SQL查询优化
一、查询优化
1.exists 和in的选择
永远小表驱动大表

优化原则:小表驱动大表,即小的数据集驱动大的数据集。

注意:
当B表的数据集必须小于A表的数据集时,用in优于exists
当A表的数据集必须小于B表的数据集时,用exists优于in
2.ORDER BY关键字优化
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序
建表SQL
create table tbla( id int primary key auto_increment , age int, birth TIMESTAMP ) ? insert into tbla(age,birth)values(22,NOW()); insert into tbla(age,birth)values(23,NOW()); ? insert into tbla(age,birth)values(24,NOW()); ? create index index_agebirth on tbla(age,birth)
第一类:
第一种情况:
explain select * from tbla order by age

第二种情况:
explain select * from tbla where age>20 order by age
![]()
第三种情况:
explain select * from tbla where age>20 order by age,birth

第四种情况:
explain select * from tbla where age>20 order by birth

第五种情况:
explain select * from tbla where age>20 order by birth,age

MySQL支持两种方式的排序
FileSort和Index,Index效率高。FileSort方式效率较低。
Using Index,它指MySQL扫描索引本身完成排序。
ORDER BY满足两种情况,会使用Index方式排序:
ORDER BY语句使用索引最左前缀
尽可能在索引列上完成排序操作,遵照索引建的最佳最前缀 如果不在索引列上,filesort有两种算法:
mysql就要启动双路排序和单路排序
双路排序
MySQL4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据。
从磁盘取排序字段和主键,在buffer进行排序,再从磁盘读取其他字段。 取一批数据,要对磁盘进行了两次扫描,众所周知,IO是很耗时的
age id
10 1
8 2
3 3
7 4
age id
3 3
7 4
8 2
10 1
select * from A where name = '自由的辣条' order by age
MySQL 4.1 之前使用的双路排序,通过两次扫描磁盘得到数据。读取主键id 和 order by 列并对其进行排序,扫描排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。
1 3 自由的辣条
2 6 自由的辣条
从索引 name 找到第一个满足 name = ‘自由的辣条’ 的主键id 根据主键 id 取出整行,把排序字段 age 和主键 id 这两个字段放到 sort buffer(排序缓存) 中 从索引 name 取下一个满足 name = ‘自由的辣条’ 记录的主键 id 重复 3、4 直到不满足 name = ‘自由的辣条’ 对 sort_buffer 中的字段 age 和主键 id 按照字段 age进行排序 遍历排序好的 id 和字段 age ,按照 id 的值回到原表中取出 所有字段的值返回给客户端
单路排序
从磁盘读取查询需要的所有列,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。但是它会使用更多的空间。 结论及引申出的问题 由于单路是后出的,总体而言好过双路 但是用单路有问题

本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。(原因:数据的总大小超过sort_buffer的容量)
单路排序过程:
从索引name找到第一个满足 name = ‘自由的辣条’ 条件的主键 id 根据主键 id 取出整行,取出所有字段的值,存入 sort_buffer(排序缓存)中 从索引name找到下一个满足 name = ‘自由的辣条’ 条件的主键 id 重复步骤 2、3 直到不满足 name = ‘自由的辣条’ 对 sort_buffer 中的数据按照字段 age 进行排序 返回结果给客户端
优化策略
增大sort_buffer_size参数的设置
增大max_length_for_sort_data参数的设置:MySQL根据max_length_for_sort_data变量来确定使用哪种算法,默认值是1024字节,如果需要返回的列的总长度大于max_length_for_sort_data,使用第一种算法,否则使用第二种算法
Why:提高排序速度
show VARIABLES like 'sort_buffer_size'

3.GROUP BY关键字优化
group by实质是先排序后进行分组,遵照索引建的最佳左前缀。 当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置。
where高于having,能写在where限定的条件就不要去having限定了。
select * from A where ....... group by having
二、慢查询日志
1.是什么
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阈值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
long_query_time的默认值是10,意思是运行10秒以上的语句。
show VARIABLES like 'long_query_time'
由它来查看哪些SQL超出了我们的最大忍耐时间值,比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合之前的explain进行全面分析。
2.怎么玩
默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。
当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件。
默认:SHOW VARIABLES LIKE ‘%slow_query_log%’;

开启:set global slow_query_log=1;
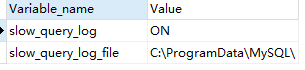


那么开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢
设置慢的阈值时间:set global long_query_time=3;
为什么设置后看不出变化(设置3之后,查询依然显示10):
SHOW VARIABLES LIKE '%long_query_time%';

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何用python 批量修改文件夹中文件的名字
- python venv 虚拟环境创建激活和pip包管理和 包版本依赖文件 requirements.txt 使用指南
- FormData文件上传多文件上传
- 实现LCM在docker之间的通信
- Zoho SalesIQ:提高品牌在社交媒体上参与度的实用指南
- python趣味编程-首字母缩略词生成器
- 电机控制::频率问题
- NFTScan | 01.01~01.07 NFT 市场热点汇总
- 学习笔记——C++运算符之赋值运算符
- 使用Python实现深度学习模型通常涉及以下几个步骤: