深度强化学习的变道策略:Harmonious Lane Changing via Deep Reinforcement Learning
偏理论,假设情况不易发生
摘要
多智能体强化学习的换道策略,不同的智能体在每一轮学习后交换策略,达到零和博弈。
和谐驾驶仅依赖于单个车辆有限的感知结果来平衡整体和个体效率,奖励机制结合个人效率和整体效率的和谐。
Ⅰ. 简介
自动驾驶不能过分要求速度性能,
考虑单个车辆的厌恶和所在路段的整体交通效率的奖励函数,适当的混合以提高整体的交通效率。
章节安排:
-
简介
-
和谐变道的深度强化学习模型
-
模拟器设计
-
实验设置和所提出的策略在训练和测试中的仿真结果
-
模型的一些有趣问题
-
总结
Ⅱ. 协调换道的深度强化学习模型
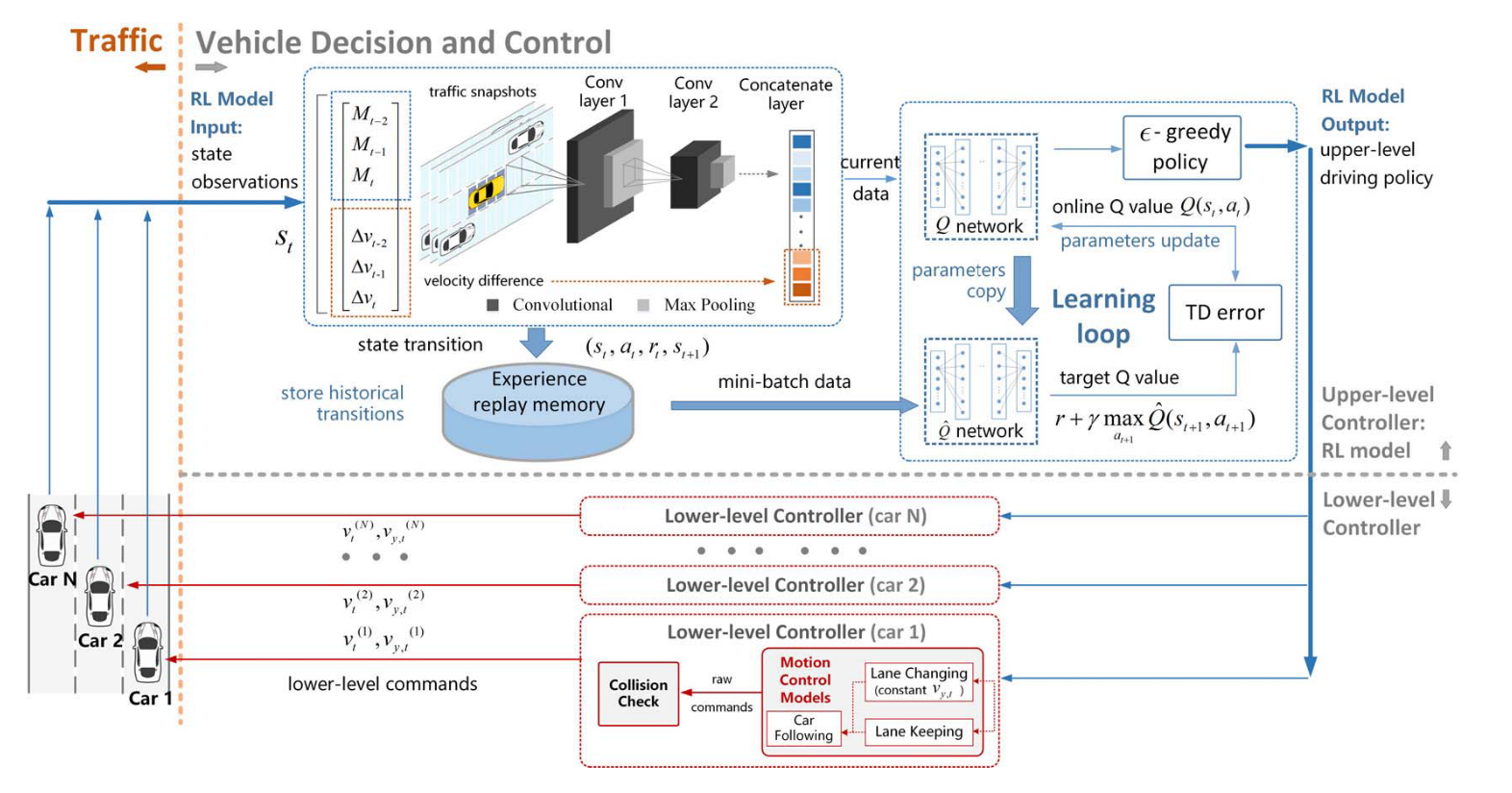
A. 问题呈现和DRL模型
1)状态空间:
每个车辆的状态由:三个连续帧的交通快照和实际速度与预期速度之间的相应速度差组成。
拍摄交通快照来研究车辆周围的情况。
M t ( i ) M_t^{(i)} Mt(i)?用二维矩阵表示车辆周围的占有网格(存在车辆的网格为1,空网格为0)
S被输入到DQN。
2)动作空间:
a
t
(
i
)
a_t^{(i)}
at(i)?为车辆i的动作,包括改变到左/右道路和保持当前车道。
减速不在当前中,设置了单独的碰撞检查过程修改速度。
3)奖励函数:
r t ( i ) r_t^{(i)} rt(i)?车辆行驶效率,与其他车辆的协调性和总体交通流率之间的权衡。
r v ( i ) r_v^{(i)} rv(i)?是车辆个体形式效率的奖励, r c l ( i ) r_{cl}^{(i)} rcl(i)?是变道的惩罚, r q r_q rq?是交通流率的奖励。
α {\alpha} α是换道行为的协调系数。
频繁变道会使得交通流率下降,对于每个换道行为我们从奖励中减去 α {\alpha} α来作为惩罚。
大 α {\alpha} α使得车辆学习一个温和的变道策略,限制不必要的变道。
q t {q_t} qt?是所研究车辆周围的流量
