视频物体对象追踪AI技术模型——Tracking Any Object Amodally
发布时间:2023年12月26日
项目地址:https://tao-amodal.github.io
论文:https://arxiv.org/abs/2312.12433
GitHub:GitHub - WesleyHsieh0806/TAO-Amodal: Official Code for Tracking Any Object Amodally
AIGC专区:aigc
更多消息:AI人工智能行业动态,aigc应用领域资讯
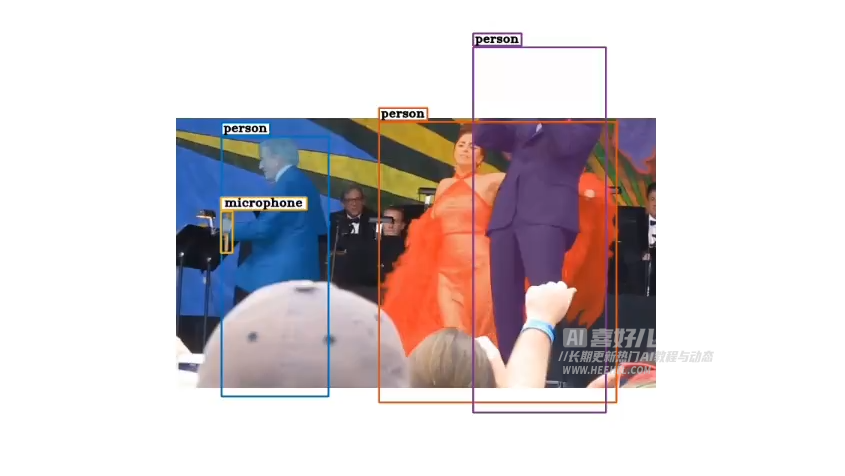
卡内基梅隆大学和丰田研究所合作开发的项目旨在使AI能够在物体被部分遮挡或不完全可见的情况下理解其完整结构。该技术使计算机能够像人一样,即使只能看到物体的一部分,也能识别并追踪其整体。这对于自动驾驶车辆尤为重要,能够在复杂环境中准确识别和追踪部分被遮挡的行人或车辆,提高驾驶的安全性和可靠性。
这个项目能大幅提升计算机视觉系统的智能,让它们在处理遮挡物体时更加像人类,从而在自动驾驶、视频监控等领域发挥更大的作用。

为提高物体追踪技术他们专门设计了一个数据集——TAO-Amodal:
- 这数据集涵盖了大量视频序列,包含各种被遮挡或部分可见的物体,并提供详细标注信息。
- 这样的数据集使得AI能够更全面地理解和追踪那些我们只能看到部分的物体。
- 数据集规模庞大,包括880个多样的类别,覆盖数千个视频序列。
- 注释类型方面,数据集提供了完全不可见、部分出框和被遮挡物体的amodal(非模态)和modal(模态)边界框标注。
- TAO-Amodal 数据集的重点在于评估当前追踪器在遮挡推理方面的能力,通过实现对任何物体的Amodal感知(Amodal perception)来进行追踪。这使得模型能够更好地处理被遮挡的物体,提高追踪的鲁棒性。

Amodal Expander?插件:
- 该项目还引入了一个名为“Amodal Expander”的轻量级插件模块,旨在增强物体追踪器的性能。
- 传统的 Modal 追踪器主要关注物体可见部分,表现良好当物体完全显露在视野中。然而,当物体被遮挡或部分不可见时,Modal 追踪器可能失去准确性。
- Amodal 追踪器:相较之下,Amodal 追踪器能够理解和推断物体的完整形状,即使物体的一部分被遮挡或不完全可见。这意味着在复杂的视觉环境中,Amodal 追踪器能够更准确地追踪物体。
Amodal Expander?插件的主要功能是将标准的 Modal 追踪器转换为 Amodal 追踪器,通过在少量视频序列上微调追踪器实现。微调后的追踪器能够更有效地处理部分遮挡或不完全可见的物体,从而在追踪这些物体时更加准确和可靠。
在对 TAO-Amodal 数据集进行的测试中,该技术在检测和追踪被遮挡物体方面分别取得了3.3%和1.6%的改进。特别值得注意的是,在人物追踪方面,性能相较于现有的模态追踪技术提高了2倍。
文章来源:https://blog.csdn.net/heehelcom/article/details/135228526
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!