TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
卷积神经网络 CNN(Convolutional Neural Networks,ConvNet)是一种特殊的深度学习神经网络,近年来在物体识别、图像重绘、视频分析等多个层面得到了广泛的应用。
本文将以VGG16预训练模型为例子,从人脸识别、预训练模型、图片风格迁移、滤波分析、热力图等多过领域介绍 CNN 的应用。
一、卷积神经网络的原理
卷积神经网络 CNN 是由多个块组成,每个块都具有两种层:卷积层 Conv 和池化层 Pooling,卷积层 Conv 通过卷积核(也称滤波器)进行卷积运算后,由激活函数输出到池化层,再通过池化运算,如此迭代多次后,由最后的一个块通过输出层全连接进行数据输出,完成卷积神经网络的整个过程(如下图)。
可能听起来可能有点复杂,其实可以把 “卷积层 ——> 激活层 ——> 池化层” 作为一个重复块看待,经过多层重复后再由全连接输出,下面将从卷积层和池化层两个方面分别介绍 CNN 流程。
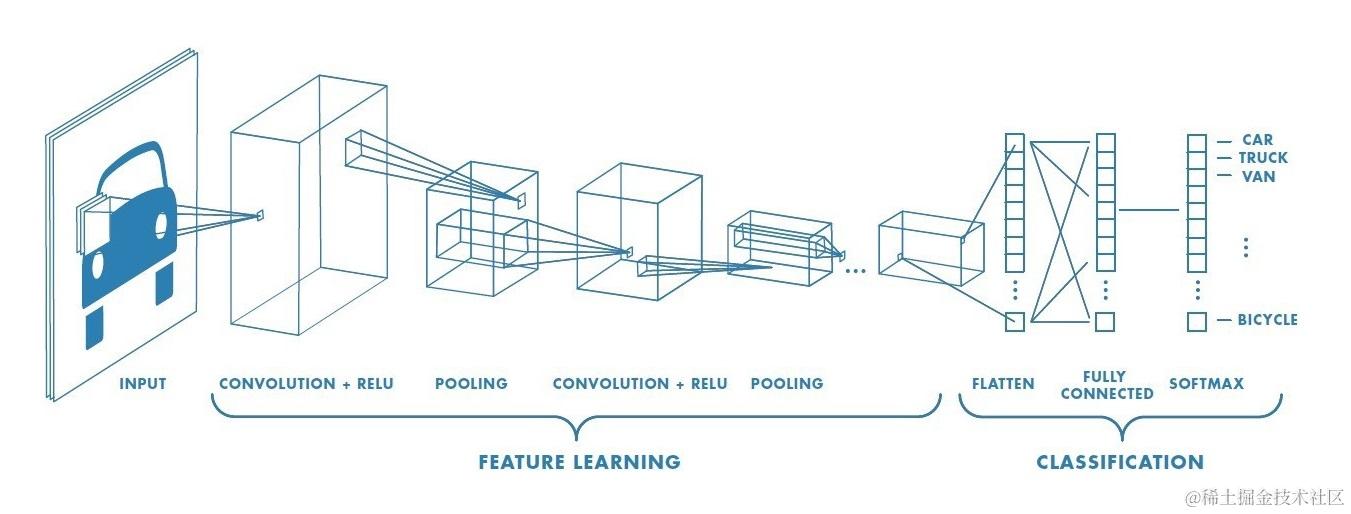
1.1 卷积层
1.1.1 滤波器(卷积核)
假设在卷积层中,有一个 166 的图形作为输入数据,这里把它称为输入特征图,它经过一个 33 的滤波器(也被称为卷积核)进行卷积运算,即从 input 左上角 33 的受野区开始计算其张量积,每完成一次计算向右移动,步幅为1,完成此计算后,就会得出一个 144 的输出特征图(如下图)。
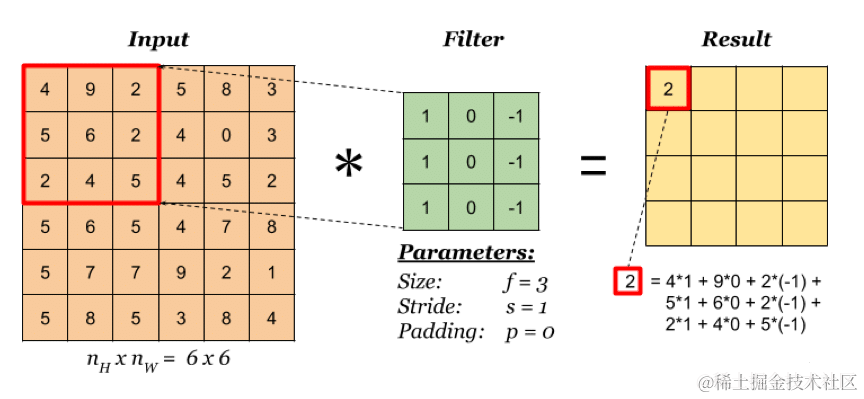
卷积核的形状必须大于等于 2 * 2 ,一般为 33 或者 55,其步幅可以自定义,一般为 1。如果卷积核步幅为 3,那么一个输入特征图为166经过步幅为3的33卷积核后,输出特征图就会变为 12*2, 如此类推。

1.1.2 偏置值
正如正常等式 f(x)=w*x+h 一样,卷积运算也有偏置值,偏置值的运算就是为每个值都加上此张量,如果下图

1.1.3 填充
经过卷积核运算后,输出特征图会比输入特征图维度少2,也就是一个133 的输入特征图与一个步幅为1的33卷积核运算后,会得出一个 111 的输出特征图。然而,这时候如果需要得出一个133 的输出特征图,只需要把 padding?参数设置为?same,系统就会自动把输入称征图变形状为 15*5,用 0 来填充再进行运行。
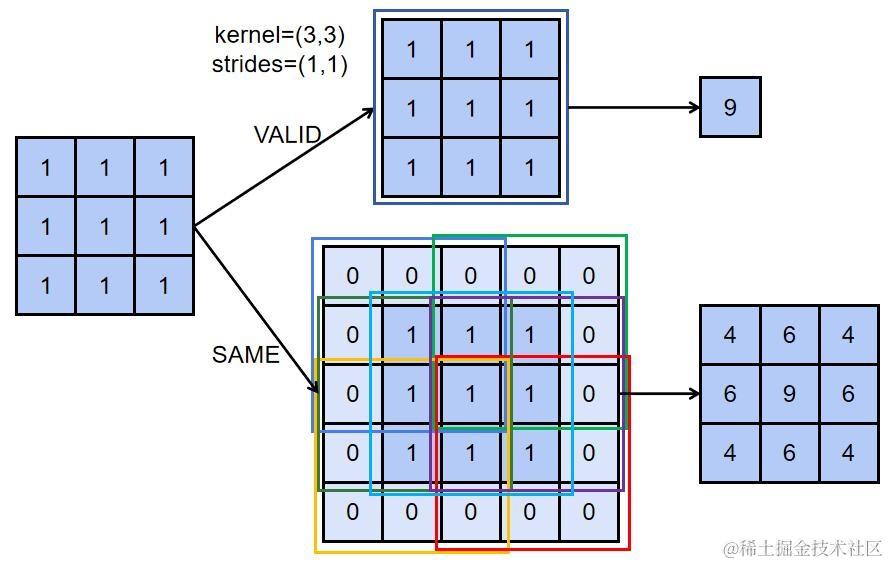
1.1.4 三维数据卷积运算
上图所介绍的都是二维数据的卷积运算,如果遇到图像处理时,例如 RGB 图片,往往还需要处理一个数据就是通道 channel,一般 RGB?图片的 channel 数为 3(红、绿、蓝),而 monochrome 图片的 channel 数为 1,根据格式不同略有差别。因此卷积核有三维数据的运算,当输入特征图为三维数据时,其卷积核也会变为三维,并将每个维度的结果相加得出输出特征输出图。
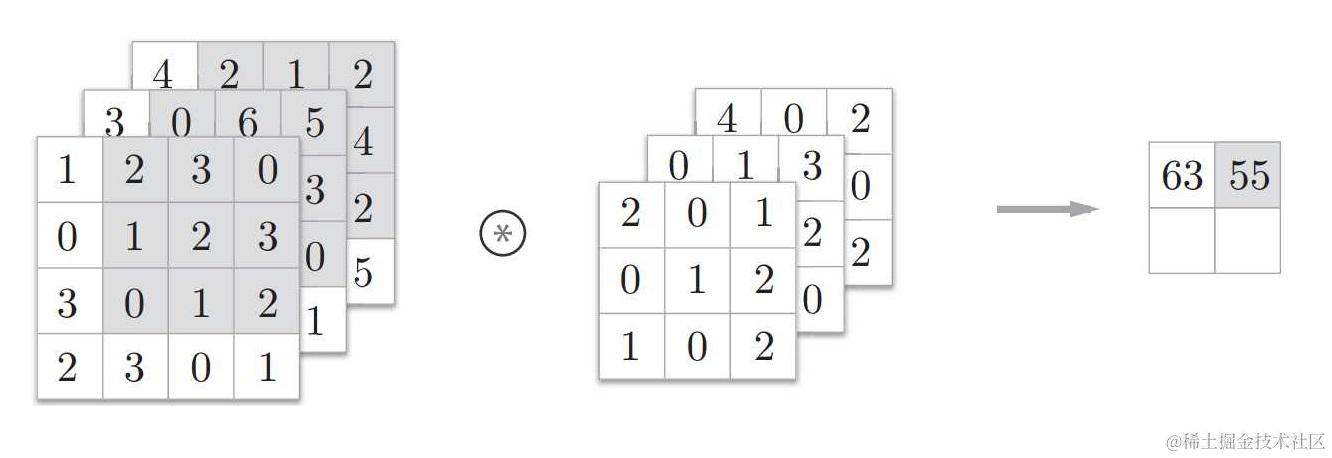
我们可以把这个三维的输入特征图看成是一幅 n 个 channel 的图片输入操作,如果图片为 n 个 channel 大小为 widthheight 的输入特征图,卷积核的形状是 n33,最后输出特征图将是 1owitdh * oheight 。

此时,若用到 w 个卷积核,然后再加入 w 个偏置值,那 n 个 channel 大小为 height * width 的输入特征图将会输出 w 层大小为 oheight * owidth 的输出特征图

1.1.5 TensorFlow 中的 卷积类 ConvNet
在 TensorFlow 1.x 中需要添加一个卷积层,可使用 tf.nn.conv2d 函数
1 def conv2d_v2(input, filters, strides, padding,
2 data_format="NHWC", dilations=None,
3 name=None):
- input:? 类型为?
float32,float64,int32,uint8,int16,int8,int64,bfloat16,uint16,half,uint32,uint64其中一种的张量,形状为?[batch, in_height, in_width, depth],代表输入的批量数据 - filters:?类型为 float32、float64、halt 的张量,输入类型与 input 相同,代表卷积核格式,例如 [1,3,3,1]
- strides:int 类型列表,长度为4,用于控制卷积核的移动步幅,与上述参数相同,也是四维的,[1,1,1,1],其中第一个1和最后一个1是固定值,中间的两个数代表在x轴和y轴的移动步长。
- padding:str 类型 [ SAME’,‘VALID’] 之一,用于选择填充的算法,SAME 是填充边界,VALID 是当不足以移动时直接舍弃。
- data_formate:str类型 [‘NHWC’、‘NCHW’ ] 之一,默认值为 NHWC,指定输入和输出数据的格式。NHWC 时数据格式为 [batch, in_height, in_width, in_channels],NCHW时数据格式为 [batch,in_channels,in_heihgt,in_width]
- dilations:int类型列表,格式必须为 [1, rate_height, rate_width, 1],指定填充边界时的步幅。当边界无需填充时,其默认值为 None,当需要填充边界时,其默认值为 [1,1,1,1]
- name: str 类型,名称
在 TensorFlow 2.x 中可以直接使用 Conv2D 类,其常用参数与 TensorFlow 1.x 类似,注意数据输入格式略有不同。
1 class Conv2D(Conv):
2 def __init__(self,filters,kernel_size,strides=(1, 1),padding='valid',
3 data_format=None,dilation_rate=(1, 1),groups=1,activation=None,
4 use_bias=True,kernel_initializer='glorot_uniform',bias_initializer='zeros',
5 kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None,
6 kernel_constraint=None, bias_constraint=None,
7 **kwargs):
- filters:int 类型,代表卷积核的数量
- kernel_size:int 类型列表,形状 [int,int],代表卷积核的形状
- strides:int 类型列表,默认值为 (1 , 1 ) 与 tf.nn.conv2d 不同,其形状为 [int , int ] 二维数组,用于控制卷积核的移动步幅。
- padding:“valid” 或 “same” (大小写敏感),用于选择填充的算法,same 是填充边界,valid 是当不足以移动时直接舍弃。
- data_formate:str类型 [ channels_last , channels_first ] 之一,默认值为 channels_last,指定输入和输出数据的格式。channels_first?时数据格式为 [batch, channels, height, width],channels_last 时数据格式为 [batch,heihgt,width, in_channels]
- dilations:int类型列表,格式必须为 [ rate_height, rate_width ],默认值为 [1 , 1 ],指定填充边界时的步幅。
- group: int 类型,默认为1,指定输入数据中,沿 channel 轴分割的组的数量
- activation: str 类型,默认为 None,要使用的激活函数。 如果你不指定,则不使用激活函数 (即线性激活: a(x) = x)。
- use_bias: bool 类型,默认为 True,指该层是否使用偏置向量。
- kernel_initializer: str 类型,默认为 glorot_uniflorm, kernel 权值矩阵的初始化器 (详见 keras.initializers)。
- bias_initializer: str 类型,默认为 zeros ,偏置向量的初始化器 (详见 keras.initializers) 。
- kernel_regularizer: str 类型,默认为 None,运用到 kernel 权值矩阵的正则化函数 (详见 keras.regularizers)。
- bias_regularizer: 运用到偏置向量的正则化函数 (详见 keras.regularizers)。
- activity_regularizer: 运用到层输出(它的激活值)的正则化函数 (详见 keras.regularizers)。
- kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见 keras.constraints)。
- bias_constraint: 运用到偏置向量的约束函数 (详见 keras.constraints)。
1.2 最大池化层
池化层分为最大池化层 MaxPool 与均值池化层 AvgPool,其实就是缩小width和height的运算,比如按步幅 2 进行 22 MaxPool,相当于在 22 的区域中获取最大值运算,取出最大的值。其池化大小往往也步幅相同,即 2 * 2 的池化步幅为2 ,3 * 3 的池化步幅为3,如此类推。

在 TensorFlow 1.x 中需要添加最大池化层,可使用 tf.nn.max_pool 函数
1 def max_pool(value, ksize, strides, padding,
2 data_format="NHWC", name=None, input=None):
- input:? 类型为?
float32的 4维张量,形状为?[batch, in_height, in_width, depth],代表输入的批量数据 - ksize:?类型为 int 的整数列表,代表池化区域的格式,例如 [1 , 2 , 2 , 1]
- strides:int 类型列表,长度为4,用于控制池化的移动步数,与上述参数相同,也是四维的,例如[1,1,1,1],其中第一个1和最后一个1是固定值,中间的两个数代表在x轴和y轴的移动步长。
- padding:str 类型 [ SAME’,‘VALID’] 之一,用于选择填充的算法,SAME 是填充边界,VALID 是当不足以移动时直接舍弃。
- data_formate:str类型 [‘NHWC’、‘NCHW’ ] 之一,默认值为 NHWC,指定输入和输出数据的格式。NHWC 时数据格式为 [batch, in_height, in_width, in_channels],NCHW时数据格式为 [batch,in_channels,in_heihgt,in_width]
- name: str 类型,名称
在 TensorFlow 2.x 中可通过 MaxPooling2D 类生成最大池化层
1 class MaxPooling2D(Pooling2D):
2 def __init__(self, pool_size=(2, 2), strides=None,
3 padding='valid', data_format=None, **kwargs):
- pool_size:int 类型的整数列表,长为2,默认为(2,2),代表池化层在两个方向(竖直,水平)采样范围。
- strides:int 类型列表,步长为2的整数列表,默认为 None,用于控制池化的移动步数。当使用 None 时,默认 与pool_size 相同。
- padding:“valid” 或 “same” (大小写敏感),用于选择填充的算法,same 是填充边界,valid 是当不足以移动时直接舍弃。
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。默认值为 channels_last,指定输入和输出数据的格式。channels_first?时数据格式为 [batch, channels, height, width],channels_last 时数据格式为 [batch,heihgt,width, channels]
1.3 卷积神经网络 CNN 的优势
对比起多层感知机,卷积神经网络有其天生的优势。由于多层感知机使用的是全转接层,因此当输入图形数据例如 RGB 图形为三维形状时,需要先对图像进行变形。例如常用的 MNIST 28281 的数字,输入前会先将其转化为 784 的数据形式。如此一来相当于把所有的神经元看作同一维度处理,这样会把原有的三维数据间所隐藏的关联标志,相距像素等重要信息丢弃。
而从上面的例子可以看到,使用卷积神经网络会以三维数据的形式接收输入数据,同时以三维的形式输出到下一层。因此使用 CNN 可以最大程度保存图形原来的特征,这也是近年来 CNN 被广泛应用于图像、视频、人脸识别等领域的原因。
二、构建第一个 CNN 对MNIST 数字进行分类
以最简单的 MNIST 数字集为例字,介绍最基础的 CNN 应用。输入 28281 MNIST 数据集,经过 32 个? 55 的卷积核,池化层形状为 22,使用ReLU输出后,数据形状变为 141432。经过64个 55 卷积核,池化层形状为 22,使用ReLU输出后数据形式变为 7764。然后通过 Flatten 把数据拉直,经过三层的全转接,使用 Adam 模型把输出数从1024、256、50下降到10,最后输出层使用 softmax 激活函数输出。
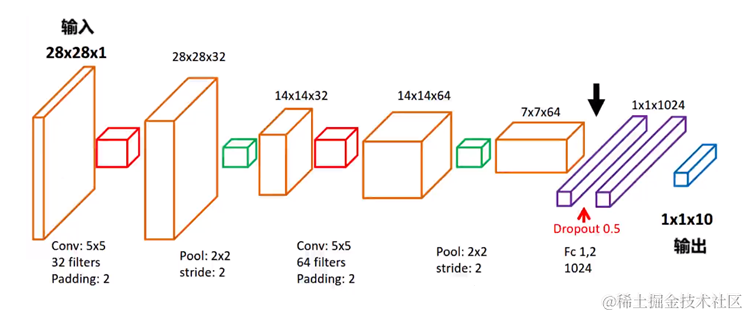
完成训练后,测试数据准确率基本保持在 96% 以上
1 def getmodel():
2 # 生成模型
3 model=models.Sequential()
4 # 32个卷积核形状为 5*5,激活函数为 relu
5 model.add(layers.Conv2D(filters=32,padding='same',kernel_size=(5,5),activation='relu'))
6 # 池化层,大小2*2
7 model.add(layers.MaxPool2D(2,2))
8 # 64个卷积核形状为 5*5,激活函数为 relu
9 model.add(layers.Conv2D(filters=64,padding='same',kernel_size=(5,5),activation='relu'))
10 # 池化层,大小2*2
11 model.add(layers.MaxPool2D(2,2))
12 # 拉直数据
13 model.add(layers.Flatten())
14 # 多层 MLP dropout 为 0.5
15 model.add(layers.Dense(1024,activation='relu'))
16 model.add(layers.Dropout(rate=0.5))
17 model.add(layers.Dense(256,activation='relu'))
18 model.add(layers.Dropout(rate=0.5))
19 model.add(layers.Dense(50,activation='relu'))
20 model.add(layers.Dropout(rate=0.5))
21 # 输出层激活函数为 softmax
22 model.add(layers.Dense(10,activation='softmax'))
23 return model
24
25 def run(X,y,model,epoch=10):
26 # 输入数据转换
27 X,_train=convert(X,y)
28 # 生成训练模型,学习率为0.003
29 model.compile(optimizer=optimizers.Adam(0.003),
30 loss=losses.sparse_categorical_crossentropy,
31 metrics=['accuracy'])
32 # 日志输出
33 callbacks= keras.callbacks.TensorBoard(log_dir='logs')
34 model.fit(X,y,batch_size=500,epochs=epoch,callbacks=callbacks)
35 return model
36
37 def convert(X,y):
38 # 数据格式转换
39 X=X.reshape(-1,28,28,1)
40 X=tf.convert_to_tensor(X,tf.float32)
41 y=tf.convert_to_tensor(y,tf.float32)
42 return X,y
43
44 if __name__=='__main__':
45 # 获取数据集
46 (X_train,y_train),(X_test,y_test)=keras.datasets.mnist.load_data()
47 # 生成模型
48 model=getmodel()
49 # 数据测试
50 run(X_train,y_train,model)
51 print('------------------------test-----------------------')
52 run(X_test,y_test,model,1)
运行结果

tensorboard 损失函数与正确率变化

三、利用 CNN 进行人脸识别
如今人脸识别是近来最为普及的应用,下面就以此为例介绍 CNN 在人面识别领域的实现方式。这个例子只是基于对 CNN 使用的介绍,实际市场上已经有多个成熟的人脸识别框架可供用户选择。
相信大家也感受到在很多手机 APP 中都有着人脸识别登录的功能,在视频录制时都会要求用户进行张口/闭眼/转头等一系列动作,其目的就是进可能地把用户各个脸面特征收纳到云端,然后利用 cv2 把视频按照帧进行分解,最后对分解的图片进行学习。
下面假设录制好的视频被放到 input 文件夹中,通过 cv2 函数即可把视频分解为 jpg 文件,图片按 50*70的大小统一放到 pic 文件夹内。
1 def read(videopath,output):
2 # 读入视频文件
3 vc=cv2.VideoCapture(videopath)
4 # 打开文件
5 isOpen=vc.isOpened()
6 n=0
7 while(isOpen):
8 # 读取数据帧
9 rval,frame=vc.read()
10 if rval:
11 img=Image.fromarray(frame)
12 # 图片剪切
13 img=img.crop((0,100,500,800))
14 # 图片保存为 50*70 大小
15 out=img.resize((50,70),Image.ANTIALIAS)
16 path=output+str(n)+'.jpg'
17 out.save(path)
18 n=n+1
19
20 else:
21 break
22 print('success')
23
24 if __name__=='__main__':
25 path='E://Python_Projects/ANN/venv'
26 read(path+'/input/1.mp4',path+'/pic/train/Leslie')
视频转化为图片后,把图片训练数据和测试数据分别放到 train 和 test 文件夹中,不同人物头像放到不同子文件夹。一般用户注册时视频录制一般不会超过 5 秒,所以转化后的图片数量有限,此时可通过 ImageDataGenerator 类得到增强数据集进行训练,通过 ImageDataGenerator 类可以从变换角度,平移等随机转换的方式来增加训练样本,从而得到更好的泛化能力。
切记使用 ImageDataGenerator 时,增强数据只适用于训练数据集,不用于测试数据集,否则将影响准确率。
1 @keras_export('keras.preprocessing.image.ImageDataGenerator')
2 class ImageDataGenerator(image.ImageDataGenerator):
3 def __init__(self, featurewise_center=False, samplewise_center=False,
4 featurewise_std_normalization=False,samplewise_std_normalization=False,
5 zca_whitening=False, zca_epsilon=1e-6,rotation_range=0,
6 width_shift_range=0., height_shift_range=0.,
7 brightness_range=None, shear_range=0.,
8 zoom_range=0.,channel_shift_range=0.,
9 fill_mode='nearest',cval=0., horizontal_flip=False,
10 vertical_flip=False, rescale=None,preprocessing_function=None,
11 data_format=None, validation_split=0.0,dtype=None):
12
13 def flow_from_directory(self, directory,target_size=(256, 256),
14 color_mode='rgb',classes=None,class_mode='categorical',
15 batch_size=32,shuffle=True, seed=None,
16 save_to_dir=None,save_prefix='', save_format='png',
17 follow_links=False, subset=None,interpolation='nearest'):
__init__构造函数参数说明
- featurewise_center:bool 类型,默认为 False ,是否使输入数据集去中心化(均值为0), 按feature执行
- samplewise_center:bool 类型,默认为 False ,是否使输入数据的每个样本均值为0
- featurewise_std_normalization:bool 类型,默认为 False ,是否输入除以数据集的标准差以完成标准化, 按feature执行
- samplewise_std_normalization:bool 类型,默认为 False ,将输入的每个样本除以其自身的标准差
- zca_whitening:bool 类型,默认为 False ,对输入数据施加 ZCA 白化
- zca_epsilon: float 类型,默认1e-6,ZCA 使用的 eposilon
- rotation_range:int 类型,默认为 0,图片旋转角度
- width_shift_rang:float 类型,默认为 0.,图片平移的比例
- height_shift_rang:? float 类型,默认为 0., 图片垂直移动的比例
- brightness_range:
- shear_range:float 类型,默认为 0.,剪切强度(逆时针方向的剪切变换角度)
- zoom_range:float 类型 或 形如 [lower,upper] 的列表,默认为 0.,随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
- channel_shift_range:浮点数,随机通道偏移的幅度
- horizontal_flip:bool 类型,默认为 False ,是否水平翻转
- fill_mode:str 类型,[‘constant’,‘nearest’,‘reflect’, ‘wrap’ ] 之一,默认为?’nearest’ ,当进行变换时超出边界的点将根据本参数给定的方法进行处理
- cval:浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充的值
- rescale:默认为None,对图片缩放处理的比例
- vertical_flip:布尔值,进行随机竖直翻转
- rescale: 重放缩因子,默认为None. 如果为None或0则不进行放缩,否则会将该数值乘到数据上(在应用其他变换之前)
- preprocessing_function: 将被应用于每个输入的函数。该函数将在图片缩放和数据提升之后运行。该函数接受一个参数,为一张图片(秩为3的numpy array),并且输出一个具有相同shape的numpy array
- data_format:字符串,“channel_first”或“channel_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channel_last”对应原本的“tf”,“channel_first”对应原本的“th”。以128x128的RGB图像为例,“channel_first”应将数据组织为(3,128,128),而“channel_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channel_last”
flow_from_directory 方法参数说明
- directory: str 类型,目标文件夹路径,对于每一个类,该文件夹都要包含一个子文件夹.子文件夹中任何JPG、PNG、BNP、PPM的图片都会被生成器使用.详情请查看此脚本
- target_size:?int 数组 [ weight,width ],图片转换的像素比例,默认为 [ 256, 256 ]
- color_mode: str 类型,颜色模式,为 [ “grayscale”,“rgb” ] 之一,默认为"rgb".代表这些图片是否会被转换为单通道或三通道的图片.
- classes: str 类型 可选参数,为子文件夹的列表,如[‘dogs’,‘cats’]默认为None. 若未提供,则该类别列表将从directory下的子文件夹名称/结构自动推断。每一个子文件夹都会被认为是一个新的类。(类别的顺序将按照字母表顺序映射到标签值)。通过属性class_indices可获得文件夹名与类的序号的对应字典。
- class_mode: str 类型 [ “categorical”, “binary”, “sparse”,None] 之一. 默认为"categorical. 该参数决定了返回的标签数组的形式, "categorical"会返回2D的one-hot编码标签,"binary"返回1D的二值标签."sparse"返回1D的整数标签,如果为None则不返回任何标签, 生成器将仅仅生成batch数据, 这种情况在使用model.predict_generator()和model.evaluate_generator()等函数时会用到.
- batch_size: int 类型,batch数据的大小,默认32
- shuffle: bool 类型,是否打乱数据,默认为True
- seed: 可选参数,打乱数据和进行变换时的随机数种子
- save_to_dir: None或 str,该参数能让你将提升后的图片保存起来,用以可视化
- save_prefix:str,保存提升后图片时使用的前缀, 仅当设置了save_to_dir时生效
- save_format:“png"或"jpeg"之一,指定保存图片的数据格式,默认"jpeg”
- flollow_links: bool 类型,是否访问子文件夹中的软链
建立 model 卷积核形状为 5 *5,数量由 32 个转化为 64 个转化为 128 个。使用 Adam 优化器,由于是图片数据损失函数使用 binary_crossentropy。通过 Flatten 拉直数据后,通过五层 MLP 使用 sigmoid激活函数输出,dropout 为 50%。
通过训练后,测试数据的准确率平均可达90%以上,准确率高主要是因为人脸识别的登录 / 支付等应用通常都是通过直视镜头的方式进行判断的,所以角度比较固定,对其特征的要求不太高。
然而如果需要进一步对动态图片进行复杂的辨认,那简单 CNN 模型的准确率很可能会急速下滑。
1 def getModel():
2 model=keras.models.Sequential()
3 # 32个卷积核形状为 5*5,激活函数为 relu
4 model.add(layers.Conv2D(filters=32,kernel_size=(5,5),activation='relu'))
5 # 池化层,大小2*2
6 model.add(layers.MaxPool2D())
7 # 64个卷积核形状为 5*5,激活函数为 relu
8 model.add(layers.Conv2D(filters=64,kernel_size=(5,5),activation='relu'))
9 # 池化层,大小2*2
10 model.add(layers.MaxPool2D())
11 # 128个卷积核形状为 5*5,激活函数为 relu
12 model.add(layers.Conv2D(filters=128,kernel_size=(5,5),activation='relu'))
13 # 池化层,大小2*2
14 model.add(layers.MaxPool2D())
15 # 多层 MLP dropout 为 0.5
16 model.add(layers.Flatten())
17 model.add(layers.Dense(8192,activation='relu'))
18 model.add(layers.Dropout(rate=0.5))
19 model.add(layers.Dense(1024,activation='relu'))
20 model.add(layers.Dropout(rate=0.5))
21 model.add(layers.Dense(128,activation='relu'))
22 model.add(layers.Dropout(rate=0.5))
23 model.add(layers.Dense(60,activation='relu'))
24 model.add(layers.Dense(10,activation='sigmoid'))
25 return model
26
27 def run(generator, model, steps_per_epoch=10,epochs=10):
28 # 生成训练模型,学习率为0.003
29 model.compile(optimizer=optimizers.Adam(0.001),
30 loss=losses.binary_crossentropy,
31 metrics=['accuracy'])
32 # 分批训练
33 model.fit(generator,steps_per_epoch=steps_per_epoch,epochs=epochs)
34
35 if __name__=='__main__':
36 # 视频转换后的文件路径
37 path='E://Python_Projects/ANN/venv/pic/'
38 # 增强的训练数据
39 trainDataGenerator=ImageDataGenerator(rescale=1./255,rotation_range=50,
40 width_shift_range=0.3,height_shift_range=0.3,
41 shear_range=0.3,zoom_range=0.3,horizontal_flip=True)
42 train_data=trainDataGenerator.flow_from_directory(path+'train',
43 target_size=(70,50),batch_size=20)
44 # 测试数据
45 testDataGenerator=ImageDataGenerator(rescale=1./255)
46 test_data=testDataGenerator.flow_from_directory(path+'test',
47 target_size=(70,50),batch_size=50)
48 # 数据训练与测试
49 model = getModel()
50 run(train_data,model,steps_per_epoch=50)
51 print('-------------------------test------------------------')
52 run(test_data,model,epochs=1)
运行结果

