Megatron模型并行研究
Megatron模型并行研究
1. 技术调研
a. Megatron-LM
Megatron-LM针对的是特别大的语言模型,使用的是模型并行的训练方式。但和普通的模型并行不同,他采用的其实是张量并行的形式,具体来说就是将一个层切开放到不同的GPU上,属于层切的方法,是一种层内的模型并行。
除了张量并行外,Megatron-LM也提供了流水线并行的模型训练形式。流水线并行水平划分模型,按照层对模型进行划分,将大模型划分为一个个子模型,不同的流水线并行组负责不同的小模型,是一种层并行方式。
b. 模型简介:GPT2-345m
GPT2是一种非常强大的自然语言处理模型,广泛应用于各种自然语言处理任务中。其参数规模非常大,这使得它能够处理更复杂的任务和生成更自然的文本。不同版本的GPT之间的差异在于参数数量和性能,具体如下表所示。考虑到现有的实验环境带来的限制,为了使得测试实验能够顺利进行,我们在Megatron-LM单机并行实验中采用参数量较小的GPT2-345m模型进行预训练。

c. 数据集简介:oscar
与用于有监督精调的数据格式不同,用于预训练的oscar数据并不以问答对的形式出现。oscar的原始文本数据以JSONL格式(每行一个JSON对象)存储,每个JSON对象包含了一个“id”字段和一个“text”字段。其中“id”字段存储一个样本编号,“text”字段存储一段文本,如下表所示。

2. Megatron-LM单机双卡的模型并行预训练实验
该实验基于gpt2的预训练进行的,使用的虚拟环境为peft,共跑通了两组模型并行实验,分别为张量并行实验和流水线并行实验,其模型并行度的设置如下:
Tensor并行:--tensor-model-parallel-size 2 \
?????????????????????--pipeline-model-parallel-size 1 \
Pipeline并行:--tensor-model-parallel-size 1 \
????????????????????????--pipeline-model-parallel-size 2 \
a. 如何运行脚本文件
ⅰ. checkpoints文件的下载
输入以下命令即可下载:wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip。 然后将该文件存储并解压在checkpoints文件夹中,但我在实验中并未用到该文件,因为该文件对应的是单机单卡预训练模型生成的checkpoint文件,与本实验中的模型并行度不匹配,因此不可用。此外,由于该文件夹太大,因此git并未对该文件夹进行track,也没有push到仓库中去,需要用时需下载。
ⅱ. 数据预处理
下列代码中主要是下载了预训练所需要的数据,所有相关数据都存储在data文件夹中。此处参考了CSDN上的教程:Megatron-Deepspeed 预训练 GPT-小白踩坑与解决-CSDN博客,该教程使用了OSCAR数据集作为预训练的原始数据。 数据下载完毕后,使用preprocess_data.py进行数据预处理。在终端输入如下命令,其中output-prefix是数据预处理生成文件的前缀,在本文的例子中,数据预处理后生成的文件被命名为my-gpt2_text_document.bin和my-gpt2_text_document.idx。
wget https://huggingface.co/bigscience/misc-test-data/resolve/main/stas/oscar-1GB.jsonl.xz
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt
xz -d oscar-1GB.jsonl.xz
python tools/preprocess_data.py \
--input oscar-1GB.jsonl \
--output-prefix my-gpt2 \
--vocab-file gpt2-vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file gpt2-merges.txt \
--append-eod \
需要注意的是,由于此外,由于data文件夹太大,因此git并未对该文件夹进行track,也没有push到仓库中去,需要用时需下载。