R s c a l e R_{scale} Rscale?是一个缩放系数保持 r q r_q rq?的幅度和 r v ( i ) r_v^{(i)} rv(i)?和 r c l ( i ) r_{cl}^{(i)} rcl(i)?的一致性。
B. 深度强化学习算法
DQN学习有效的变道决策机制,输入 s t ( i ) s_t^{(i)} st(i)?到DQN,输出 a t ( i ) a_t^{(i)} at(i)?。
代理的经验存储在数据集 D t {D_t} Dt?
在学习模型时,从Dt中均匀抽取样本以计算以下损失函数(TD误差),随机梯度下降更新参数
基于DQN Q值的贪婪策略选择并执行策略。
每个仿真车辆共享一个共同的RL模型作为上层决策者,并为自己维护一个低层运动控制器。
变道决策DQN
快照进入两层CNN,然后通过级联层与速度差级联。
将数据送入两层全连接Q网络,得到a作为高级驾驶策略
送到低级控制器,用于每个车辆的低级运动命令
更深层的深度强化学习没有获得更好的效果
Ⅲ. 仿真平台
平台流水线概括为以下:
- 根据上游流入率在道路起点生成新车辆。
- 从所提出的换道模型中获取环境数据并得到驾驶决策。
- 计算每辆车的适当速度,并执行驾驶决策。
- 在每次迭代中,纵向速度和横向速度,t将分别由车辆跟随模型和车道变换模型计算。
- 执行碰撞检查过程并更新所有车辆的位置。
- 在步骤4)中将执行碰撞检查过程,以修改纵向速度以确保安全。
问题
多智能体每轮学习后交换策略。
个人效率和整体效率的和谐。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python小细节之代码极致简化到一行(5)(列表推导式)(技法慎用)
- [学习笔记]刘知远团队大模型技术与交叉应用-汇总
- jupyter notebook介绍、安装和使用
- 极智项目 | 实战Mxnet戴口罩检测
- 肖恩会函数递归咯!
- ElasticSearch深度分页解决方案
- 消息队列的作用与使用场景?
- 【Java面试题】JDK 8 及以后版本的新特性
- Polyverse Skies | Low Poly Skybox Shaders
- 代码随想录 Leetcode541. 反转字符串 II