大数据机器学习 - 似然函数:概念、应用与代码实例
文章目录
大数据机器学习 - 似然函数:概念、应用与代码实例
本文深入探讨了似然函数的基础概念、与概率密度函数的关系、在最大似然估计以及机器学习中的应用。通过详尽的定义、举例和Python/PyTorch代码示例,文章旨在提供一个全面而深入的理解。

一、概要
在机器学习和统计学领域中,似然函数(Likelihood Function)是一个至关重要的概念。它不仅是参数估计的基础,而且在模型选择、模型评估以及众多先进的算法和技术中都有着广泛的应用。本文旨在全面但深入地探讨似然函数,从其基本定义和性质到在不同机器学习问题中的具体应用。
文章将首先介绍似然函数与概率密度函数的关系,然后通过最大似然估计(Maximum Likelihood Estimation, MLE)来展示如何利用似然函数进行参数估计。接着,我们会探讨似然函数在分类问题和回归问题中的应用,并使用Python和PyTorch代码段进行示例演示。
为了保持文章的技术深度,我们还将讨论模型选择与似然比检验,以及似然函数在最新研究进展中的角色,如在贝叶斯方法和复杂模型优化中的应用。
二、什么是似然函数
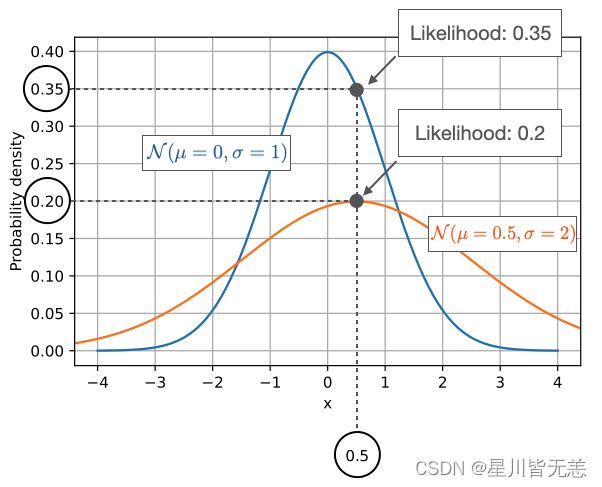
似然函数是一个在统计学和机器学习中经常出现的概念,它用于描述给定参数下,观察到某一数据样本的"可能性"。似然函数通常被记作 ( L(\theta \mid x) ),其中 ( \theta ) 是模型参数,( x ) 是观察到的数据。
数学定义
数学上,似然函数可以定义为:

似然与概率的区别
- 概率: 描述在固定的参数 ( \theta ) 下,某一事件 ( x ) 发生的可能性。
- 似然: 描述已经观察到事件 ( x ),而参数 ( \theta ) 是什么的可能性。
简单来说,概率是用来描述数据的生成模型,而似然是用来描述参数的合理性。
重要性
似然函数是许多统计推断方法的基础,包括但不限于:
- 最大似然估计(MLE)
- 贝叶斯推断
- 似然比检验
举例
考虑一个投掷硬币的例子,其中硬币正面出现的概率是 ( p ),反面出现的概率是 ( 1-p )。
若我们观察到了3次正面和2次反面,似然函数可以写作:

