生产环境_Spark处理轨迹中跨越本初子午线的经度列
发布时间:2023年12月18日
????????使用spark处理数据集,解决gis轨迹点在地图上跨本初子午线的问题,这个问题很复杂,先补充一版我写的
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.types.{StringType, StructField, StructType}
// by_20231215
// 作者:https://blog.csdn.net/qq_52128187?type=blog
object lon_benchuziwuxian {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Parent_child_v3").setMaster("local[1]")
val sc = new SparkContext(conf)
val spark = SparkSession.builder.appName("Parent_child_v3").getOrCreate()
import spark.implicits._
// 数据
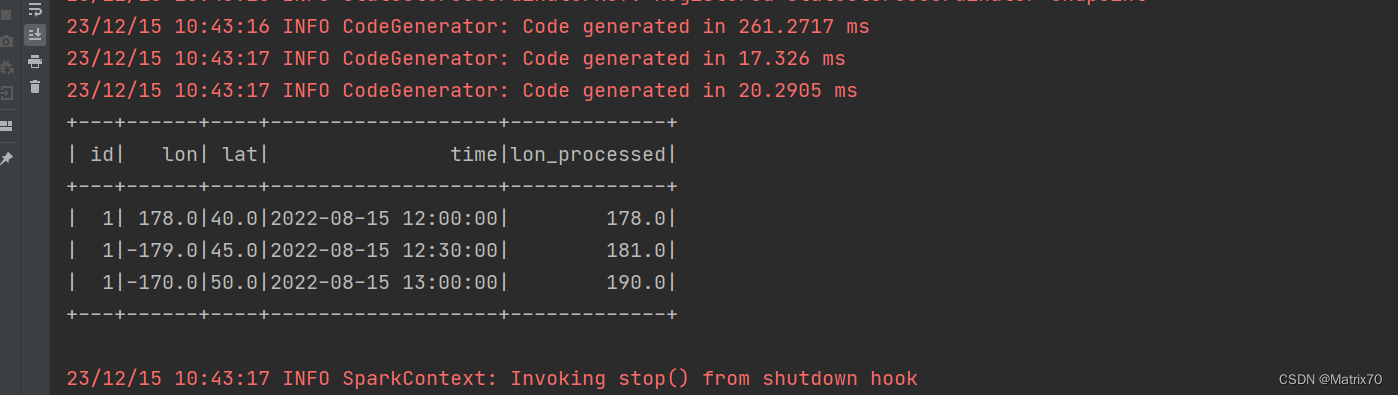
val data = Seq(
(1, 178.0, 40.0, "2022-08-15 12:00:00"),
(1, -179.0, 45.0, "2022-08-15 12:30:00"),
(1, -170.0, 50.0, "2022-08-15 13:00:00")
)
// 数据集的schema
val columns = Seq("id", "lon", "lat", "time")
val trajDataFrame = data.toDF(columns: _*)
// 处理跨越本初子午线的经度
val processedDataFrame = trajDataFrame.withColumn("lon_processed",
when(col("lon") < 0, col("lon") + 360).otherwise(col("lon")))
processedDataFrame.show()
// // 处理跨越本初子午线的经度
// val processedDataFrame = trajDataFrame.withColumn("lon_processed",
// when(col("lon") < 0, col("lon") + 360).otherwise(col("lon")))
//
// // 按id和时间排序
// val sortedDataFrame = processedDataFrame.orderBy("id", "time")
//
// // 调整经度以避免跨越本初子午线
// val adjustedDataFrame = sortedDataFrame.withColumn("lon_adjusted",
// when(abs(col("lon_processed") - lag("lon_processed", 1).over(Window.partitionBy("id").orderBy("time"))) > 180,
// when(col("lon_processed") > lag("lon_processed", 1).over(Window.partitionBy("id").orderBy("time")), col("lon_processed") - 360)
// .otherwise(col("lon_processed") + 360)
// ).otherwise(col("lon_processed"))
// )
//
// // 将经纬度点按时间形成一条轨迹字符串
// val trajStringDF = adjustedDataFrame.groupBy("id").agg(collect_list(struct("lon_adjusted", "lat", "time")).as("trajectory"))
//
// trajStringDF.show(false)
}
}
文章来源:https://blog.csdn.net/qq_52128187/article/details/135011630
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 龙芯+RT-Thread+LVGL实战笔记(27)——超声波测距
- Project软件使用指南:六个关键功能助力项目成功
- Build Reporting Apps for .NET 8 FastReport .NET 2024.1
- LVGL 主题
- 安全防御之身份鉴别技术
- MyBatis 连环 20 问,你能答对几个?
- 算法基础之区间覆盖
- C++算法学习心得六.回溯算法(1)
- c语言的初始学习(练习)
- 欲擒故纵,来回推拉,撩拨心房