ⅲ. 修改pretrain_gpt_distributed_with_mp.sh
要对gpt2进行预训练只需对pretrain_gpt_distributed_with_mp.sh进行修改,该文件位于/home/Megatron-LM-main/目录下。 需要修改GPUS_PER_NODE=2,NNODES=1,表示使用一台服务器,两张卡。 需要修改以下内容。其中CHECKPOINT_PATH中并没有gpt2_2,因此模型将不从任何先前保存的检查点(checkpoint)开始,而是从随机初始化的参数开始训练。此外,目前单机双卡的checkpoint文件重载没问题,双机四卡的checkpoint重载有问题,因此尽量从头开始训练。要注意DATA_PATH不包含之前数据预处理生成的文件my-gpt2_text_document.bin和my-gpt2_text_document.idx的后缀。
CHECKPOINT_PATH=checkpoints/gpt2_2
VOCAB_FILE=data/gpt2-vocab.json
MERGE_FILE=data/gpt2-merges.txt
DATA_PATH=data/my-gpt2_text_document还需要修改tensor模型并行和pipeline模型并行的相关参数,在实验中我们并未启用数据并行,因此只需要确保WORLD_SIZE=tensor-model-parallel-size * pipeline-model-parallel-size。
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 1 \
ⅳ. 直接在终端运行./pretrain_gpt_distributed_with_mp.sh即可。
b. 环境安装的相关问题
ⅰ. apex安装
首先不能直接pip下载,否则会下载一个同名包apex,那并不是Megatron-LM框架需要的;
行不通:从https://github.com/NVIDIA/apex下载压缩包.zip,再进行解压安装;
该压缩包代码和github上的最新版本有出入,查看了setup.py文件才知道,压缩包代码内根本没有关于构建fused_weight_gradient_mlp_cuda模块的部分,因此后续会报错。
正确:git clone https://github.com/NVIDIA/apex;
git clone下载NVIDIA/apex可能会有超时问题,可以通过以下命令解决超时问题;
git clone超时:git config --global url."https://github.com".insteadOf git://github.com
再执行一次git clone
然后cd apex
关键:这个包的最新版本有很多问题,比如安装时报错缺少模块packaging、torch,此时这些模块需要重新使用conda命令安装,但我们没必要这么做,只需要回退到旧版本;
git checkout 6943fd26e04c59327de32592cf5af68be8f5c44e,这个版本是在issue里面找到的,没有问题可以放心使用。
关键:pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./这其中的一些选项其实是对将要要构建模块的一些选择。如果像网上那样用些python3 setup.py之类的命令来安装包,构建出来的模块会少很多,运行代码时各种报错:比如amp_C模块的缺失。因此对于这种比较麻烦的包安装前需要查看README.md文件。

ⅱ. GPU架构问题:报错nvcc fatal: Unsupported gpu architecture ‘compute_90‘
在Megatron-LM/megatron/fused_kernels/__init__.py,注释掉以下三行即可:
# if int(bare_metal_minor) >= 7:
# cc_flag.append('-gencode')
# cc_flag.append('arch=compute_90,code=sm_90')
c. 实验结果

d. 实验结论
从上表我们可以得出如下结论:
- 张量并行的训练方式更加节省GPU显存的用量;
- 流水线并行相较于张量并行,其通信开销要更小,因此在单节点中,每秒钟处理的样本数更多,处理样本的效率更高。
3. Megatron-LM双机四卡的模型并行预训练实验