通过这一节,我们理解了似然函数的基础定义,区别和重要性,并通过一个简单的例子加深了理解。在接下来的部分,我们将更深入地探讨似然函数在机器学习和统计学中的应用。
三、似然函数与概率密度函数
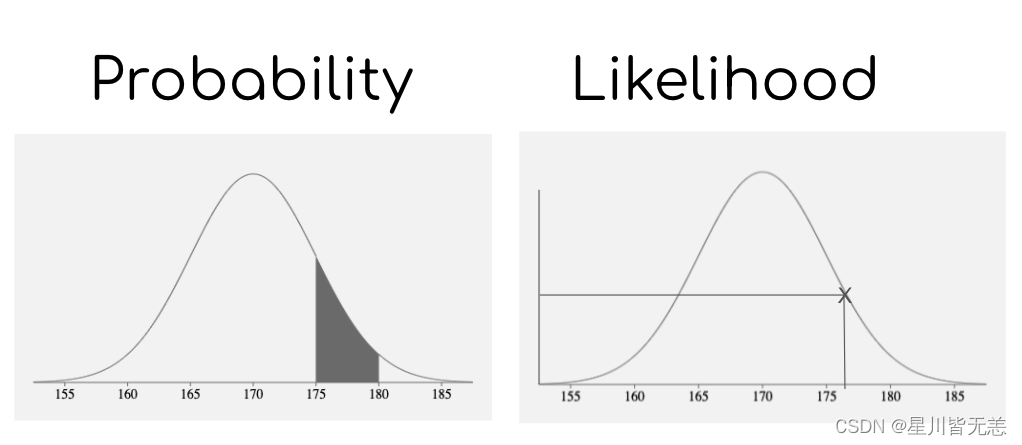
似然函数(Likelihood Function)和概率密度函数(Probability Density Function,简称PDF)都是描述数据和参数关系的重要数学工具。尽管两者在形式上具有相似性,它们在解释、用途和计算方面有着明显的不同。本节将详细介绍这两个概念的定义、区别和应用场景,并通过具体例子进行解释。
似然函数(Likelihood Function)
定义
似然函数用于量化在给定某参数值时,观察到某一数据样本的“可能性”。数学上,似然函数的定义如下:

例子
考虑一个简单的掷硬币实验,假设硬币正面出现的概率是 ( p )。若投掷了5次,出现了3次正面,2次反面。在这种情况下,似然函数可以表示为:

概率密度函数(Probability Density Function, PDF)
定义
概率密度函数描述了一个连续随机变量在各个特定值上的“密度”,也就是该值出现的相对可能性。对于离散随机变量,这个概念被称为概率质量函数(Probability Mass Function, PMF)。

区别与联系
- 角色互换: 在概率密度函数中,参数是固定的,我们考虑数据的变化。在似然函数中,数据是已知的,我们考虑参数的变化。
- 目的不同: 概率密度函数用于描述数据生成模型,而似然函数用于基于观察到的数据进行参数估计。
- 数学性质: 概率密度函数需要满足概率的公理(如非负性,积分(或求和)为1),而似然函数没有这样的要求。
四、最大似然估计(Maximum Likelihood Estimation, MLE)
最大似然估计是一种常用的参数估计方法,它通过最大化似然函数来找到最“合适”的参数值。在这一节中,我们将详细讲解最大似然估计的基础理论、应用场景,并通过具体的例子与代码演示进行解释。
定义与基本思想

例子与代码:估计正态分布的参数

Python代码实现
下面是使用Python和PyTorch来实现最大似然估计的代码。
import torch
import torch.optim as optim
# 随机生成一些正态分布的数据样本(均值为5,标准差为2)
data = torch.normal(5, 2, size=(100,))
# 初始化参数
mu = torch.tensor(1.0, requires_grad=True)
sigma = torch.tensor(1.0, requires_grad=True)
# 优化器
optimizer = optim.SGD([mu, sigma], lr=0.01)
# 迭代次数
n_iter = 5000
# 开始优化
for i in range(n_iter):
optimizer.zero_grad()
# 计算负对数似然
n = len(data)
neg_log_likelihood = 0.5 * n * torch.log(2 * torch.tensor(3.14159)) + n * torch.log(sigma) + torch.sum((data - mu)**2) / (2 * sigma**2)
# 反向传播
neg_log_likelihood.backward()
# 更新参数
optimizer.step()
# 输出结果
print(f"Estimated mu: {mu.data}")
print(f"Estimated sigma: {sigma.data}")
输入与输出
- 输入:一个来自正态分布的数据样本(
data)。 - 输出:估计得到的均值(
mu)和标准差(sigma)。
处理过程
- 初始化均值和标准差的参数。
- 使用梯度下降法来最小化负对数似然函数。
通过以上的定义、例子和代码,最大似然估计在参数估计中的重要性和实用性得以充分展示。在接下来的部分,我们将继续深入探讨如何使用似然函数进行更复杂的模型选择和评估。
五、似然函数在机器学习中的应用
似然函数不仅在统计推断中有重要应用,也在机器学习,尤其是在监督学习、非监督学习以及模型选择等方面有广泛的使用。本节将深入探讨似然函数在机器学习各领域中的应用,并提供相关的代码示例。
监督学习:逻辑回归
定义
在监督学习中,特别是用于分类问题的逻辑回归模型,最大似然估计用于优化模型的参数。逻辑回归模型试图找到一个函数,使得给定输入特征下某一类别出现的“可能性”最大。
例子与代码:逻辑回归模型

以下是用PyTorch实现逻辑回归模型的代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 创建一些简单的数据
x_data = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y_data = torch.tensor([[0], [0], [1], [1]], dtype=torch.float32)
# 定义模型
class LogisticRegressionModel(nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
# 损失和优化器
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(1000):
model.train()
optimizer.zero_grad()
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
loss.backward()
optimizer.step()
# 输出训练后的参数
print("Weight:", model.linear.weight.item())
print("Bias:", model.linear.bias.item())
输入与输出
- 输入:特征 (x) 和标签 (y)。
- 输出:逻辑回归模型的参数。
处理过程
- 初始化模型和优化器。
- 使用二元交叉熵损失函数(对应于逻辑回归的负对数似然函数)。
- 通过梯度下降来更新模型的参数。
六、总结
在本篇博客中,我们从似然函数的基础概念出发,深入探讨了它在统计推断和机器学习中的多方面应用。无论是在参数估计的最大似然估计法,还是在逻辑回归和高斯混合模型中,似然函数都发挥着至关重要的作用。通过最大化似然函数,我们不仅能找到描述数据的“最合适”的模型参数,而且还可以更深入地理解模型的性质和限制。
- 似然函数与梯度下降:在机器学习中,尤其是深度学习领域,梯度下降是最常用的优化算法。然而,不同的损失函数(即负对数似然函数)可能导致不同的优化性能和模型泛化能力。理解似然函数如何与梯度下降算法交互,有助于我们更有效地训练模型。
- 模型选择与复杂度:在现实应用中,选择一个“最佳”模型通常涉及到复杂度与准确性之间的权衡。通过似然函数,我们可以更直观地评估模型复杂度与数据拟合度之间的关系,从而进行更合理的模型选择。
- 似然函数与不确定性:在现实世界的很多问题中,数据往往具有噪声和不确定性。似然函数为我们提供了一种量化不确定性的方式,进一步,我们甚至可以通过贝叶斯方法,将先验信息与似然函数相结合,以更全面地理解数据和模型。
- 似然函数与生成模型:在非监督学习和生成模型(如GANs)中,似然函数的概念有时会被重新定义或拓展,以适应更复杂或高维的数据结构。理解这些扩展或变种的数学基础,可以为研究和应用这些先进模型提供有力的支撑。
合理的模型选择。
3. 似然函数与不确定性:在现实世界的很多问题中,数据往往具有噪声和不确定性。似然函数为我们提供了一种量化不确定性的方式,进一步,我们甚至可以通过贝叶斯方法,将先验信息与似然函数相结合,以更全面地理解数据和模型。
4. 似然函数与生成模型:在非监督学习和生成模型(如GANs)中,似然函数的概念有时会被重新定义或拓展,以适应更复杂或高维的数据结构。理解这些扩展或变种的数学基础,可以为研究和应用这些先进模型提供有力的支撑。
通过深入探讨似然函数和最大似然估计,本文旨在为读者提供一个全面而深入的理解,帮助大家更有效地应用这一概念于各种实际问题中。感兴趣的可以多去学习概率论与数理统计提升自己数据分析能力,加强数据建模能力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 编程笔记 html5&css&js 035 HTML 地理定位
- 用户管理第2节课--idea 2023.2 后端--实现基本数据库操作(操作user表) -- 自动生成
- Python急速入门——(第六章:字典)
- [GWCTF 2019]我有一个数据库1
- 贪心算法详解
- 面向对象程序设计(Python实现)
- 文件包含技术总结
- AcWing 5386. 进水出水问题【线性dp+差值dp】
- 【华为OD机试真题2023C&D卷 JAVA&JS】贪心歌手
- Spring Security:强大且灵活的Java安全框架