损失函数

以上所介绍的例子,都属于小型的 CNN 模型,每次创建 model 时都需要手动建立多个 layer ,随着计算的复杂程度越来越高,需要建立的 layer 也会越来越多,这其实是一件令人烦心的事。
事实上,当遇上大型的数据集时更多情况下会使用预训练模型来解决,下面将为大家介绍。
四、使用 VGG16 框架预训练模型
4.1? 预训练模型
小型的 CNN 模型可以通过训练数据去精准化模型的权重,然而对于一些大型的数据集这可能需要耗费大量的资源,为了可以使模型发挥更高效的作用,于是业内产生预训练模型这个概念。实际上这是把大量的数据集在网络上完成训练,并把模型保存,通过云端模式,进行模型共享。只要原始数据集足够大,那么经过训练后的模型就可以有效地作为通用模型。
Keras 中早已经包含 VGG16、VGG19、Inception V3、ResNet 50 、AlexNet 等多个模型架构。
完成预训练的模型可以通过 save_model 函数进行保存
1 @keras_export('keras.models.save_model')
2 def save_model(model, filepath, overwrite=True,
3 include_optimizer=True, save_format=None,
4 signatures=None, options=None,
5 save_traces=True):
- model:? 需要保存的模型对象
- filepath:? str 类型,需要保存的路径
- overwrite:? bool 类型,是否覆盖原文件
- include_optimizer:bool 类型,是否包含 optimizer 优化器数据
- save_format:[ ’ tf ’ , ’ h5 ’ ] 二者选一,保存方式,tf 用于 tensorflow 2.x,h5 用于 tensorflow 1.x
- singatures:使用 SavedModel 保存的签名细节。当save_formate 为 ’ tf ’ 时可用。请参阅’ signatures '参数“ tf.saved_model。
- options:tf.saved_model.SaveOptions 对象,仅适用于SavedModel格式,该对象指定保存到 SavedModel 的选项。
- save_traces:bool 类型,默认值为 True,仅适用于SavedModel 格式,SavedModel将存储每个层的函数轨迹。禁用此功能将减少序列化时间和减少文件大小,但它要求所有自定义层/模型实现一个 ’ get_config() ’ 方法。
需要加载时可以通过 load_model 函数进行获取
1 def load_model(filepath, custom_objects=None,
2 compile=True, options=None):
- filepath:? str 类型,model 保存的路径
- custom_objects:自定义类或函数在反序列化时所映射名称。
- compile: bool 类型,是否在加载之后编译模型。
- options:可选的 tf.saved_model,加载 save_model 时从 SavedModel 所保存的 options 。
4.2 VGG 16 模型介绍
VGG 16 是成熟的预训练模型之一, 它是由 Karen Simonyan 和 Andrew Zisserman 在 2014 年开发的框架,它包含了16 层 ,如下图。当中包含了多层的卷积、池化层,完成CNN训练后拉直,最后通过3层全连接输出。 默认情况下,VGG 16 训练集中包含了1300,000 张图片,验证集中包含了 50,000 张图片,输出 1000 类的物品,因此VGG 16 在卷积层保存了大量已通过训练的向量特征,如果需要添加自定义类别时可以通过自定义的全连接层进行类别的概率分配。
前面曾经介绍过,全连接层会把所有数据看作同一维度处理,这样会把原有图像的三维数据中所包含的关联标志,相距像素,位置等重要信息丢弃。而 VGG 模型的思路正是通过 CNN 的优势,通过足够多的训练集,在卷积层收集大量图片的位置、像素等向量特征,初始化模型时把训练过的特征直接加载。用户可以使用默认的全连接层,也可通过自定义的全连接层,根据物品的出现的概率进行类别分配。

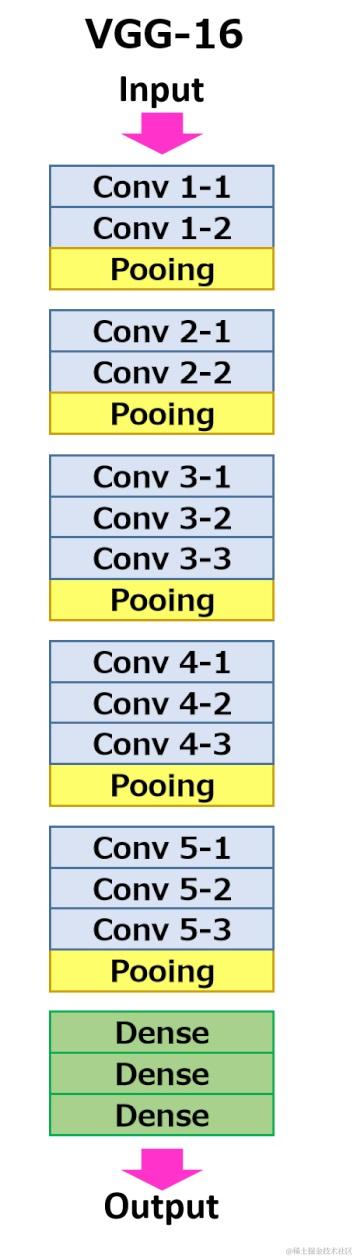
VGG16 函数
1 @keras_export('keras.applications.vgg16.VGG16', 'keras.applications.VGG16')
2 def VGG16( include_top=True, weights='imagenet',
3 input_tensor=None, input_shape=None,
4 pooling=None, classes=1000,
5 classifier_activation='softmax'):
- include_top:bool 类型,默认为 True,指定模型最后是否包含三层全连接分类器。如果使用自定义的全连接层时,可以设置为 False
- weights:str 类型,[ ’ None’ , 'imagenet ’ ] 二选一,默认为 imagenet ,指定初始化时加载模型的权重。None 表示随机初始化。
- input_tensor:输入到网络中的 keras 张量格式。
- input_shape:输入到网络中的图像张量的形状。这个参数完全是可选的,如果不传入这个参数,那么网络能够处理任意形状的输入。
- pooling:str 类型,[ ’ None ’ , ’ avg ’ , ’ max ’ ] 三选一,avg 代表使用平均池化,max 代表使用最在池化,’ None ’ 代表输出将为四维张量的输出
- classes:int 类型,表示输出的分类,默认1000类,只在 include_top 为 True, 而且未指定 weights 为参数时有效
- classifier_activation: str 类型,激活函数,默认使用 softmax
4.3 使用 VGG16 进行特征提取
下面以 kaggle 竞赛的?DogVSCat 为例介绍一下 VGG16 的使用方式。先从 kaggle 官网?https://www.kaggle.com/muhammadshahzadkhan/dogvscat?下载图片资源,当中包括了 train 图片 2000 张,validation 图片 1000 张,test 图片 1000 张。?
建立 VGG 16 模型,把 include_top 设置为False 以使用自定义全连接,把 input_shape 输入张量设置 (256,256,3)。
为了在训练时不影响卷积层,必须先把 VGG16 的 trainable 设置为 False。
利用 ImageDataGenerator 增加训练数据集,对卷积层输出数据使用 Flatten?拉直,经过二层全连接,使用 Adam 优化器 sigmoid 激活函数输出。
测试数据集准确率可达到 93% 以上
1 def getModel():
2 # 获取 VGG16 模型,把 include_top 设置为 False,使用自定义全连接
3 conv_base=applications.VGG16(weights='imagenet',include_top=False,
4 input_shape=(256,256,3))
5 # 把 trainable 属性设计为 False,冻结卷积层权重
6 conv_base.trainable=False
7 # 新建模型,使用 VGG16 的卷积层,拉直后,自定义二层全连接层
8 model=models.Sequential()
9 model.add(conv_base)
10 model.add(layers.Flatten())
11 model.add(layers.Dense(256,activation='relu'))
12 model.add(layers.Dense(1,activation='sigmoid'))
13 # 显示模型层特征
14 model.summary()
15 return model
16
17 def test():
18 # 猫狗图路径
19 path='E://Python_Projects/data_test/DogVSCatLit/'
20 # 训练数据集使用增强数据
21 train=ImageDataGenerator(rescale=1./255,rotation_range=20,
22 width_shift_range=0.2,height_shift_range=0.2,
23 shear_range=0.2,zoom_range=0.2,
24 horizontal_flip=True,fill_mode='nearest')
25 # 验证数据集和测试数据使用原数据
26 test=ImageDataGenerator(rescale=1./255)
27 # 图片统一转换成 256*256,每批 50个
28 trainData=train.flow_from_directory(path+'train',target_size=(256,256),
29 batch_size=50,class_mode='binary')
30 validationData=test.flow_from_directory(path+'validation',target_size=(256,256),
31 batch_size=50,class_mode='binary')
32 testData=test.flow_from_directory(path+'test',target_size=(256,256),
33 batch_size=50,class_mode='binary')
34 # 获取模型
35 model=getModel()
36 # 使用 adam 优化器,binary_crossentropy 二进制交叉熵损失函数
37 model.compile(optimizer=optimizers.Adam(3e-4),
38 loss=losses.binary_crossentropy,
39 metrics=['acc'])
40 # 日志记录
41 callback=callbacks.TensorBoard(log_dir='logs/091902')
42 # 训练数据 2000 个,每批 50 个,所以 steps_per_epoch 训练批次为 40
43 # 验证数据 1000 个,每批 50 个,所以 validation_steps 训练批次为 20
44 # 重复训练 30 次
45 model.fit(trainData,steps_per_epoch=40,epochs=30,
46 validation_data=validationData,validation_steps=20,
47 callbacks=callback)
48 print('---------------------------------test---------------------------------------')
49 # 测试结果
50 model.fit(testData,steps_per_epoch=20)
51
52 if __name__=='__main__':
53 test()
模型层次图

运行结果

tensorboard

4.4 微调 VGG16 模型
前一节的例子训练时会将 VGG16 卷积层的模型完全冻结,是为了避免在数据训练期间,错误信息对已有的模型造成影响。而事实上应用更广泛的是对模型的最顶的卷积层进行微调,使模型更匹配新输入的数据。但注意微调一般只针对最顶层的抽象模型,而不适合用于底层,因为这样做对模型影响过大从而造成误判。
下面的例子就是对顶层的卷积层 [ ‘block5_conv1’,‘block5_conv2’,‘block5_conv3’ ,‘block5_pool’] 进行解冻,加入微调训练,输出后拉直进入三层全连接层,防止过拟合加入 dropout 层,丢失率设置为 0.3,运行后测试数据的准确率上升到 95%以上。
1 def getModel():
2 # 获取 VGG16 模型,把 include_top 设置为 False,使用自定义全连接, 平均值池化
3 conv_base=applications.VGG16(weights='imagenet',include_top=False,
4 input_shape=(256,256,3))
5 # 把 trainable 属性设计为 False,冻结卷积层权重
6 conv_base.trainable=True
7 # 把顶层卷积层进行解冻
8 layer_names=['block5_conv1','block5_conv2','block5_conv3','block5_pool']
9 for layer in conv_base.layers:
10 if layer.name in layer_names:
11 layer.trainable = True
12 else:
13 layer.trainable=False
14
15 # 新建模型,使用 VGG16 的卷积层,拉直后,自定义三层全连接层
16 model=models.Sequential()
17 model.add(conv_base)
18 model.add(layers.Flatten())
19 model.add(layers.Dense(256,activation='relu'))
20 model.add(layers.Dropout(0.3))
21 model.add(layers.Dense(1,activation='sigmoid'))
22 # 显示模型层特征
23 model.summary()
24 return model
25
26 def test():
27 # 猫狗图路径
28 path='E://Python_Projects/data_test/DogVSCatLit/'
29 # 训练数据集使用增强数据
30 train=ImageDataGenerator(rescale=1./255,rotation_range=20,
31 width_shift_range=0.2,height_shift_range=0.2,
32 shear_range=0.2,zoom_range=0.2,
33 horizontal_flip=True,fill_mode='nearest')
34 # 验证数据集和测试数据使用原数据
35 test=ImageDataGenerator(rescale=1./255)
36 # 图片统一转换成 256*256,每批 50个
37 trainData=train.flow_from_directory(path+'train',target_size=(256,256),
38 batch_size=50,class_mode='binary')
39 validationData=test.flow_from_directory(path+'validation',target_size=(256,256),
40 batch_size=50,class_mode='binary')
41 testData=test.flow_from_directory(path+'test',target_size=(256,256),
42 batch_size=50,class_mode='binary')
43 # 获取模型
44 model=getModel()
45 # 使用 adam 优化器,binary_crossentropy 二进制交叉熵损失函数
46 model.compile(optimizer=optimizers.Adam(3e-4),
47 loss=losses.binary_crossentropy,
48 metrics=['acc'])
49 # 日志记录
50 callback=callbacks.TensorBoard(log_dir='logs/091903')
51 # 训练数据 2000 个,每批 50 个,所以 steps_per_epoch 训练批次为 40
52 # 验证数据 1000 个,每批 50 个,所以 validation_steps 训练批次为 20
53 # 重复训练 30 次
54 model.fit(trainData,steps_per_epoch=40,epochs=30,
55 validation_data=validationData,validation_steps=20,
56 callbacks=callback)
57 print('---------------------------------test---------------------------------------')
58 # 测试结果
59 model.fit(testData,steps_per_epoch=20)
60
61 if __name__=='__main__':
62 test()
运行结果