是以A服务器为主节点,B服务器为副节点,基于gpt2的预训练进行的,使用的虚拟环境为peft,张量并行度和流水线并行度设置如下:
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 2 \
a. 如何运行脚本文件
多机并行是在单机并行的基础上进行的,因此要运行多机并行的脚本文件,请先参考Megatron-LM模型并行研究的第2小节中的a,完成其中的操作,再配置接下来的部分。
ⅰ. NCCL环境变量的配置
多机并行需要在运行脚本.bash文件中加上下列NCCL相关环境变量的配置。与DeepSpeed实验中的的相关配置类似:
export CUDA_DEVICE_MAX_CONNECTIONS=1
export CUDA_DEVICE_ORDER="PCI_BUS_ID"
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=eth1,eno2
ⅱ. 在运行脚本.bash文件中修改变量
主节点地址:MASTER_ADDR="ip";
节点数(包含A和B两个节点):NNODES=2;
两个节点中运行脚本的唯一不同:A服务器作为主节点的NODE_RANK=0,83服务器作为副节点的NODE_RANK=1。
检查点的存储地址被命名为CHECKPOINT_PATH=checkpoints/gpt2_tp_2_pp_2,表示以张量并行度为2,流水线并行度为2对gpt2模型进行预训练。
ⅲ. 为验证主节点和副节点是否都参与了模型的预训练,设置 --save-interval 1000 \,观察checkpoint的保存情况。
ⅳ. 打开防火墙端口以便双机通信,在终端输入以下命令:
sudo firewall-cmd --zone=public --add-port=33000-65000/tcp --permanent
sudo firewall-cmd --reload
ⅴ. 为保证服务器安全,实验结束后需要关闭端口,在终端输入以下命令:
sudo firewall-cmd --zone=public --remove-port=33000-65000/tcp --permanent
sudo firewall-cmd --reload
b. 模型并行图示
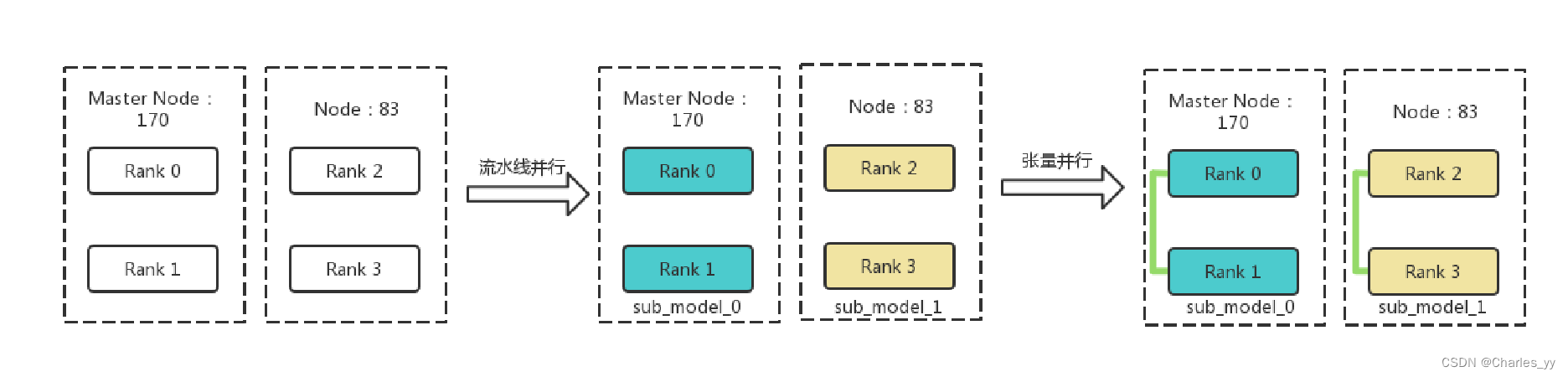
实验过程中共有两个节点参与实验,分别为A和B,其中A为主节点,每个节点有2个GPU,共计4个GPU。4个GPU的编号分别为Rank0、Rank1、Rank2、Rank3。在实验中设置流水线并行度为2,张量并行度为2。流水线并行会将整个模型划分为2份,这里称为sub_model_0和sub_model_1。每连续的2张GPU负责一个sub_model。即上图中,相同颜色的GPU负责相同的sub_model。张量并行会针对流水线并行中的sub_model来进行张量的拆分。即Rank0负责一半sub_model_0,Rank1负责另一半sub_model_0;Rank2负责一半sub_model_1,Rank3负责另一半sub_model_1。上图中,绿色线条表示两个GPU都共同负责某个具体的sub_model。
c. 实验结果
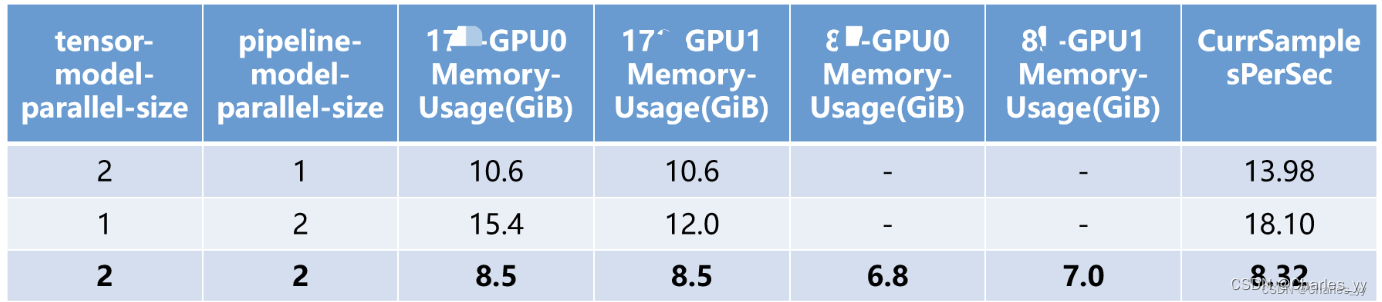
d. 实验结论
增加模型的并行度能更加节省GPU显存的用量;但由于模型并行度的提高会增加通信开销,降低计算效率,因此处理样本的效率大大下降了;在模型能加载到GPU进行训练时,尽量减少模型并行的GPU数量,而应该利用数据并行,增加batch size,提高训练效率。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 软件测试/测试开发丨Pytest结合数据驱动
- 在React和Vue中实现锚点定位功能
- 案例分享:当前高端低延迟视频类产品方案分享(内窥镜、记录仪、车载记录仪、车载环拼、车载后视镜等产品)
- 超级菜鸟怎么学习数据分析?
- I.MX6ULL_Linux_驱动篇(51)linux 音频驱动
- 多国管理中心多语言区块链源码一元夺宝程序仿趣步奕跑/原生计步器/原生人脸识别
- 判断数据是否为整数--函数设计与实现
- R语言VRPM包绘制多种模型的彩色列线图
- 动态面板简介以及ERP原型图案列
- 举个栗子!Tableau 技巧(262):制作渐变色梯度面积图