署。 其中涉及离线强化学习(Offline RL),是一个很有价值的研究方向。
- 一种方法是事先准备一个数据集,用行为克隆等监督学习方法做预训练。
- 另一种方法是搭建模拟器,在模拟器中预训练策略。
?
超参数的影响非常大
深度强化学习对超参数的设置极其敏感,需要很小心调参才能找到好的超参数。
超参数分两种:神经网络结构超参数、算法超参数。这两类超参数的设置都严重影响实验效果。换句话说,完全相同的方法,由不同的人实现,效果会有天壤之别。
- 结构超参数: 神经网络结构超参数包括层的数量、宽度、激活函数,这些都对结果有很大影响。拿激活函数来说,在监督学习中,在隐层中用不同的激活函数(比如 ReLU、Leaky ReLU)对结果影响很小,因此总是用 ReLU 就可以。但是在深度强化学习中,隐层激活函数对结果的影响很大;有时 ReLU 远好于 Leaky ReLU,而有时 Leaky ReLU 远好于 ReLU。由于这种不一致性,我们在实践中不得不尝试不同的激活函数。
- 算法超参数: 强化学习中的算法超参数很多,包括学习率、批大小 (Batch Size)、经验回放的参数、探索用的噪声。(Rainbow 的论文调了超过 10 种算法超参数。)
实验效果严重依赖于实现的好坏。哪怕是一些细微的超参数区别,也会影响最终的效果。 即使都用同一个算法,比如 TRPO 和 DDPG 方法,不同人的编程实现,实验效果差距巨大。
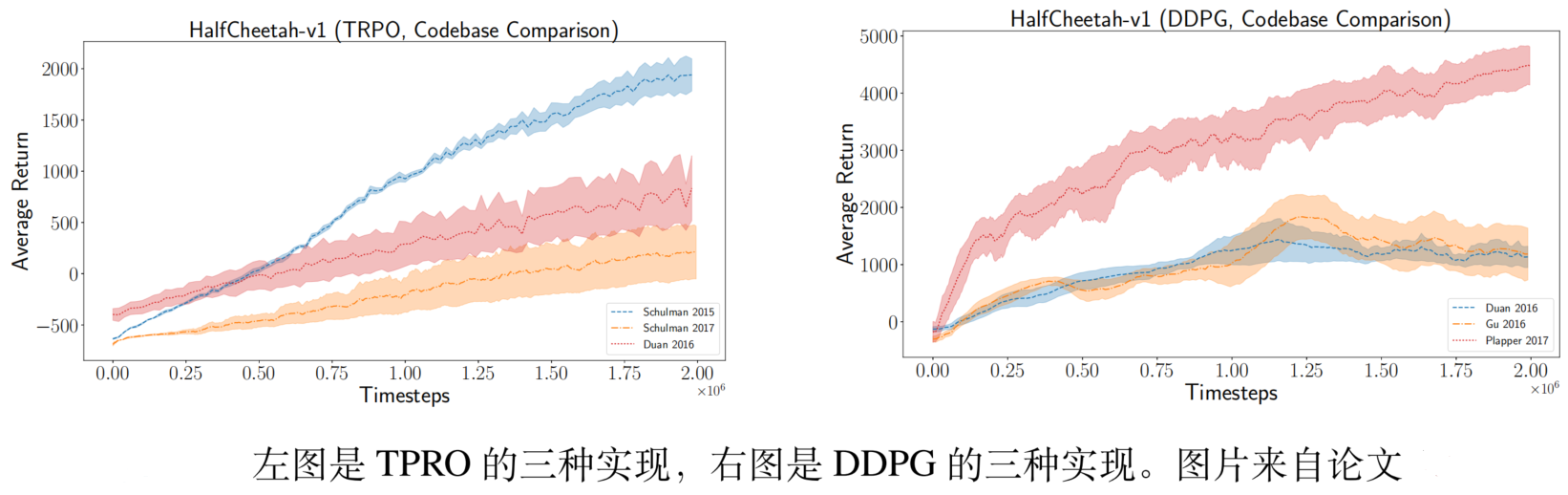
实验对比的可靠性问题。如果一篇学术论文提出一种新的方法,往往要在 Atari、MuJoCo 等标准的实验环境中做实验,并与 DQN、DDPG、TD3、A2C、TRPO 等有名的基线做实验对照。但是这些基线算法的表现严重依赖于编程实现的好坏,如果你把自己的算法实现得很好,而从开源的基线代码中选一个不那么好的做实验对比,那你的算法可以轻松打败基线。
?
稳定性极差
强化学习训练的过程中充满了随机性。除了环境的随机性之外,随机性还来自于神经网络随机初始化、决策的随机性、经验回放的随机性。想必大家都有这样的经历:用完全相同的程序、完全相同的超参数,仅仅更改随机种子(Random Seed),就会导致训练的效果有天壤之别。如果重复训练十次,往往会有几次完全不收敛。哪怕是非常简单的问题,也会出现这种不收敛的情形。
所以实验时即使代码和超参数都是对的,强化学习也有可能会出现不收敛的情况。监督学习则几乎没有这种担忧。

?
总结与未来
RL需要过多的数据量,且现实应用中收集数据成本和代价太大。即使收集到合适数据,训练网络时,超参数和随机种子等因素对模型的训练影响非常大,不稳定。
近年来,研究人员提出了多种方法来应对这些问题,提高RL的实用性和效率。以下是一些前沿的改进方法:
- 使用模拟环境和数据增强,减少对真实世界数据的需求,但是这样训练出来的模型如温室的花朵。
- 事先准备一个数据集,用行为克隆等监督学习方法做预训练,再进入现实做环境交互,进一步训练。
- 迁移学习与元学习,减少新任务所需数据量。
- 多任务学习和强化学习的结合,同时学习多个相关任务,共享知识以提高学习效率和泛化能力。
- 模型基的RL,构建环境模型以预测未来状态和奖励,减少对真实环境交互的依赖。
- 自适应超参数调整。
- 集成学习和强化学习结合,结合多个模型或策略,以减少单一模型或策略的不稳定性和偏差。
- 利用大模型,具身智能等技术,让模型更具泛化性。
本文内容为看完王树森和张志华老师的《深度强化学习》一书的学习笔记,十分推荐大家去看原书!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 不同类型的效度汇总
- 使用定时器外设的输入捕捉功能及测量脉冲宽度
- 国图公考:研究生可以考选调生吗?
- SSH原理
- 我们应该怎样定义 BTC Layer2?
- 解决虚拟机字体太小的问题
- 【干货】什么是SDN-软件定义网络
- 数据结构和算法-最小生成树(prim和krusakal)和最短路径问题(BFS和dijkastra和floyd)
- 用Delphi调用阿里云的OpenAPI更新动态域名解析记录
- 基于Freeswitch实现的Volte网视频通知应用