五、CNN 中间激活层输出图
下面的例子尝试对各层输出图进行可视化,你会发现一个很有趣的现象,在底层的通道都是比较形象地反应图片的特征,越往顶层,其特征越抽象,甚至有些输出是空白的,这证明在顶层里越来越多特征经过滤波器后的输出是空白,这表示输入图像中找不到这些滤波器的特征。
原始图

首先读取图片,把图片升维成?(1,224,224,3),对其除以 255.0 进行标准化。建立VGG16,根据名称获取层输出,对图片进行运算后获取层输出。
最后随机显示每层的 25 张 channel 的输出图。
1 def getImg():
2 # 测试图片
3 path = 'E://Python_Projects/data_test/DogVSCatLit/train/dogs/dog.444.jpg'
4 img=image.load_img(path,target_size=(224,224,3))
5 # 转换成数组
6 img=image.img_to_array(img)
7 # 升维成(1,224,224,3)
8 img=np.expand_dims(img,axis=0)
9 # RGB最大值为255,输入前进行标准化
10 img/=255.
11 return img
12
13 def getLayerOutput(layername):
14 # 使用 VGG16 模型
15 vgg16=applications.VGG16(weights='imagenet')
16 # 获取层
17 layer=vgg16.get_layer(layername)
18 # 获取层输出
19 layerout=layer.output
20 # 以 vgg16 建立 model,获取输出层
21 model=models.Model(inputs=vgg16.input,outputs=layerout)
22 # 输入图片运算后返回层输出
23 outputs=model.predict(getImg())
24 return outputs
25
26 def display(layername):
27 # 获取 axes
28 fig, axes = plt.subplots(5, 5, figsize=(50, 50))
29 # 获取层输出
30 outputs=getLayerOutput(layername)
31 for ax in axes.ravel():
32 # 随机抽取 25 个 channel 进行显示
33 high=len(outputs[0,0,0])
34 index=np.random.randint(low=0,high=high)
35 ax.imshow(outputs[0,:,:,index])
36 plt.show()
37
38 if __name__=='__main__':
39 display('block5_pool')
尝试对 block1_pool,block2_pool,block3_pool,block4_pool,block5_pool?层执行获取输出图,根据运行结果可以看到,越往顶层,其输出图越抽象。而空白的输出图则代表在输入图片中找不到该滤波器的特征。
运行结果
block1_pool  | block2_pool 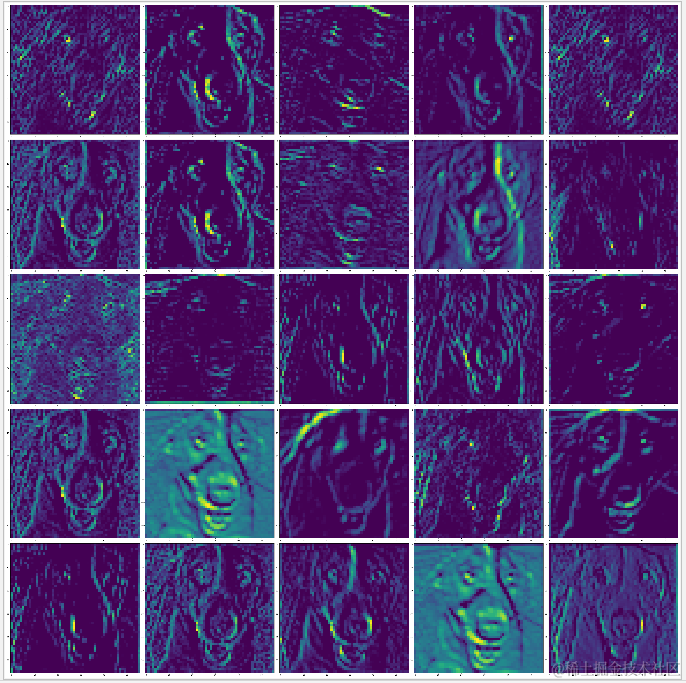 |
|---|---|
block3_pool 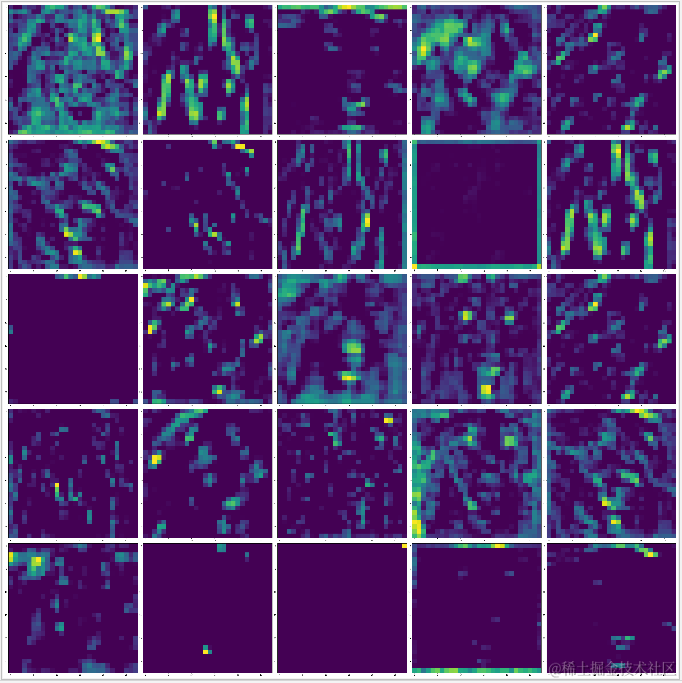 | block4_pool  |
block5_pool  |
六、CNN 滤波器的可视化输出
要观察 CNN 滤波器最简单的方法就是使用梯度上升来实现,首先以某一层的输出值作为损失函数,使用 backend.gradients 函数绑定输出值对输入值的梯度,注意gradients?默认返回一个列表,取第一个元素即可。然后输入随机图片,利用梯度上升的原理,重复调用?backend.function?函数进行累加,让滤波器的输出响应值实现最大化,此时观察让滤波器有最大输出值的图案。
1 def getfilter(layername,filterindex):
2 # tensorflow2.x 以上版本需要手动关闭 eager execution
3 tf.compat.v1.disable_eager_execution()
4 # 使用 VGG16 模型
5 vgg16=applications.vgg16.VGG16(include_top=False)
6 # 根据层名称获取层
7 layer=vgg16.get_layer(layername)
8 # 以该层的某个过滤器输出作为 loss
9 loss = K.mean(layer.output[:, :, :, filterindex])
10 # 建立 loss与 vgg16 输入特征的梯度
11 # 注意 gradients 返回一个列表,因此只取其第一个元素
12 grads=K.gradients(loss,vgg16.input)[0]
13 # grads 的更新系数,将梯度除以 L2 范数来标准化,加上 1e-4 保证分母非 0
14 grads/=(K.sqrt(K.mean(K.square(grads)))+1e-5)
15 # 绑定输入参数 VGG16 input 值与输出参数 loss,grads
16 func=K.function([vgg16.input],[loss,grads])
17 # 随机生成输入图片
18 image=np.random.random((1,50,50,3))
19 # 根据梯度上升法重复运行 50 次,将滤波器的输出值实现最大化
20 for i in range(50):
21 loss,grads=func(image)
22 image+=grads*0.9
23 return image
24
25 #把数据转化为 RGB 格式
26 def display(x):
27 x-=x.mean()
28 x/=(x.std()+1e-5)
29 x*=0.1
30 x+=0.5
31 x=np.clip(x,0,1)
32 x*=255
33 x=np.clip(x, 0, 255).astype('uint8')
34 return x
35
36 if __name__=='__main__':
37 # 5行5格
38 fig,axes=plt.subplots(5,5,figsize=(50,50))
39 filterindex=0
40 for ax in axes.ravel():
41 #过滤器从0开始显示前25个
42 data=getfilter('block1_conv2',filterindex)
43 #因为 display 输出为 (1,50,50,3),输出只用第一个
44 a = display(data[0])
45 filterindex+=1
46 ax.imshow(a)
47 plt.show()
分别显示 block1_conv2,block2_conv2,block3_conv2,block4_conv2,block5_conv2?的过滤器
运行结果
block1_conv2 | block2_conv2 |
|---|---|
block3_conv2  | block4_conv2 |
block5_conv2 |
每一组滤波器包含一层同类型的特征,block1 可能只包含简单的颜色,轮廓等特征,block2?开始出现纹理特征,block3?开始演变成复杂的图案,随着层的逐步加深,滤波器会变得越来越复杂。
七、CNN 热力图
经过前两个章节的例子可以看到 CNN?的滤波器是逐层复杂化的,每个滤波器都包含了一个特征,越高层的滤波器特征越为得复杂。而图片经过滤波器后的输出图代表这个图片中是否存在着该特征,随着高层滤波器的特征越来越复杂化,经过高层的滤波器输出后,很多输出特征图都变成空白,这是因为在图片中找不到该特征。
结合上述内容,这一节可尝试使用类似的方法,查看图片是根据哪些特征去判断输出值的。
1 def getImg():
2 # 读取用于测试的图片
3 path='C://Users/Leslie/Desktop/CNN/01.jpg'
4 img=image.load_img(path,target_size=(224,224,3))
5 # 转换成数组
6 img=image.img_to_array(img)
7 # 升维成(1,224,224,3)
8 img=np.expand_dims(img,axis=0)
9 return img
10
11 def getResult():
12 # 执行计算
13 result=vgg16.predict(getImg())
14 # 查看所占比例最高的前5个图片类型
15 print(decode_predictions(result,top=5))
16 # 打印出最高可能性类型的索引
17 arg=np.argmax(result)
18 print(arg)
19
20 if __name__=='__main__':
21 getResult()

运行结果如下,斑马的可能性最大,占比 88%,属于第 340?类
[[(‘n02391049’, ‘zebra’, 0.886605), (‘n01704323’, ‘triceratops’, 0.09896327), (‘n02422699’, ‘impala’, 0.0035573354), (‘n02423022’, ‘gazelle’, 0.0028548033), (‘n02422106’, ‘hartebeest’, 0.002379738)]]
340
然后根据运算后的索引 340,以 vgg16.output [ : , 340 ] 输出值为?loss,第5层 block5_conv3?为参数求梯度。然后输入测试图片,把测试图片的?block5_conv3?输出值乘以梯度得出热力图。再把热力图以降维去负求均值的方式转化为图片进行显示,最后把热力图与原图进行合并。
1 def excute():
2 # tensorflow2.x 以上版本需要手动关闭 eager execution
3 disable_eager_execution()
4 # 实例化 VGG16
5 vgg16 = applications.vgg16.VGG16(weights='imagenet')
6 # 以 VGG16 最大输出值作为 loss,斑马的索引 340
7 loss=vgg16.output[:,340]
8 # 以 block5_conv3 层输出值作为参数
9 layeroutput=vgg16.get_layer('block5_conv3').output
10 # 求两者的梯度,K.gradients 默认返回数组,取第一个元素即可
11 gradient=K.gradients(loss,layeroutput)[0]
12 func=K.function(vgg16.input,[gradient,layeroutput,loss])
13 grad,layeroutput,loss=func(getImg())
14 # 把输入值乘以梯度值得出热力图
15 for i in range(512):
16 layeroutput[0,:,:,i]*=grad[0,:,:,i]
17 # 把热力图转化为二维数据显示
18 heat=convert(layeroutput[0])
19 plt.matshow(heat)
20 plt.show()
21 return heat
22
23 def applyheat(heat):
24 # 读入原图
25 path = 'C://Users/Leslie/Desktop/CNN/01.jpg'
26 image=cv2.imread(path)
27 # 把热力图大小转换成原图大小
28 heat=cv2.resize(heat,(image.shape[1],image.shape[0]))
29 # 把热力图转换成 RGB 格式
30 heat=np.uint8(255*heat)
31 # 热力图与原图合并
32 heat=cv2.applyColorMap(heat,cv2.COLORMAP_JET)
33 image=heat*0.5+image
34 # 保存合并后的图
35 cv2.imwrite('C://Users/Leslie/Desktop/CNN/03.jpg',image)
36
37 #对热力图进行处理,先降维,再去负,求占比,把数值控制在 0~1 之间
38 def convert(x):
39 # 对最后一个维度进行降维
40 x=np.mean(x,axis=-1)
41 # 去除负值
42 x=np.maximum(x,0)
43 # 求比
44 x/=np.max(x)
45 return x
46
47 if __name__=='__main__':
48 heat=excute()
49 applyheat(heat)
热力图
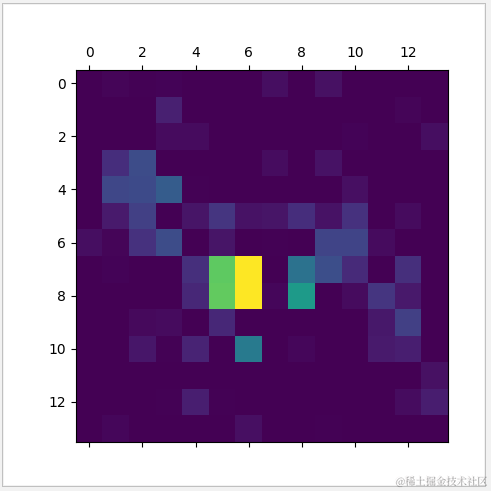
合并原图后,可见斑纹,轮廓对辨别斑马类型的影响比较大。

本章总结
本文主要介绍 CNN?卷积神经网络的基本原理和基础概念,卷积层与池化层的作用,并以常用的 VGG16?为例子,介绍常用模型的使用方式。把中间激活层输出图,滤波器,热力图等进行可视化分析,让大家进一步了解 CNN?的结构特征。文章内容受偶像 Keras?之父?Francois?博客和?Antonio?论文的启发很深。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《手把手教你》系列练习篇之3-python+ selenium自动化测试(详细教程)
- 【设计模式--行为型--中介者模式】
- 探索C语言的世界:分支循环语句全攻略
- 运筹优化 | 模拟退火求解旅行商问题 | Python实现
- Nginx Location 规则解析:深入剖析 Location 优先级匹配机制
- 基于eNSP的多VLAN配置
- 实践:修改正式站表名
- 34534
- 【问题解决】cannot import name ‘circle‘ from ‘skimage.draw‘ 问题解决
- 谈谈spring的生命周期